阿里巴巴Wanx 团队推出新型多模态生成模型ACE:可以根据文本指令来执行复杂的图像编辑和生成任务阿里巴巴Wanx 团队推出新型多模态生成模型ACE,这个模型的核心功能是处理和生成图像,但它与传统的图像处理工具不同,因为它可以根据文本指令来执行复杂的图像编辑和生成任务。例如,你是一名摄影师,你拍摄...新技术# ACE# 阿里巴巴1年前06670
用于加速DiT模型的训练和推理过程的方法HarmoniCa商汤科技研究院、北京航空航天大学、莫纳什大学和香港科技大学推出一种用于加速DiT模型的训练和推理过程的方法HarmoniCa,通过基于Step-Wise去噪训练(SDT)和图像错误代理引导目标(IEP...新技术# DiT模型# HarmoniCa1年前05360
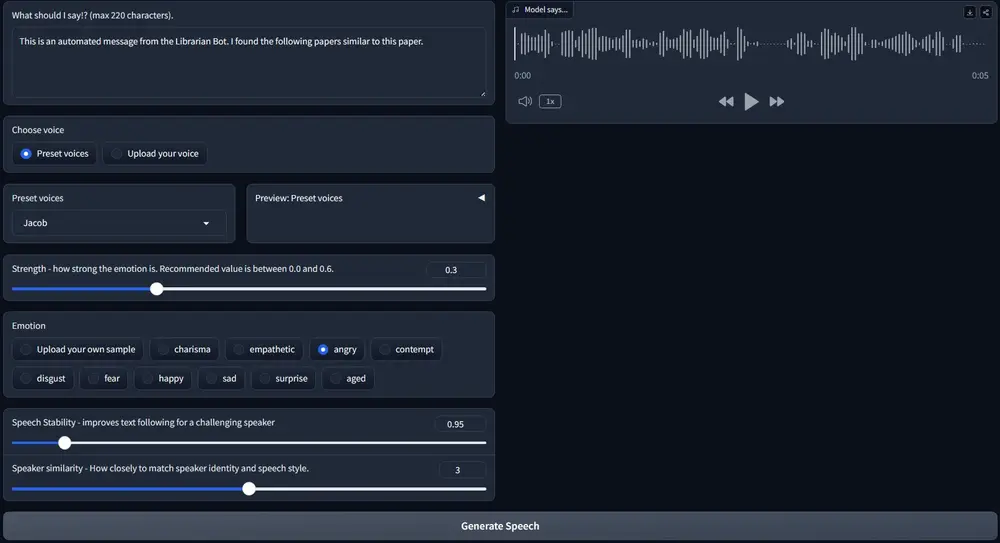
EmoKnob:允许在语音合成中对任意情感进行细粒度控制的框架哥伦比亚大学的研究人员推出一个允许在语音合成中对任意情感进行细粒度控制的框架EmoKnob,它用于提升语音克隆技术,只需少量示 范样本,允许用户在语音合成中精细控制情感及其强度。简单来说,EmoKno...新技术# EmoKnob# 语音克隆1年前08050
高效且精确的注意力机制量化方法SageAttention:加速大语言处理、图像生成和视频生成模型清华大学的研究人员推出一种高效且精确的注意力机制量化方法SageAttention,此方法的OPS(每秒操作数)性能分别比FlashAttention2和xformers提高了约2.1倍和2.7倍。S...新技术# SageAttention# 注意力机制1年前06910
新型视频生成模型Loong:基于自回归大语言模型,能够生成长达一分钟的连贯、内容丰富的视频香港大学和字节跳动的研究人员推出新型视频生成模型Loong,它基于自回归大语言模型(LLMs),能够生成长达一分钟的连贯、内容丰富的视频。这在视频生成领域是一个挑战,因为视频通常包含大量的帧,每帧都需...新技术# Loong# 自回归大语言模型1年前05390
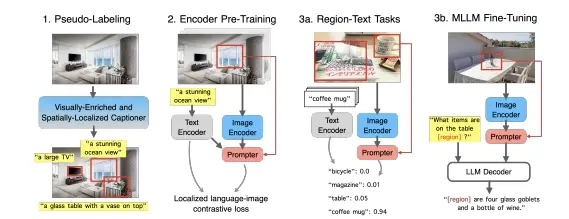
苹果推出新预训练方法CLOC:提升图像和文本表示的预训练效果,特别是在局部区域的语义理解方面苹果推出新预训练方法CLOC(对比定位语言-图像预训练),旨在提升图像和文本表示的预训练效果,特别是在局部区域的语义理解方面。CLOC模型可以生成高分辨率、细节丰富的深度图,这些深度图不仅包含整体图像...新技术# CLOC# 对比定位语言-图像预训练# 苹果1年前05160
苹果推出一个用于零样本度量单目深度估计的基础模型Depth Pro苹果推出一个用于零样本度量单目深度估计的基础模型Depth Pro,它用于提高单目深度估计的准确性和细节表现。单目深度估计是指仅使用一个摄像头拍摄的单张图片来预测场景中每个像素的深度信息。例如,你用手...新技术# Depth Pro# 苹果1年前04650
自适应投影引导APG:不牺牲图像质量的前提下,使用更高的指导尺度,从而生成更丰富、更真实的图像苏黎世联邦理工学院和迪士尼研究的研究人员推出自适应投影引导(APG),保留了CFG提高质量的优势,同时允许使用更高的引导比例而不产生过饱和。APG易于实现,并且实际上不会给采样过程带来额外的计算开销...新技术# APG# 自适应投影引导1年前04650
基于ComfyUI的ComfyGen:用于文本到图像生成的提示自适应工作流英伟达和特拉维夫大学的研究人员推出新型文生图系统ComfyGen,此系统能够根据用户提供的文本提示(prompt),自动选择或生成最适合该提示的图像生成工作流。研究团队引入了一个新颖的任务——提示自适...新技术# ComfyGen# ComfyUI# 工作流1年前07260
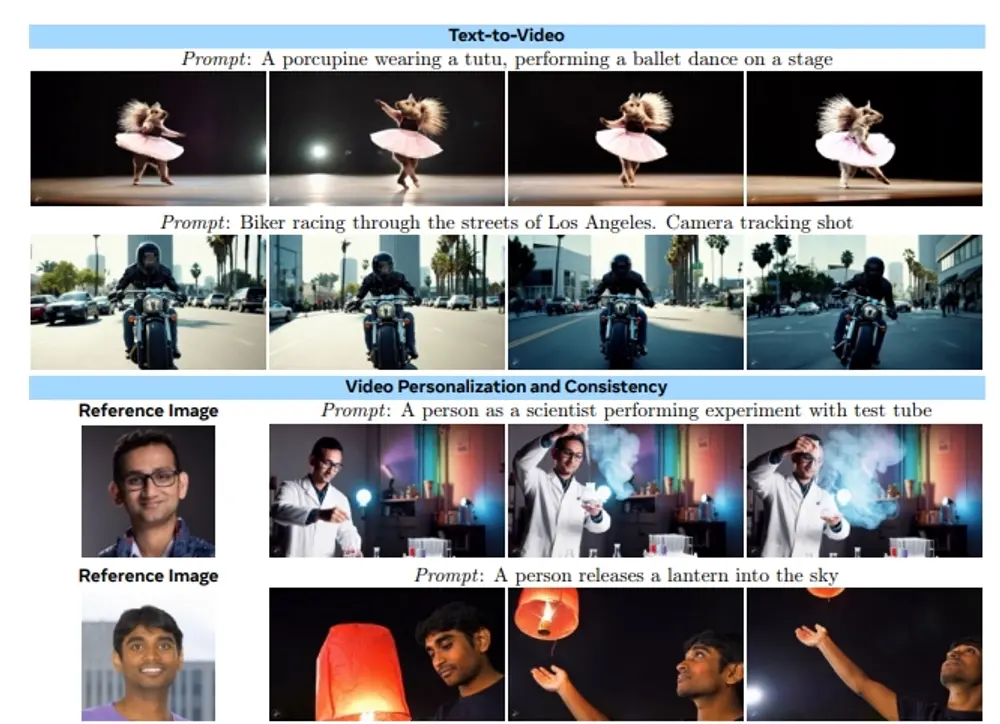
Meta推出新型视频生成模型Movie Gen:不仅能制作高清视频,还能为视频配上声音Meta宣布推出一款新AI视频生成器Movie Gen,这款工具不仅能制作高清视频,还能为视频配上声音。据Meta介绍,Movie Gen可通过简单的文字输入,自动生成全新的视频内容。此外,它还能编辑...新技术# Meta# Movie Gen# 视频生成模型1年前05510
新型视觉基础模型Lotus:使用扩散模型来生成高质量的密集预测结果香港科技大学(广州)、阿德莱德大学、诺亚方舟实验室和香港科技大学的研究人员推出新型视觉基础模型Lotus,它使用扩散模型来生成高质量的密集预测结果。简单来说,Lotus就像一个超级聪明的图像处理专家...新技术# Lotus# 视觉基础模型1年前04700
阿里推出角色视频合成框架MIMO:允许用户对视频中的人物进行替换阿里巴巴智能计算研究院推出MIMO,它能够根据用户提供的简单输入,合成具有可控属性(如角色、动作和场景)的逼真角色视频。简单来说,这项技术能够让用户通过提供一些基本的指令或样本,来创造出一段新的视频...新技术# MIMO# 角色视频合成# 阿里巴巴1年前04530