
AI在视觉理解领域正不断突破边界。从最初的物体检测,到像素级语义分割,再到开放词汇识别,AI 对图像的理解能力持续进化。如今,谷歌 Gemini 2.5 带来了一个更具交互性的能力——对话式图像分割(Conversational Image Segmentation),让人类可以用自然语言直接与图像内容进行深度交互。

这项技术的核心,不只是识别“汽车”或“狗”,而是理解如“最远的那辆汽车”或“拿着伞、没戴帽子的人”这类包含上下文、关系与逻辑的复杂描述。它与学术界所称的“指代表达式分割”(Referring Expression Segmentation)高度相关,标志着视觉语言模型在空间与语义理解上的新高度。
什么是对话式图像分割?
传统图像分割模型依赖预定义类别(如“猫”、“桌子”)或简单标签进行识别。而对话式图像分割允许用户通过自然语言描述,精准定位图像中符合复杂条件的区域,并返回对应的像素级掩码(mask)。
这意味着,你可以像和助手对话一样,告诉 Gemini:
“请框出画面中最左边那朵凋谢的花。”
“标出所有没有系安全带的乘客。”
“分割出写着‘有机’字样的商品标签。”
Gemini 能理解这些指令中的空间关系、属性比较、抽象概念、文本内容与逻辑条件,并准确完成分割任务。
五大核心查询能力
Gemini 2.5 支持多种复杂语义的分割请求,显著扩展了视觉理解的应用边界:
1. 物体关系理解
基于物体之间的空间或逻辑关系进行识别:
- “拿着雨伞的人”
- “从左边数第三个书架”
- “停在红色汽车后面的那辆自行车”
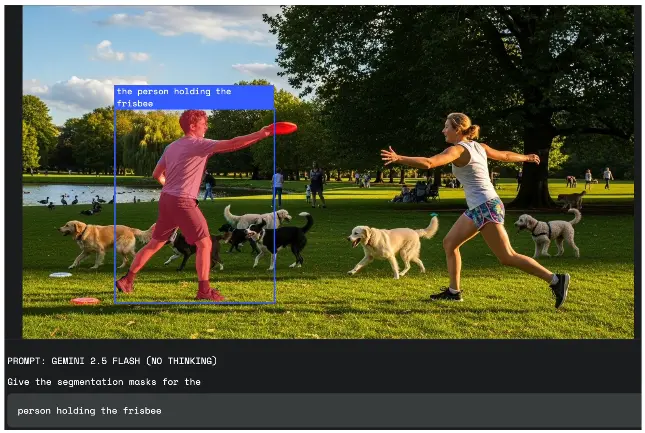
2. 条件与逻辑判断
支持包含“是/否”、“如果/则”、“排除”等逻辑的查询:
- “未佩戴安全帽的工人”
- “菜单上标注为‘素食’的食物”
- “画面中除了门以外的所有物体”
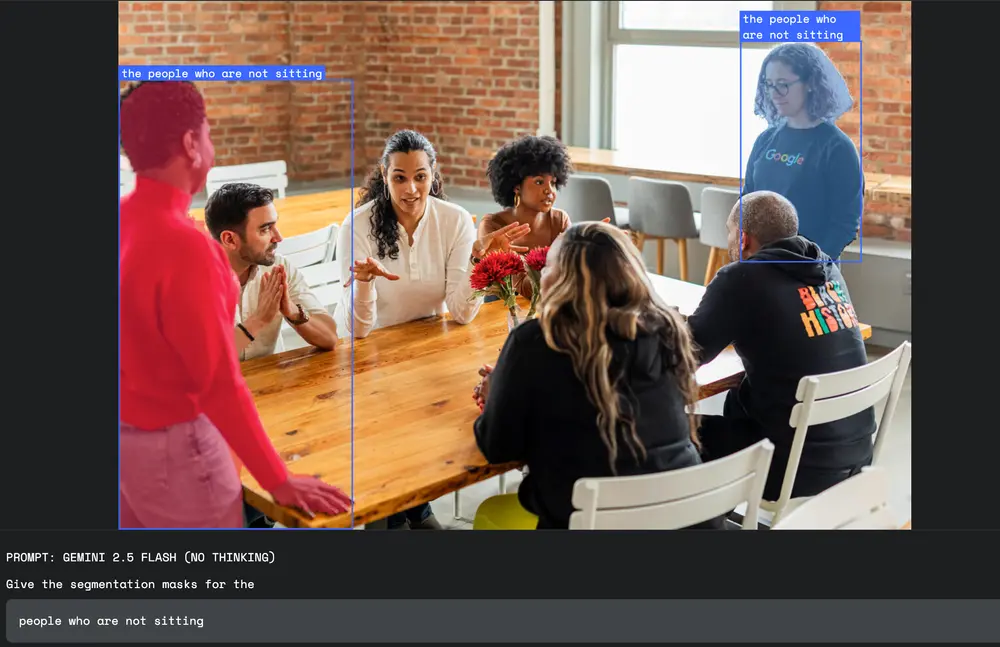
3. 抽象概念识别
借助模型的世界知识,识别难以通过外观直接定义的抽象状态:
- “看起来最混乱的桌面”
- “有损坏痕迹的墙壁”
- “显得最有希望的区域”(如灾后救援场景)
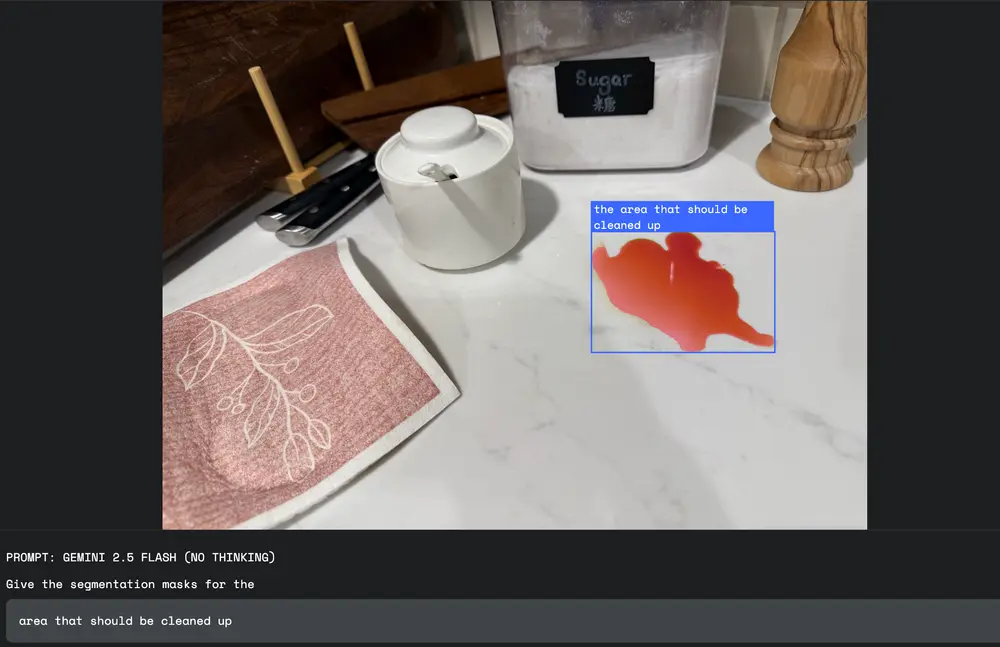
4. 图像内文本识别与定位
结合 OCR 能力,根据图像中的文字内容进行分割:
- “标有‘20% off’的促销标签”
- “包装上写着‘Gluten Free’的产品”

5. 多语言标签支持
支持多种语言的输入描述,适用于全球化应用:
- 中文:“最右边那扇窗户”
- 西班牙语:“el libro abierto”
- 日语:“開いている傘”
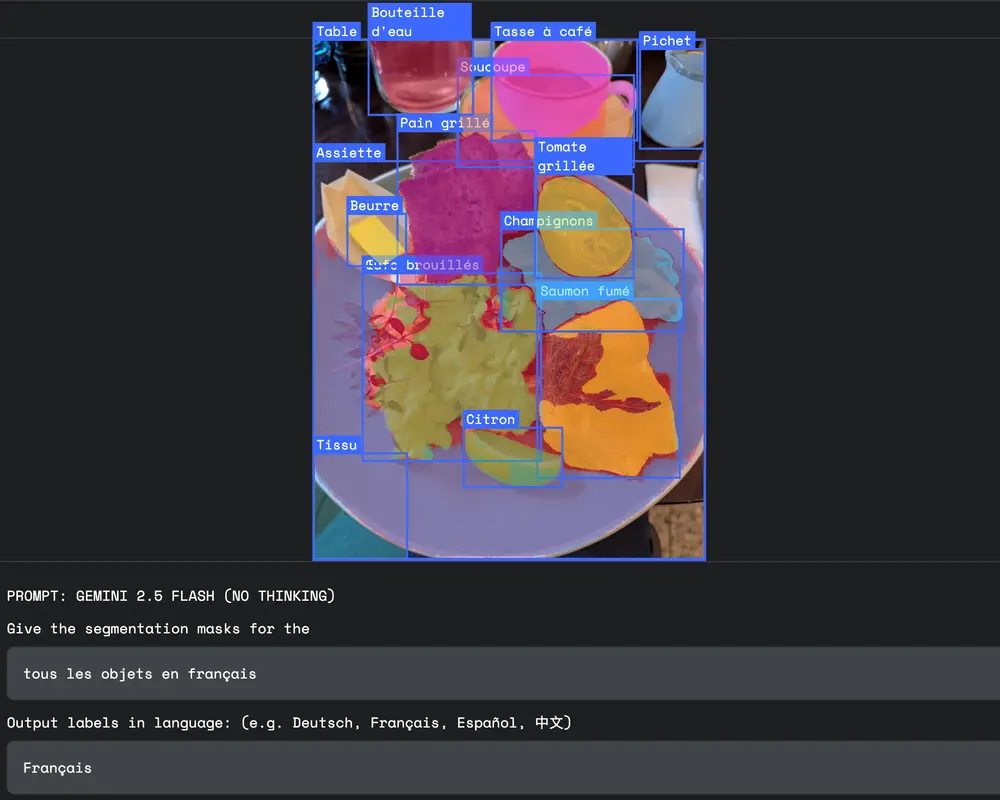
实际应用场景
这一能力正在多个领域催生新的工作方式和产品形态。
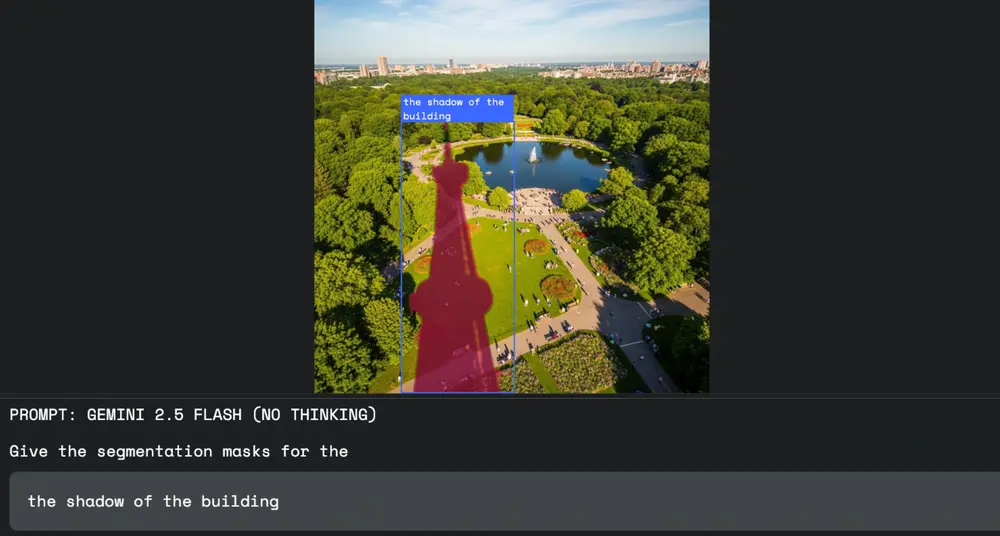
🎨 创意设计:交互式媒体编辑
设计师不再需要手动套索或魔棒工具选择复杂区域。只需输入“选中建筑物在地面上的影子”或“圈出所有穿蓝色衣服的人”,即可快速完成选区,极大提升图像/视频编辑效率。
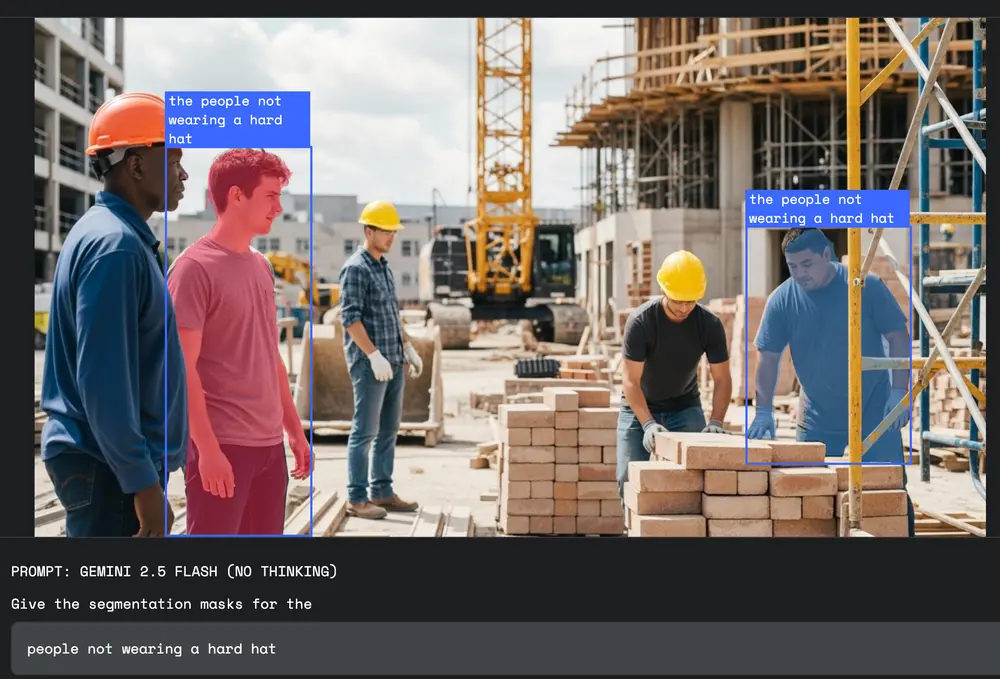
🛡️ 安全监控:智能合规检测
在工厂、工地等场景中,可通过提示词实现自动化合规检查:
“高亮显示未佩戴安全帽或未穿反光背心的员工”
系统可自动生成精确掩码,用于告警或记录,提升安全管理效率。
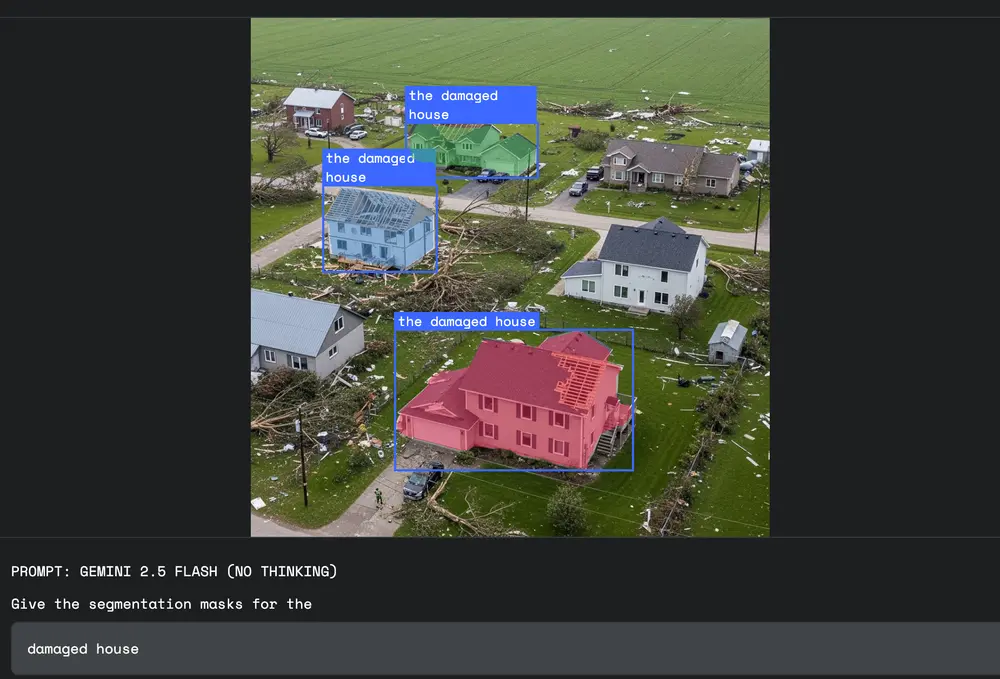
🏦 保险理赔:自动化损害评估
理算员可直接请求:
“分割出因冰雹受损的屋顶区域”
Gemini 结合其对“天气损坏”外观特征的理解(如凹陷、漆面剥落),可区分真实损伤与普通反光或污渍,辅助快速定损。
🛒 零售与电商:智能商品识别
在货架图像中,通过描述文字标签或商品状态进行精准定位:
“找出所有标有‘新品’且价格低于100元的商品”
对开发者的意义
- 无需训练专用模型
开发者无需收集数据、标注样本或训练独立的分割模型。只需调用 Gemini API,即可获得强大的分割能力。 - 单一接口,多能力集成
对话式分割、OCR、视觉推理、语言理解等功能统一由 Gemini 2.5 提供,简化技术栈。 - 快速集成,灵活扩展
支持 JSON 输出格式,便于与其他系统对接。适合构建行业定制化应用,如医疗影像标注、工业质检、AR交互等。
如何开始使用?
推荐使用以下配置以获得最佳效果:
Give the segmentation masks for the objects.
Output a JSON list of segmentation masks where each entry contains the 2D bounding box in the key "box_2d", the segmentation mask in key "mask", and the text label in the key "label".
Use descriptive labels.推荐最佳实践:
- 使用
gemini-2.5-flash模型(兼顾速度与能力) - 设置
thinkingBudget=0以减少延迟,适用于大多数分割任务 - 请求 JSON 格式输出,便于程序解析
- 提示语尽量清晰、具体,避免歧义
立即体验
- 🔗 交互式演示:访问 Google AI Studio 尝试“空间理解”演示
- 📘 Colab 示例:通过 Google Colab 运行交互式代码示例
- 📚 开发者指南:查阅官方文档,了解 API 详细用法
- 💬 加入社区:参与开发者论坛,与团队和其他开发者交流用例与问题
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











