个性化图像生成的高效、轻量级框架DreamCache:在不需要额外微调的情况下,通过特征缓存实现快速的个性化图像生成在数字内容创作日益丰富的今天,个性化图像生成技术正逐渐成为各行业创新的关键。这项技术依赖于文本到图像的生成模型,它们能够识别并捕捉参考对象的核心特征,从而在各种情境中实现可控的图像生成。然而,现有的方...新技术# DreamCache# 个性化图像生成1年前02930
CoDe:提高视觉自回归(VAR)模型在图像生成任务中的效率新加坡国立大学的研究人员推出一个名为“Collaborative Decoding(CoDe)”的新方法,旨在提高视觉自回归(Visual Auto-Regressive,简称VAR)模型在图像生成任...新技术# CODE# 视觉自回归模型1年前02680
3D高效框架Make-It-Animatable:将任意3D人物模型快速制作成可用于动画的角色中国科学技术大学和腾讯的研究人员推出高效框架Make-It-Animatable,它用于将任意3D人物模型快速制作成可用于动画的角色。这个框架能够在不到一秒钟的时间内,无论3D模型的形状和姿势如何,都...新技术# 3D# Make-It-Animatable1年前03240
零样本(Zero-Shot)定制化图像生成新方法Diffusion Self-Distillation斯坦福大学的研究人员推出Diffusion Self-Distillation,这是一种基于扩散模型的技术,用于零样本(Zero-Shot)定制化图像生成。这种方法可以在不需要额外推理阶段训练的情况下...新技术# Diffusion Self-Distillation# DSD1年前02680
CAT4D:用于从单目视频创建4D(动态3D)场景Google DeepMind、哥伦比亚大学和加州大学圣地亚哥分校的研究人员推出创新技术CAT4D,用于从单目视频创建4D(动态3D)场景。CAT4D利用多视图视频扩散模型,结合多种数据集进行训练,以...新技术# CAT4D1年前02660
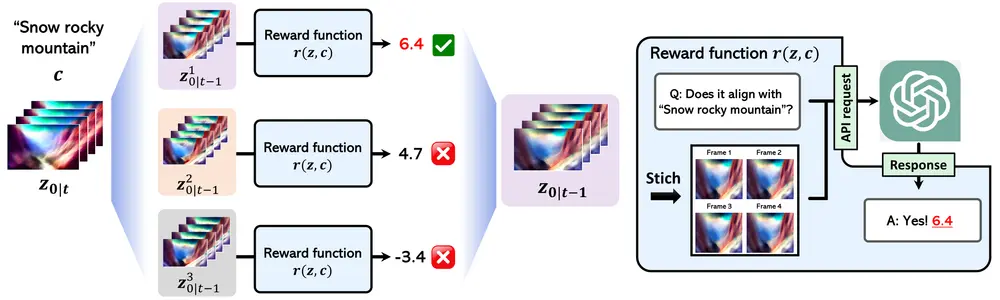
Free^2Guide:无梯度框架提升文本到视频(T2V)生成中的文本对齐扩散模型在文本到图像(T2I)和文本到视频(T2V)合成等生成任务中取得了显著成果。然而,在T2V生成中,实现准确的文本对齐仍然是一个具有挑战性的问题,尤其是在处理帧间复杂的时序依赖性时。现有的基于强...新技术# Free^2Guide# 视频生成1年前03150
ROICtrl:通过区域实例控制增强扩散模型的多实例生成自然语言在描述复杂场景时,尤其是在准确地将位置和属性信息与多个实例关联方面,常常遇到困难。这限制了当前基于文本的视觉生成模型,使其只能生成包含少数主导实例的简单组合。为了解决这一限制,新加坡国立大学...新技术# ROICtrl1年前03050
无需训练的视频细化框架VideoRepair:自动识别和修复文生视频模型生成中的细粒度不对齐问题最近的文生视频模型在生成高质量视频方面取得了显著进展,但这些模型生成的视频往往与文本提示存在不对齐的情况,尤其是在处理包含多个对象和属性的复杂场景时。为了解决这一问题,北卡罗来纳大学教堂山分校的研究人...新技术# VideoRepair# 视频生成模型1年前03280
个性化面部老化方法MyTimeMachine:根据个人特定的照片集合来训练一个个性化的年龄转换模型,实现从儿童到老年的个性化面部年龄变化面部老化是一个复杂的过程,受到多种因素的影响,如性别、种族、生活方式等。尽管现有的面部老化技术能够生成逼真的老化图像,但它们通常无法准确预测特定个体的老化过程,因为这些技术缺乏个性化处理。为了克服这一...新技术# MyTimeMachine# 年龄# 面部老化1年前03430
ViewExtrapolator:于在新视角合成领域中进行新视角外推南洋理工大学和中国科学院大学的研究人员推出一个名为ViewExtrapolator的新方法,它用于在新视角合成(novel view synthesis, NVS)领域中进行新视角外推(novel v...新技术# ViewExtrapolator1年前03240
适用于FLUX 和 SD3.5模型的新采样器Style-Friendly SNR:更好地捕捉独特的风格,并生成风格对齐度更高的图像近年来,大型扩散模型在生成高质量图像方面取得了显著进展。然而,这些模型在学习新的、个性化的艺术风格方面存在困难,这限制了独特风格模板的创建。传统的微调方法通常盲目地利用预训练中使用的目标和噪声水平分布...新技术# Style-Friendly SNR# 采样器1年前05560
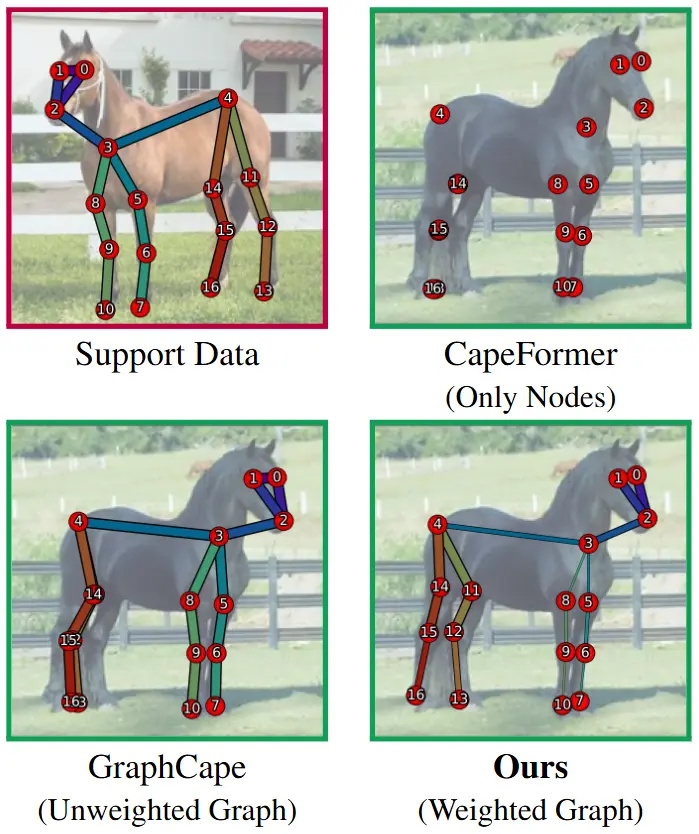
用于类别无关的姿态估计新型框架EdgeCape特拉维夫大学的研究人员推出新型框架EdgeCape,它用于类别无关的姿态估计(Category-Agnostic Pose Estimation, CAPE)。EdgeCape能够通过单一模型在多样化...新技术# EdgeCape# 姿态估计1年前03870