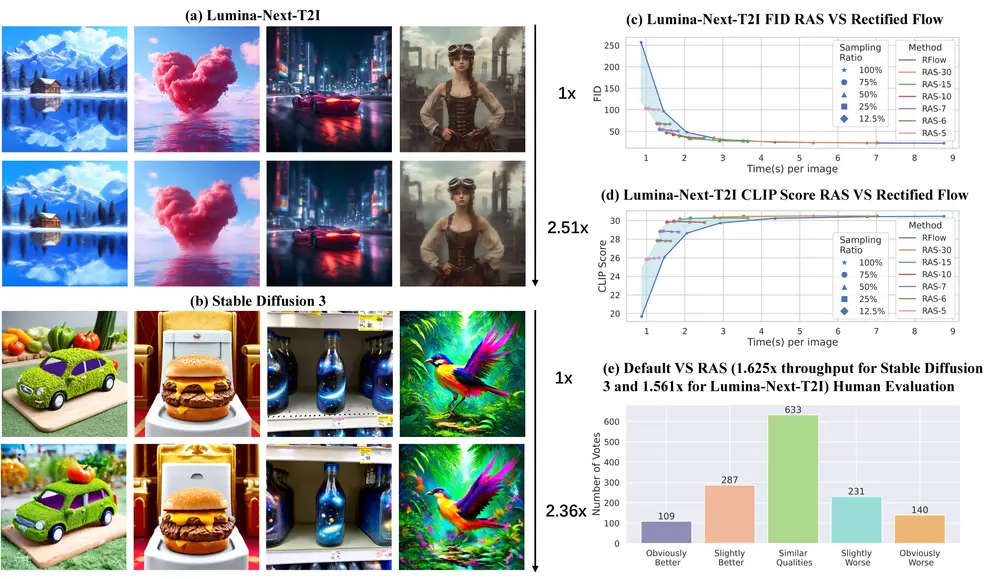
微软研究院推出新型采样策略RAS:用于加速DiT架构模型的生成过程新加坡国立大学和微软研究院的研究团队提出了一种全新的扩散采样策略——区域自适应采样 (Region-Adaptive Sampling, RAS)。这是首个允许采样率在图像不同区域间动态变化的扩散采样...新技术# RAS# 区域自适应采样# 微软研究院1年前05480
新型视频生成模型Loong:基于自回归大语言模型,能够生成长达一分钟的连贯、内容丰富的视频香港大学和字节跳动的研究人员推出新型视频生成模型Loong,它基于自回归大语言模型(LLMs),能够生成长达一分钟的连贯、内容丰富的视频。这在视频生成领域是一个挑战,因为视频通常包含大量的帧,每帧都需...新技术# Loong# 自回归大语言模型2年前05470
Adobe推出全新图像编辑方法TurboEdit:实现基于文本的即时图像编辑Adobe Research推出了一种全新的图像编辑方法TurboEdit,它能够实现基于文本的即时图像编辑,它利用了所谓的"少步骤扩散模型"(few-step diffusion models),在...新技术# TurboEdit# 图像编辑2年前05470
DaVinci Resolve 20正式推出,包含超过100项新功能和新的AI工具Blackmagic Design正式发布了DaVinci Resolve 20,这是其广受欢迎的视频编辑软件的最新版本。此次更新不仅带来了超过100项新功能,更引入了多项先进的AI工具,让视频创作变...早报# Blackmagic Design# DaVinci Resolve# 视频剪辑1年前05460
创新框架FeatUp:提高深度学习模型中图像特征的空间分辨率,而不会损失原有的语义信息来自麻省理工、微软、Adobe和谷歌的研究团队推出创新框架FeatUp,它能够提高深度学习模型中图像特征的空间分辨率,而不会损失原有的语义信息。在计算机视觉领域,深度学习模型通常会从图像中提取特征,这...新技术# FeatUp# 深度模型2年前05440
Perplexity 的 AI 语音助手登陆 iOS,为 iPhone 和 iPad 用户带来了全新的对话式交互体验Perplexity 的 AI 语音助手现已正式登陆 iOS 平台,为 iPhone 和 iPad 用户带来了全新的对话式交互体验。这一更新使苹果用户能够通过 Perplexity 应用完成一系列任务...早报# AI 语音助手# Perplexity12个月前05420
谷歌推出基于 Gemini 的新文本嵌入模型Gemini Embedding谷歌于周五在其 Gemini 开发者 API 中添加了一款新的实验性文本“嵌入”模型——Gemini Embedding。这款新型嵌入模型旨在将文本输入(如单词和短语)转化为数值表示,即嵌入(embe...早报# Gemini# Gemini Embedding# 文本嵌入模型1年前05420
新型图像生成框架ControlAR:根据空间控制信息生成可控制的高质量图像华中科技大学信息与通信学院、香港大学计算机科学系和vivo AI 实验室的研究人员推出新型图像生成框架ControlAR,它能够根据空间控制信息生成可控制的高质量图像。简单来说,ControlAR能够...新技术# ControlAR# 图像生成框架2年前05420
Grammarly 推出九大人机协作写作智能体,可预测论文评分Grammarly 今日正式推出九个全新人工智能智能体(AI Agents),集成于其“AI 原生写作界面”中,旨在为学生和教育工作者提供更智能、更精准的写作支持。 这些智能体覆盖从构思、写作到反馈的...早报# Grammarly# 写作智能体8个月前05410
3D场景编辑框架TIP-Editor来自腾讯人工智能实验室、中山大学的研究人员推出3D场景编辑框架TIP-Editor,它允许用户不仅通过文本提示,还通过图像提示来精确地编辑现有的基于3D高斯散射(GS)的辐射场。TIP-Editor的...新技术# 3D场景编辑# TIP-Editor2年前05410
AI动画生成框架Keyframer:利用GPT4生成动画来自苹果的研究人员推出一款利用大语言模型(LLMs)生成动画的框架Keyframer,它利用大语言模型(LLMs)来帮助设计师通过自然语言描述来创建动画。 论文地址 Keyframer的主要功能包括从...新技术# AI动画# CSS动画# Keyframer2年前05400
BootPIG:零样本个性化图像生成来自Salesforce的研究人员提出了一种新架构BootPIG,旨在实现零样本个性化图像生成。该架构基于预训练的文本到图像模型Stable Diffusion,通过引入参考图像来指导生成的对象外观...新技术# BootPIG# Stable Diffusion2年前05400