辅导作业逼疯了多少家长?AI教育助手VideoTutor帮你轻松搞定家里有中小学生的家长一定深有体会:孩子的日常学习辅导是个难题。 不是不想帮,而是很多时候我们自己也讲不明白,或者讲了孩子听不懂。面对一道数学题,常常是越辅导越崩溃。 在这样的背景下,AI 技术的进步确...教程# VideoTutor# 教育助手11个月前06110
AI视频生成系统Direct-a-Video:像导演拍摄视频一样生成视频Direct-a-Video是一个AI视频生成系统,该系统允许用户独立地为一个或多个对象和/或相机运动指定运动,就像导演拍摄视频一样。 项目主页 开发者提出了一种简单而有效的策略,用于分别控制对象运动...新技术# AI视频生成# Direct-a-Video2年前06110
微软旗下的AI编程助手GitHub Copilot引入新限制,对高级AI模型的使用收费微软旗下的AI编程助手GitHub Copilot,正在引入新的限制措施,并对高级AI模型的使用收费。这一变化可能会让部分用户感到意外,但也反映了AI模型计算成本上升的现实。 新限制与收费细节 1. ...早报# GitHub Copilot# 微软1年前06090
图像编辑新方法DICE:用于改进离散扩散模型在可控编辑任务中的性能罗格斯大学、麻省理工学院-IBM Watson AI 实验室、谷歌 DeepMind、NEC 美国实验室、纽约大学、 沃尔玛全球科技公司、澳大利亚国立大学和 麻省理工学院阿灵顿分校的研究人员推出图像编...新技术# DICE# 图像编辑2年前06090
限量版不够玩?自己DIY一个Crybaby哭娃手办,分分钟刷爆朋友圈在潮玩文化席卷全球的浪潮中,泡泡玛特(Pop Mart)旗下的 Crybaby 哭娃手办 以其独特的疗愈系形象和可爱情感表达,迅速成为年轻世代和明星圈的时尚新宠。随着数字创作风潮的兴起,Molly F...教程# Crybaby# 哭娃# 泡泡玛特12个月前06080
开源自回归图像生成模型Open-MAGVIT2 腾讯ARC 实验室、清华大学和南京大学推出开源自回归图像生成模型Open-MAGVIT2 ,它致力于推广自回归视觉生成模型的使用。自回归模型是一种人工智能技术,可以根据一系列给定的数据点预测下一个数据...新技术# Open-MAGVIT22年前06080
人类偏好优化技术NCPPO:改善文生图模型,使其生成的图像更加符合人类的偏好俄罗斯国家研究型高等经济大学的研究人员推出新方法NCPPO,它用于改善文本到图像的扩散模型(Diffusion Models),使其生成的图像更加符合人类的偏好。扩散模型是一种生成模型,它们通过逐步去...新技术# NCPPO# 人类偏好# 文生图模型2年前06080
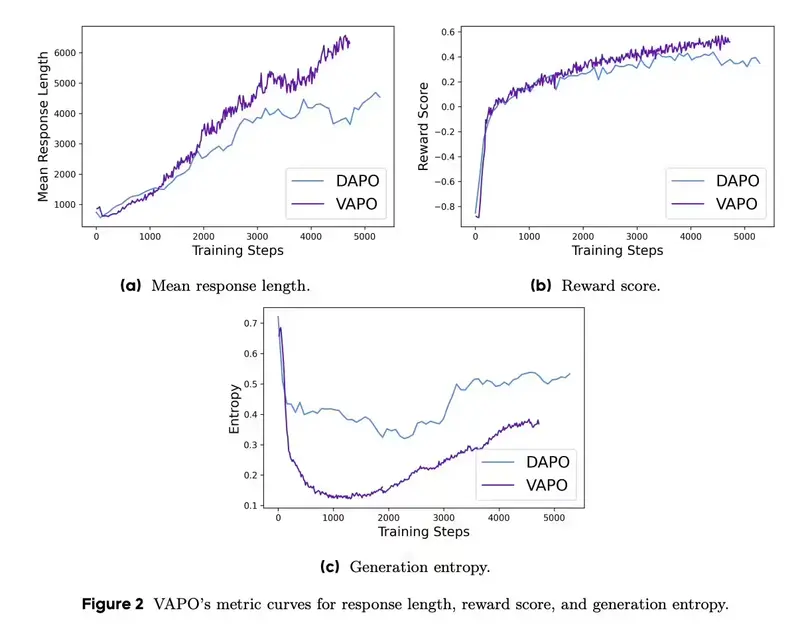
字节跳动推出VAPO框架:让大语言模型在复杂推理任务中更高效字节跳动Seed研究团队发布了一项名为 VAPO 的强化学习训练框架。这一框架专为提升大语言模型(LLM)在复杂、冗长任务中的推理能力而设计,特别是在数学推理和长链推理(Long Chain-of-T...新技术# VAPO# 大语言模型# 字节跳动1年前06070
基于偏好学习的奖励模型VADER:让模型更有效地学习如何生成符合特定要求的视频卡内基梅隆大学的研究人员推出奖励模型(一种基于偏好学习的方法)VADER,来指导视频生成过程,从而让模型更有效地学习如何生成符合特定要求的视频。例如,你想要生成一段描述“一只穿着红色外套、拿着雪球的浣...新技术# VADER# 奖励模型2年前06070
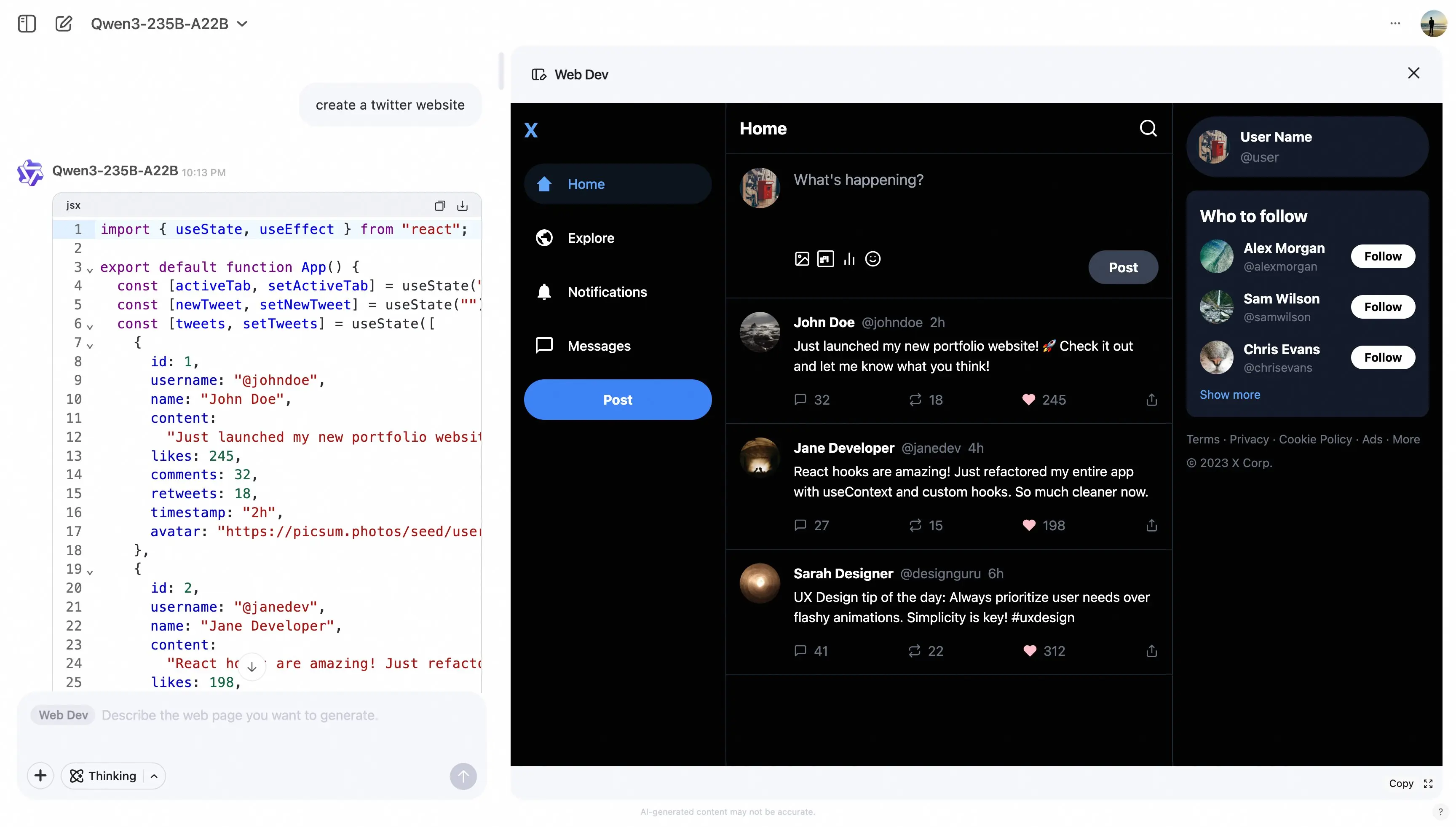
阿里Qwen Chat上线Web Dev功能,用一句话生成完整网页Qwen官网新增Web Dev功能,让网页开发变得前所未有的简单。 类似于Claude的Artifacts和Gemini的Canvas,Qwen Web Dev可以直接渲染网页,并结合Qwen 3强大...早报# Qwen Chat# Web Dev# 阿里巴巴11个月前06060
高效稀疏注意力机制 SpargeAttn:加速大模型的推理过程,同时不损失模型性能清华大学和加州大学伯克利分校的研究人员推出高效稀疏注意力机制 SpargeAttn,旨在加速大模型的推理过程,同时不损失模型性能。注意力机制在现代深度学习模型中扮演着重要角色,但由于其计算复杂度与序列...新技术# SpargeAttn# 加州大学伯克利分校# 清华大学1年前06060
深度估算模型Depth Anything:让照片自动感知空间距离来自香港大学、TikTok、浙江实验室、浙江大学的研究人员推出了深度估算模型Depth Anything,它是一个用于单目深度估计(Monocular Depth Estimation, MDE)的实...新技术# Depth Anything# 深度估算模型2年前06050