MVideo:用于生成具有精确、流畅动作的长时视频无限光年、上海交通大学和复旦大学的研究人员推出新型框架MVideo,它专门设计用于生成具有精确、流畅动作的长时视频。MVideo通过结合文本提示和掩码序列(mask sequences)作为额外的运动...新技术# MVideo# 文生视频1年前05810
专注于二次元角色的动画方法MikuDance:将二次元角色根据 Open Pose 姿势生成对应动画武汉大学、阶跃星辰和字节跳动的研究人员推出MikuDance,它是一个基于扩散的动画制作流程,用于为风格化的角色艺术作品添加混合运动动力学,使其动起来。MikuDance的核心在于它能够处理复杂的角色...新技术# MikuDance# 二次元1年前07530
大规模视频动作数据集EgoVid-5M:专为第一人称视角(egocentric)视频生成而设计阿里巴巴集团智能计算研究院、中国科学院自动化研究所、清华大学和中国科学院大学的研究人员推出大规模视频动作数据集EgoVid-5M,专为第一人称视角(egocentric)视频生成而设计。该数据集包含了...新技术# EgoVid-5M# 视频动作数据集1年前04030
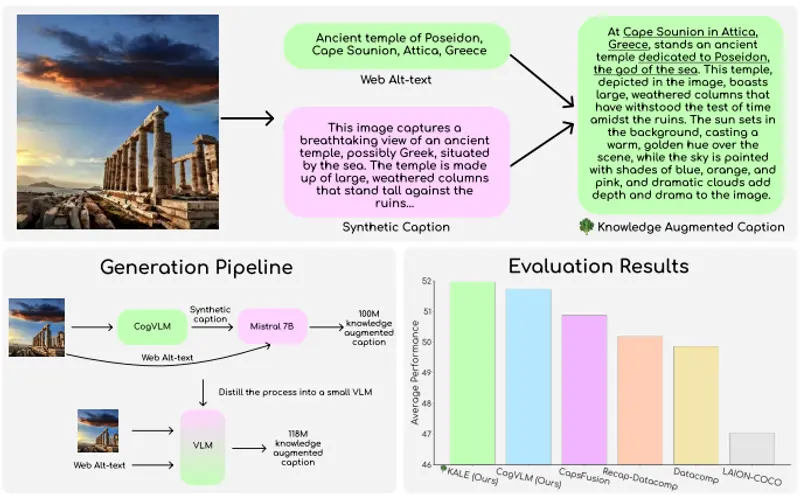
BLIP3-KALE:包含2.18亿个图像-文本对的数据集华盛顿大学、Salesforce Research、斯坦福大学和加州大学伯克利分校推出一个包含2.18亿个图像-文本对的数据集BLIP3-KALE,它弥合了描述性合成字幕和网络规模的事实性替代文本之间...新技术# BLIP3-KALE# 数据集1年前04260
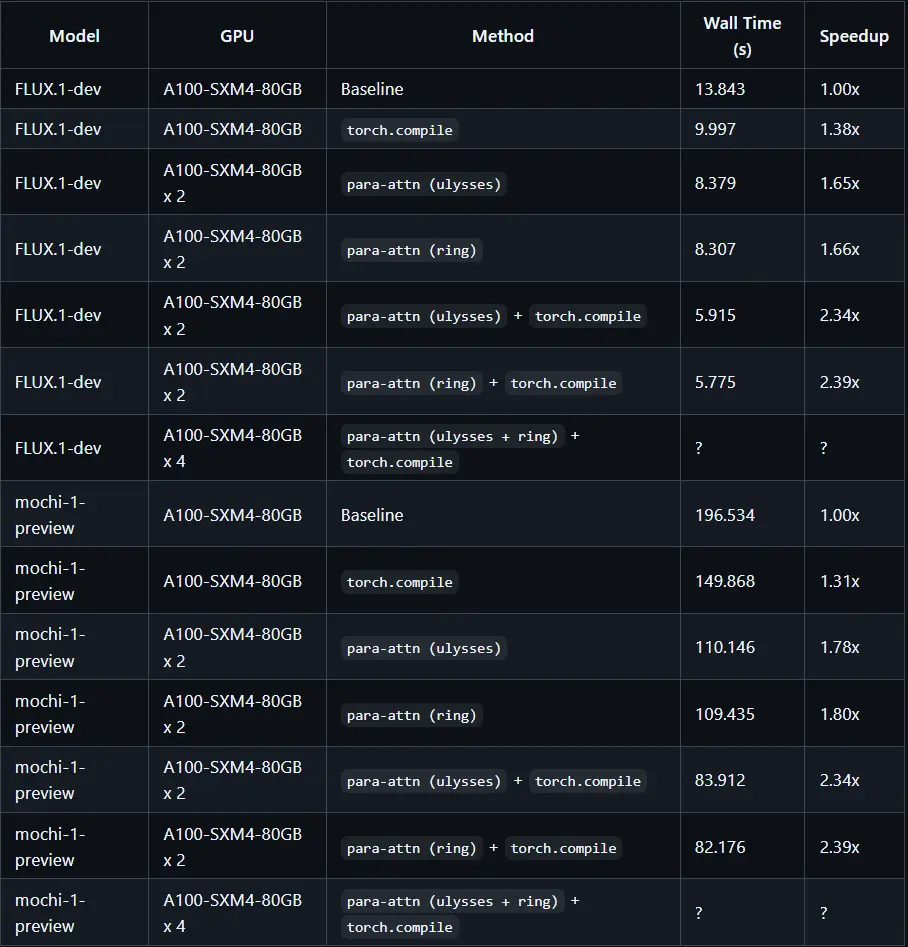
ParaAttention:通过上下文并行注意力机制,使用多个GPU加速FLUX和Mochi模型的推理ParaAttention是一种创新的上下文并行注意力机制,旨在通过多个GPU加速FLUX和Mochi模型的推理。通过支持torch.compile和多种并行策略,ParaAttention提供了高效...新技术# ParaAttention# 推理加速1年前04060
Autodesk推出新型3D生成模型WaLa:基于多种输入条件(如文本描述、图像、点云等)生成参数化的3D CAD模型Autodesk推出新型3D生成模型“Wavelet Latent Diffusion (WaLa)”,它能够基于多种输入条件(如文本描述、图像、点云等)生成参数化的3D CAD模型。WaLa模型的核...新技术# 3D生成模型# Autodesk# WaLa1年前04180
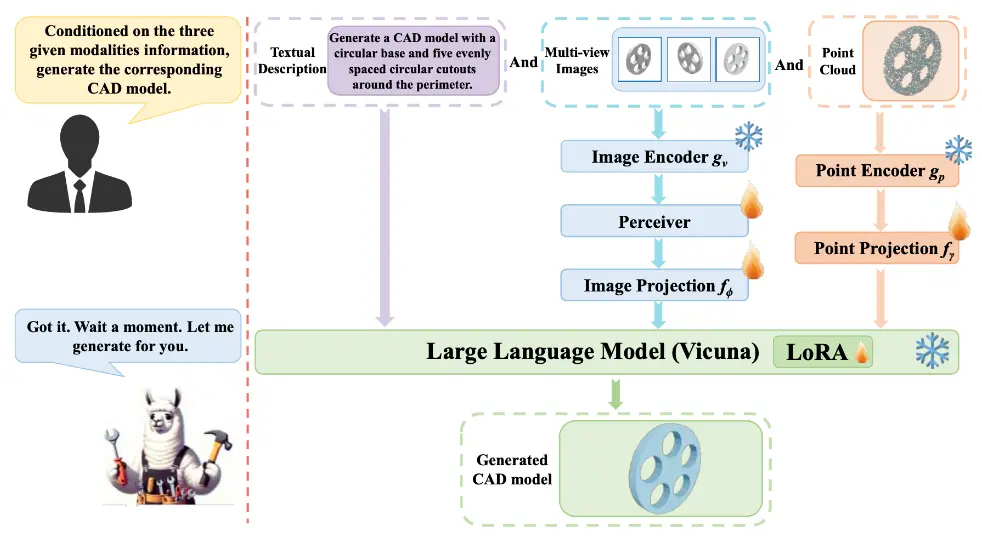
CAD-MLLM:实现一个统一的计算机辅助设计(CAD)模型生成系统上海科技大学、忆生科技、深度求索(DeepSeek-AI)和香港大学的研究人员推出一个名为“CAD-MLLM”的系统,它旨在实现一个统一的计算机辅助设计(CAD)模型生成系统。该系统能够根据用户的多种...新技术# CAD# CAD-MLLM1年前07880
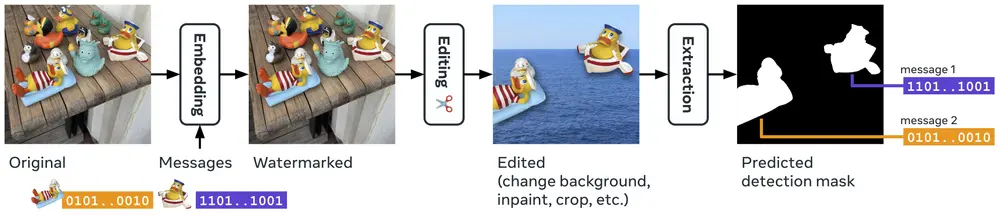
Meta推出局部图像水印的深度学习模型WAM图像水印技术在保护数字内容的版权和完整性方面发挥着重要作用。然而,传统的图像水印方法并未针对处理小面积水印区域进行优化,这限制了其在实际应用中的使用,例如图像的部分可能来自不同来源或已被编辑。Meta...新技术# WAM# 图像水印1年前07060
英伟达推出图像生成模型家族Edify Image:能够生成高保真度的图像内容,并且具有像素级完美准确性英伟达推出图像生成模型家族Edify Image,它们能够生成高保真度的图像内容,并且具有像素级完美准确性。Edify Image利用了一系列级联的像素空间扩散模型,这些模型通过一个新颖的拉普拉斯扩散...新技术# Edify Image# 图像生成# 英伟达1年前06350
英伟达推出Add-it:基于文本指令在图像中添加对象的创新方法英伟达、特拉维夫大学和巴伊兰大学的研究人员推出一个名为Add-it的系统,它是一种无需训练的方法,可以在图像中根据文本提示添加对象。这种方法扩展了预训练扩散模型的注意力机制,以整合来自三个关键来源的信...新技术# Add-it# 英伟达1年前03510
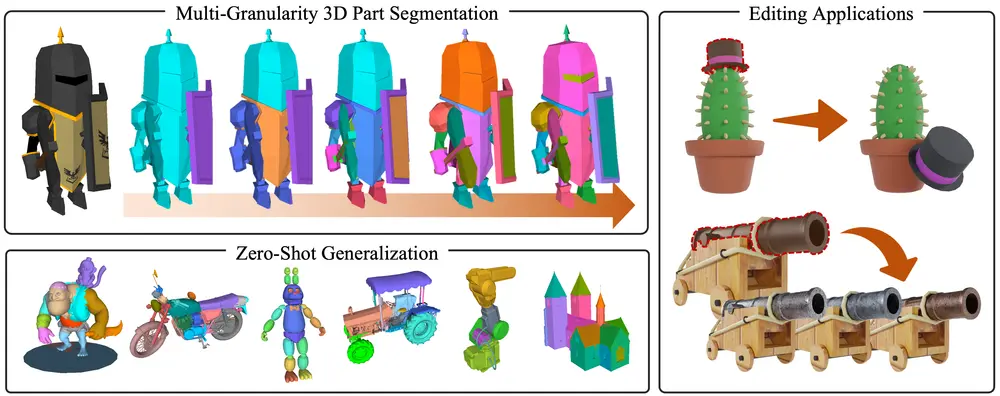
SAMPart3D:可扩展的零样本3D部件分割框架3D部件分割是3D感知中的一项关键任务,在机器人、3D生成和3D编辑等应用中发挥着重要作用。最近的方法利用强大的视觉语言模型(VLMs)进行2D到3D的知识蒸馏,实现了零样本的3D部件分割。然而,这些...新技术# 3D部件分割框架# SAMPart3D1年前04620
StdGEN:从单张图像生成高质量3D角色StdGEN 是由腾讯AI实验室、清华大学和北京航空航天大学的研究人员联合推出的一种创新管道,它能够从单张图片中生成语义分解的高质量3D角色模型。这项技术在虚拟现实、游戏和电影制作等领域有着广泛的应用...新技术# 3D# StdGEN1年前03990