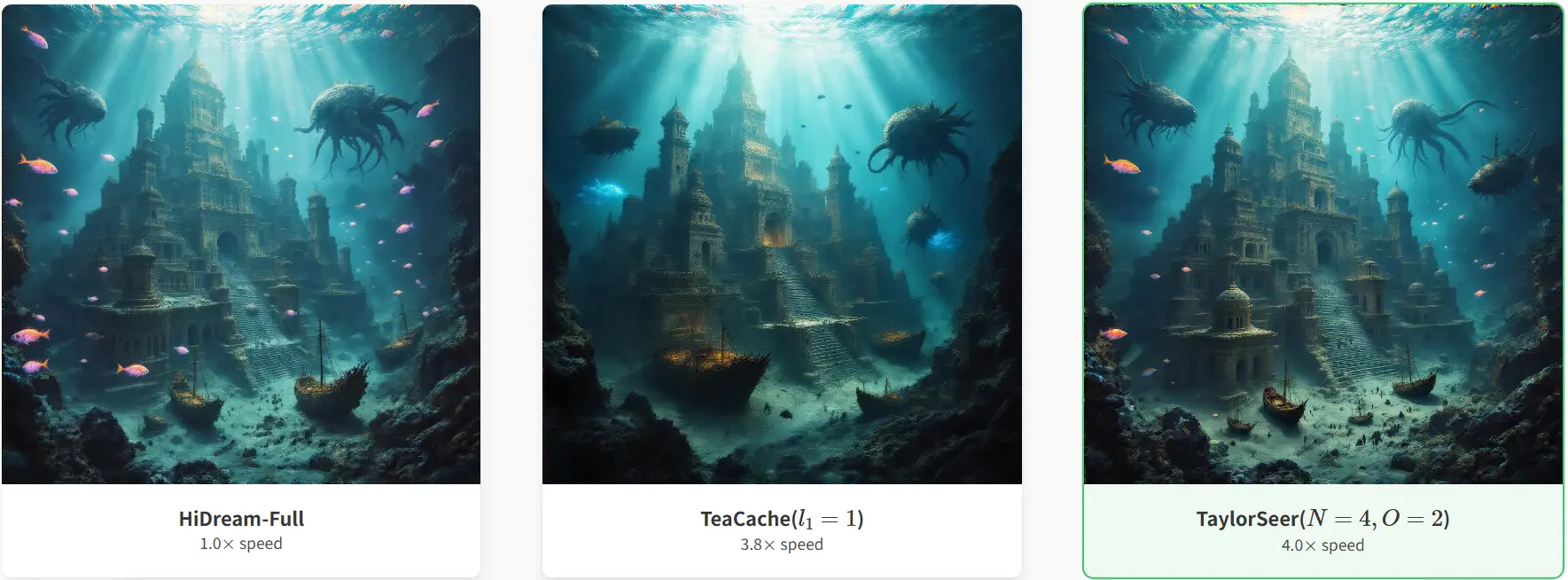
加速DiT架构模型推理速度的新方法TaylorSeer:通过预测未来时间步的特征来加速扩散模型上海交通大学、山东大学、电子科技大学和香港科技大学的研究人员推出加速DiT架构模型推理速度的新方法TaylorSeer,扩散模型在图像和视频生成任务中表现出色,但其计算需求较高,限制了实时应用的可行性...新技术# TaylorSeer7个月前02060
Radial Attention:用“物理直觉”突破长视频生成的计算瓶颈近年来,视频生成模型在质量上取得了显著进步。然而,一个根本性挑战始终存在: 时序维度的引入,使计算成本呈指数级增长。 标准扩散模型中的稠密注意力机制(Dense Attention)在处理长视频时面临...新技术# Radial Attention8个月前02610
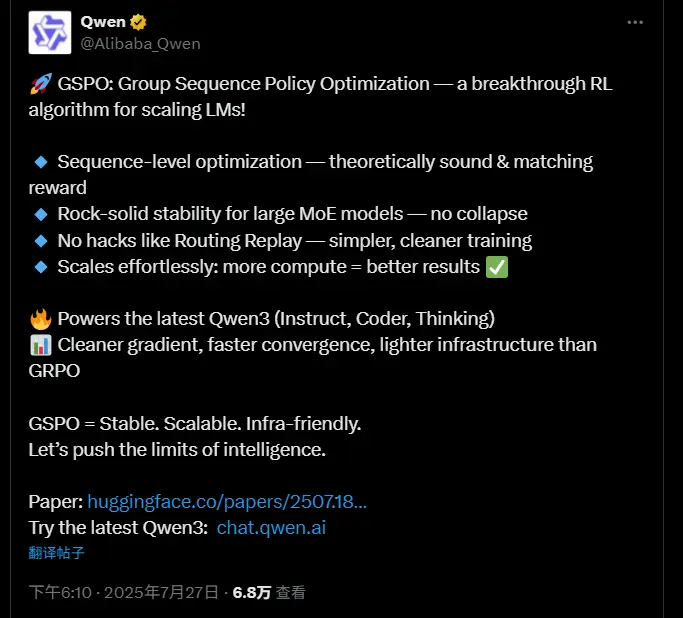
阿里Qwen项目组推出新型强化学习算法GSPO:用于训练最新 Qwen3 模型阿里Qwen项目组推出新型强化学习算法 Group Sequence Policy Optimization (GSPO),用于训练大型语言模型(LLMs)。与以往基于单个标记(token)重要性比率...新技术# GSPO# Qwen38个月前03730
如何让AI“不生成某物”?UBC研究人员提出轻量级负提示新方案VSF在文本到图像生成中,如何让模型“不生成某样东西”——例如“一只没有翅膀的鸟”或“一辆没有轮子的自行车”——始终是一个挑战。尽管正向提示可以引导生成内容,但负提示(negative prompt)的执行...新技术# VSF# 负面提示8个月前01860
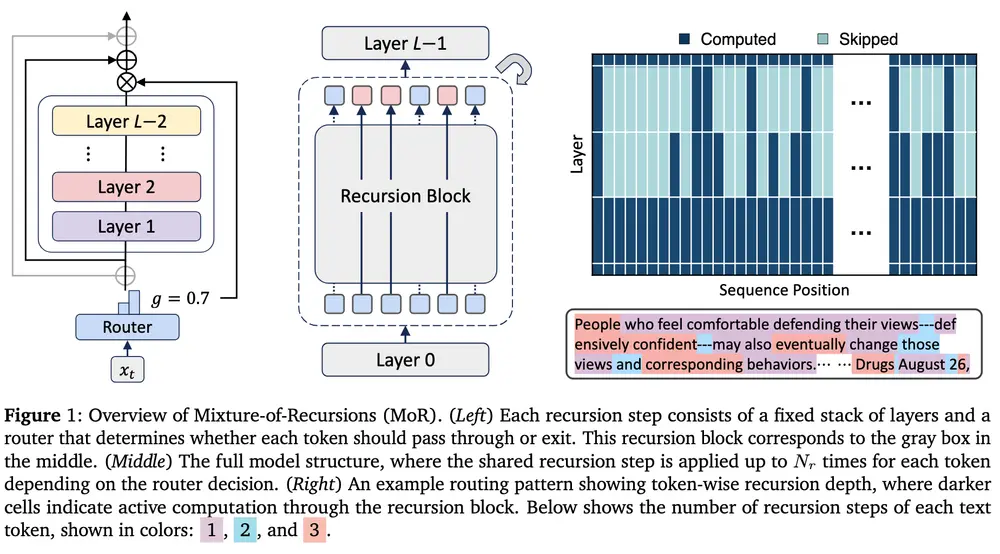
混合递归(MoR):用“动态思考”提升大模型推理效率在大模型追求极致规模的浪潮中,一种新的架构正试图从“智能调度”而非“堆叠参数”的角度,重新定义效率。 由 KAIST AI 与 Mila 联合提出的新框架——混合递归(Mixture-of-Recur...新技术# MoR# 混合递归8个月前0980
Snap Research 推出 Zero-Shot Dynamic Concept:无需微调,即可实现视频级动态个性化Snap Research 发布了一项名为 Zero-Shot Dynamic Concept 的新方法,为文本到视频生成模型中的动态概念个性化提供了全新的解决方案。该技术基于网格化 LoRA 架构...新技术# Snap Research# Zero-Shot Dynamic Concept8个月前01120
首尔大学研究团队提出推理加速框架 RALU:无需训练的混合分辨率采样,加速DIT架构模型推理最高达7倍DIT架构模型凭借其卓越的可扩展性,正逐步取代传统的 U-Net 架构,成为高保真图像与视频生成的主流模型。然而,其高昂的计算成本严重制约了在移动端、实时应用和大规模部署中的实用性。 为解决这一瓶颈...新技术# DiT架构模型# RALU# 首尔大学8个月前01120
索尼与韩国科学技术院联合推出 DesignLab:一种全新的AI驱动幻灯片优化框架对大多数人而言,制作一份美观、专业、信息清晰的演示文稿是一项令人头疼的任务。 排版混乱、配色突兀、字体不协调——这些问题并非源于内容不足,而是设计决策的复杂性超出了非专业人士的能力范围。 尽管已有不少...新技术# DesignLab# PPT8个月前03090
Gemini 2.5 实现对话式图像分割,用语言精准“圈出”图像中的目标AI在视觉理解领域正不断突破边界。从最初的物体检测,到像素级语义分割,再到开放词汇识别,AI 对图像的理解能力持续进化。如今,谷歌 Gemini 2.5 带来了一个更具交互性的能力——对话式图像分割...新技术# Gemini 2.5# 图像分割8个月前03540
CSD-VAR:从一张图中分离内容与风格的新方法高通AI研究和MovianAI的研究人员推出新方法CSD-VAR,用于从单张图像中分离内容(content)和风格(style),即内容风格分解(Content-Style Decomposition...新技术# CSD-VAR8个月前02210
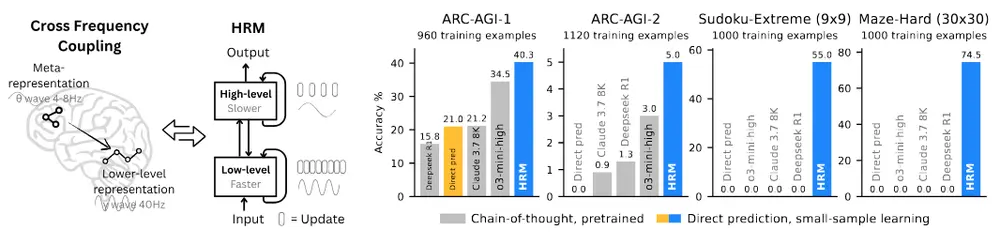
一种更接近人类思维的推理模型架构HRM在AI领域,“推理”始终是衡量智能水平的核心指标。真正的推理,不只是回答问题,而是设计并执行通向目标的复杂行动序列——就像人在解一道数独时,会先观察整体格局,再逐步填入数字;在走迷宫时,会先判断大致方...新技术# HRM# 推理模型架构8个月前02610
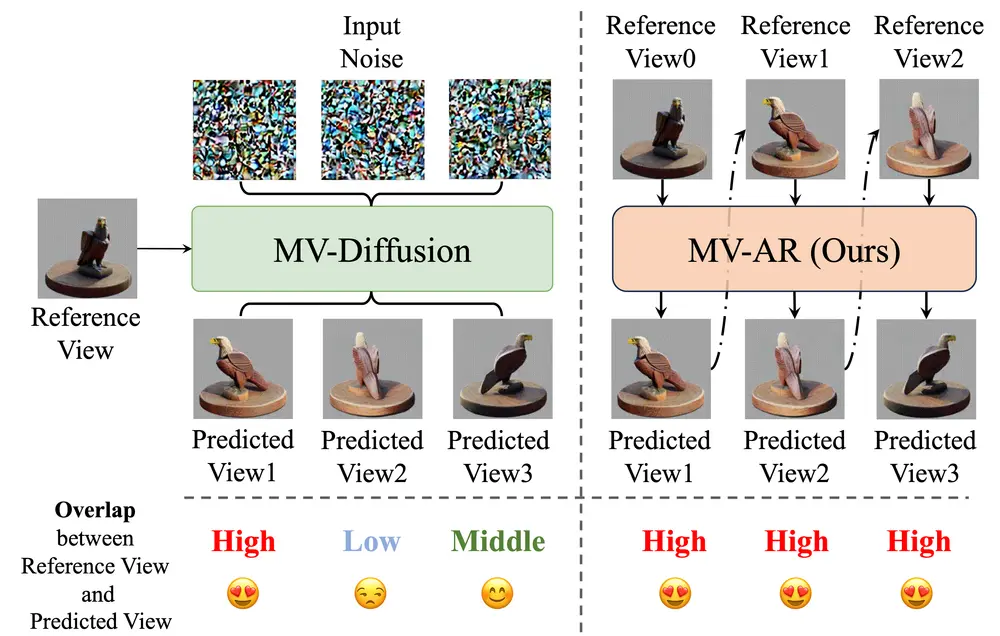
自回归生成多视图图像方法 MVAR:从人类指令(如文本、参考图像和几何形状)生成多视角一致的图像北京大学医学技术研究所、百度视觉、北京大学未来技术学院生物医学工程系、北京大学国家生物医学影像中心和清华大学的研究人员开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程...新技术# MVAR# 多视图8个月前01640