
在大模型追求极致规模的浪潮中,一种新的架构正试图从“智能调度”而非“堆叠参数”的角度,重新定义效率。
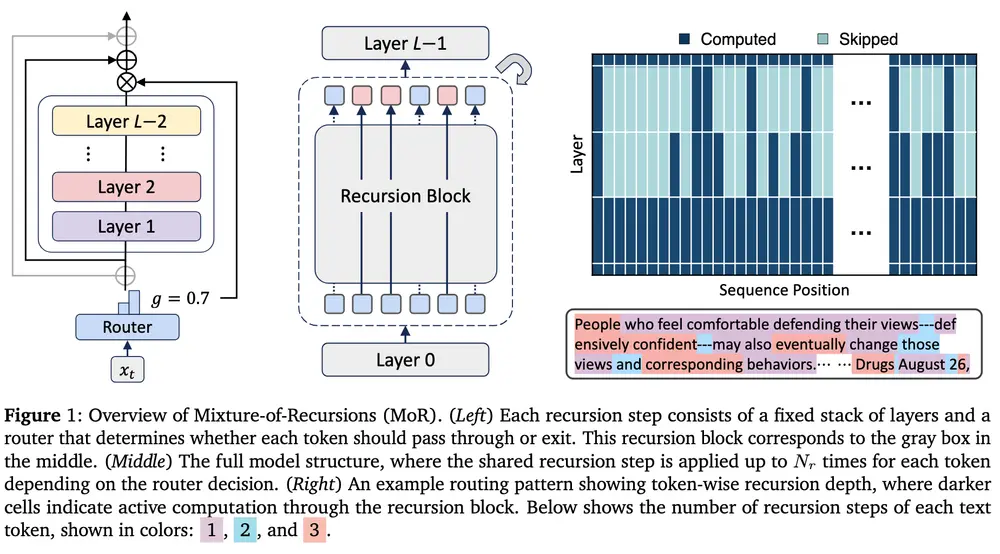
由 KAIST AI 与 Mila 联合提出的新框架——混合递归(Mixture-of-Recursions, MoR),在不增加参数量的前提下,实现了最高 2.06 倍的推理吞吐提升,并显著降低内存占用。这一成果为大模型的轻量化部署与高效推理提供了全新的技术路径。
问题根源:规模与效率的矛盾
当前大语言模型(LLM)的性能提升高度依赖参数规模和计算资源。但随着模型变大,其训练与推理成本急剧上升,对内存、算力和能耗的要求让许多组织望而却步。
因此,研究者们一直在探索两大方向来提升效率:
- 参数共享:减少模型中独立参数的数量,如“层绑定”技术;
- 自适应计算:根据输入复杂度动态分配计算资源,如“提前退出”机制。
然而,如何将两者有效结合,仍是挑战。
MoR 的创新,正是将“参数共享”与“自适应计算”统一于一个框架之下。
MoR 的核心机制:让每个 token 自主决定“想多久”
MoR 基于递归 Transformer 架构构建,其核心思想是:不堆叠大量独立层,而是重复使用一组共享参数层,通过多次“递归”处理来模拟深层网络的效果。
在此基础上,MoR 引入了两个关键组件,实现智能调度:
1. 轻量级路由器:为每个 token 分配“思考深度”
MoR 引入一个轻量级的路由机制,类似于 MoE(Mixture of Experts)中的专家选择,但它路由的不是专家,而是递归深度。
对于每一个输入 token,路由器会判断其复杂程度,并决定该 token 需要经过多少次递归处理。例如:
- 简单词汇(如“的”、“是”):只需 1-2 次递归;
- 复杂逻辑或专业术语:可分配 5 次以上递归。
这实现了真正的按需计算,避免在简单 token 上浪费算力。
2. 逐递归 KV 缓存:精准管理记忆开销
传统 KV 缓存会为所有 token 保存完整的键值状态,导致内存占用随序列长度线性增长,在递归模型中尤为严重。
MoR 提出 “逐递归 KV 缓存” 策略:
- 只为当前递归步骤中仍活跃的 token 保留 KV 状态;
- 已完成处理的 token 状态被释放。
这一机制大幅减少了内存流量和峰值占用,提升了整体吞吐效率。
研究人员在论文中总结道:
“MoR 本质上使模型能够基于每个 token 高效调整其思考深度,统一了参数效率与自适应计算。”
实测表现:更快、更省、更可扩展
研究团队训练了从 1.35亿到17亿参数 的 MoR 模型,并与标准 Transformer 和普通递归模型对比。
训练阶段
- 在相同计算预算下,MoR 模型的平均少样本准确率提升至 43.1%(基线为 42.3%);
- 尽管参数量减少近 50%,性能仍持平甚至反超;
- 训练时间缩短 19%,峰值内存降低 25%。
推理阶段
- 某一 MoR 配置的推理吞吐达到传统基线的 2.06 倍;
- 更低的 KV 缓存占用意味着可支持更长上下文窗口,且能并行处理更多请求。
随着模型规模增长,MoR 的优势愈发明显:
在超过 3.6亿参数 的模型上,MoR 在更低计算预算下即可匹配或超越标准 Transformer 的性能。
企业如何落地?无需从头训练
尽管 MoR 目前基于从头训练的模型验证,但团队指出,“上行训练”(upcycling)现有开源模型是更现实、更具成本效益的路径。
KAIST 博士生、论文合著者 Sangmin Bae 表示:
“在 MoR 的扩展性完全验证前,对已有模型进行适配,可能比从零训练更高效。”
开发者可通过以下方式利用 MoR:
- 将 MoR 架构作为“推理加速插件”集成到现有模型;
- 根据任务复杂度,灵活调整递归深度与路由器策略;
- 在边缘设备或高并发服务中,优先启用深度递归以节省资源。
未来:模态无关的自适应计算
MoR 的设计是模态无关的,这意味着其核心思想不仅适用于文本,还可扩展至:
- 视频:对关键帧进行深度处理,跳过静止片段;
- 音频:在复杂语义段落增加递归,在静音或背景音中减少计算;
- 多模态:动态分配跨模态融合的计算资源。
Bae 表示:
“我们对其在多模态场景中的潜力感到兴奋,因为效率提升在这些领域尤为关键。”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











