
Snap Research 发布了一项名为 Zero-Shot Dynamic Concept 的新方法,为文本到视频生成模型中的动态概念个性化提供了全新的解决方案。该技术基于网格化 LoRA 架构,提出了一种无需测试时微调的前馈框架,能够从单个视频中提取特定主体的外观与运动特征,并将其无缝迁移至新场景中,实现高质量的视频编辑与组合。
这项研究标志着个性化视频生成正从“静态对象”迈向“动态行为”的新阶段。

核心能力:让“动作+外观”可迁移
传统个性化生成(如 DreamBooth、Textual Inversion)主要针对静态图像中的物体或人物进行外观学习,且通常需要为每个新主体进行微调。
而 Zero-Shot Dynamic Concept 的目标更进一步:
它要捕捉的是动态的、时空连续的概念——比如一个人挥手的姿势、奔跑的节奏、转身的轨迹,并将这些“动态特征”与外观信息一起,迁移到全新的文本描述场景中。
例如:
- 从一段日常视频中提取某人挥手的动作和穿着;
- 生成该人物在虚拟舞台上、烟花背景中挥手的新视频;
- 动作自然、身份一致,无需重新训练。
这种能力,为虚拟人、数字分身、创意广告等应用打开了新的可能性。
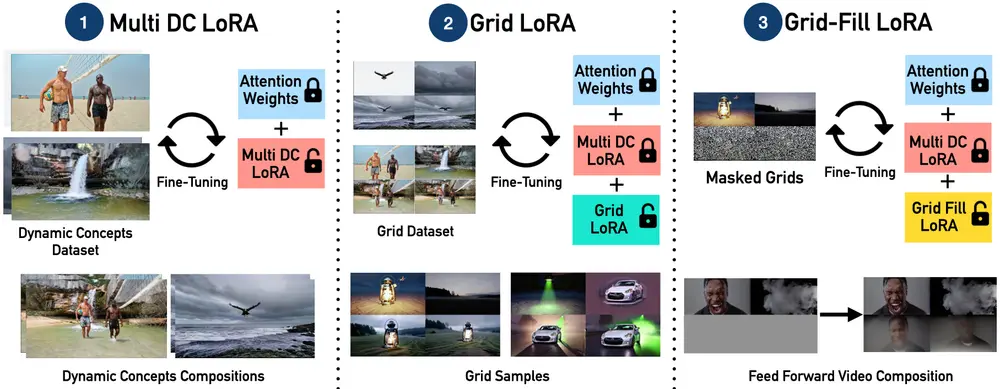
三大核心功能
1. 动态概念个性化(Dynamic Concept Personalization)
系统能从一段输入视频中自动学习特定主体的外观(appearance)与运动模式(motion dynamics),形成一个可复用的“动态概念”。
2. 零样本迁移(Zero-Shot Inference)
与大多数个性化方法不同,该框架无需在推理阶段进行任何优化或微调。所有个性化过程在训练时已完成,推理时仅需一次前馈传递即可生成结果,极大提升了效率。
3. 编辑与组合(Editing & Composition)
支持对生成视频进行:
- 环境编辑:添加灯光、烟雾、火花等视觉效果;
- 多概念组合:将多个动态元素(如两个不同人物的动作)融合到同一场景中,保持各自特征。
技术架构:基于网格的 LoRA 框架
该方法的核心在于一个结构化、模块化的设计,包含三个关键组件:
1. Multi Dynamic Concept (DC) LoRA
作为统一适配器,它负责从输入视频中提取多个动态概念的共性特征,包括身份、姿态、动作节奏等,形成可泛化的动态表征。
2. Grid LoRA
引入 2×2 视频网格结构,通过布局感知模块学习动态概念在空间与时间上的分布规律。这种结构化训练方式,增强了模型对场景布局的理解能力。
3. Grid-Fill LoRA
作为条件填充模块,它可以根据部分观察到的网格内容(如已知某区域有“挥手”动作),推断并补全其余区域,实现目标驱动的编辑与组合。
整个系统在推理阶段通过单次前馈传递完成所有任务,无需迭代优化,显著提升生成效率。
为什么这项技术值得关注?
✅ 高效性:告别测试时优化
传统方法(如 DreamMix、DB-LoRA)在应用新视频时往往需要数十分钟的梯度优化。而 Zero-Shot Dynamic Concept 完全规避了这一过程,真正实现“即输即得”。
✅ 泛化能力强
模型在训练中学习的是“如何提取和迁移动态概念”的通用能力,而非记忆特定实例。因此,它能泛化到未见过的主体、动作和场景。
✅ 保持身份与运动一致性
在编辑和组合过程中,主体的身份特征和动作流畅性得以高度保留,避免了常见的人脸扭曲、动作断裂等问题。
✅ 支持复杂视觉交互
实验结果显示,该方法能处理人物与环境的动态交互,例如:
- 烟雾环绕人物飘动;
- 火花随手势轨迹迸发;
- 多个动态元素在同一场景中协同运动。
性能表现:全面领先
定量评估
在 ID(身份保持)、C-T(语义对齐)、TC(时间连贯性)等指标上,该方法均优于现有主流方法,尤其在复杂动作迁移任务中优势明显。
用户研究
用户调研表明,该方法在以下维度显著优于 DreamMix、DB-LoRA 等基线模型:
- 提示遵循度(Prompt Adherence)
- 动作真实性(Motion Realism)
- 整体视觉偏好(Overall Preference)
定性结果
通过大量生成示例可见,模型能精准复现输入视频中的动作细节,并在新背景下生成连贯、逼真的动态合成视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











