SageAttention3 发布:FP4 推理加速与 8 位训练新探索清华大学研究团队近日推出 SageAttention3,一项聚焦于提升 Transformer 注意力机制效率的新研究成果。该工作在推理阶段引入基于 FP4 的微缩放量化技术,并首次系统性探索了 8 ...新技术# SageAttention3# 清华大学4个月前0790
Windows ML 现已可用:让 AI 应用更高效运行在你的电脑上微软宣布,其 Windows ML 平台现已正式进入生产可用状态,面向所有运行 Windows 11 24H2 及以上版本的设备开放。这一进展标志着 Windows 在本地 AI 能力上的关键落地...新技术# Windows ML4个月前0910
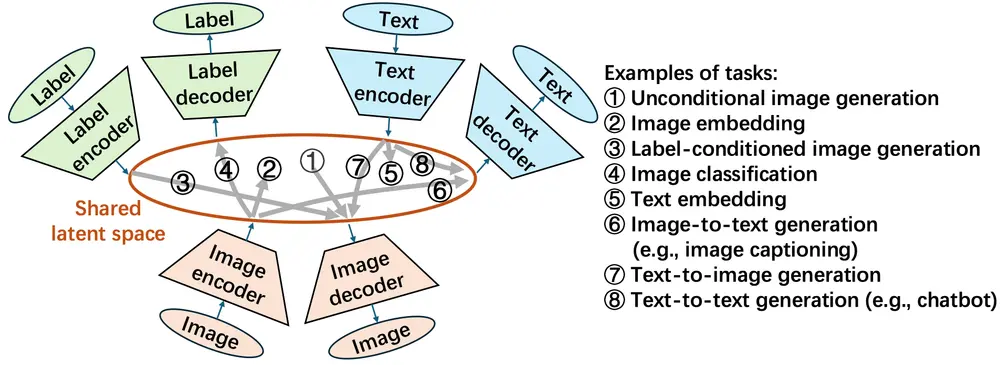
潜在分区网络(LZN):以共享高斯潜在空间,统一生成、表示与分类的机器学习新框架在机器学习领域,生成模型(如 DALL・E 生成图像、ChatGPT 生成文本)、表示学习(如 CLIP 实现图文表示匹配)、分类模型(如 ResNet 进行图像分类)是三大核心方向,且各自都已取得成...新技术# LZN# 潜在分区网络4个月前01000
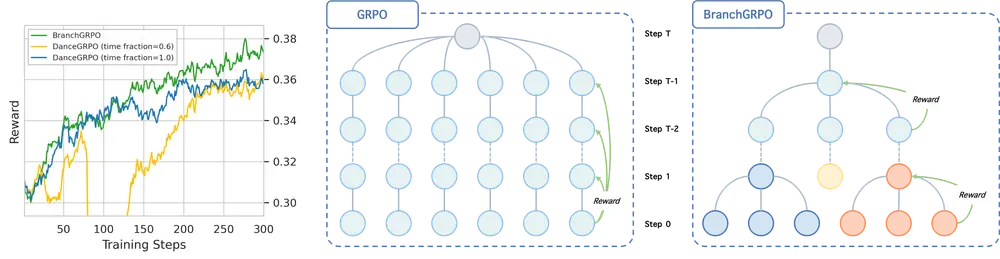
BranchGRPO:树状分支重构,破解GRPO图像视频生成对齐的效率与稳定性难题在图像、视频生成领域,“让模型输出与人类偏好对齐”是关键目标——无论是生成符合审美标准的图像,还是帧间连贯的视频,都需要通过算法优化缩小模型输出与人类期望的差距。群体相对策略优化(GRPO)是近年常用...新技术# BranchGRPO4个月前0960
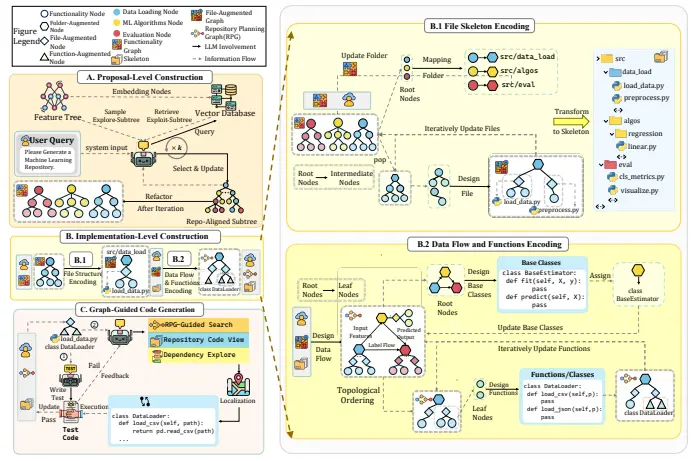
RPG:一种用于统一且可扩展代码库生成的存储库规划图微软、清华大学和加州大学圣地亚哥分校的研究人员推出一个名为 Repository Planning Graph (RPG) 的框架,用于从头开始生成完整的软件仓库。它通过将软件的功能规划和实现规划统一...新技术# RPG# 代码库生成4个月前0990
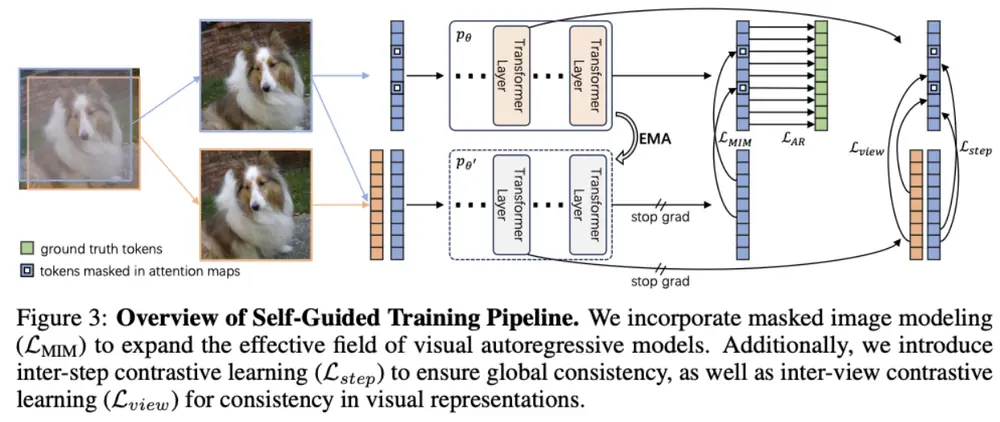
ST-AR:让自回归图像生成学会“先理解,再生成”自回归模型(Autoregressive, AR)因其强大的序列建模能力,最初在自然语言处理中取得成功,随后被引入图像生成领域。这类模型将图像视为“视觉词元”序列,通过逐个预测 token 的方式重建...新技术# ST-AR# 自回归图像生成4个月前01850
局部性从何而来?MIT与丰田研究所揭示扩散模型中的数据驱动机制在图像生成领域,扩散模型已成为主流架构之一。其训练过程基于一个理论上的“最优去噪器”——即在给定噪声水平下,能够最小化重建误差的理想函数。有趣的是,这一最优解虽然数学上可定义,却只能复现训练集中的样本...新技术# 图像扩散模型5个月前0770
艾伦AI研究所推出Fluid Benchmarking:为每个语言模型定制最合适的考题在当前的语言模型评测中,我们通常采用“统一试卷”模式: 无论模型是刚起步的小型模型,还是千亿参数的顶尖系统,都使用同一套固定题目进行打分。 这就像让小学生和博士生做同一份数学卷子——看似公平,实则难以...新技术# Fluid Benchmarking# 流动基准测试# 艾伦AI研究所5个月前01080
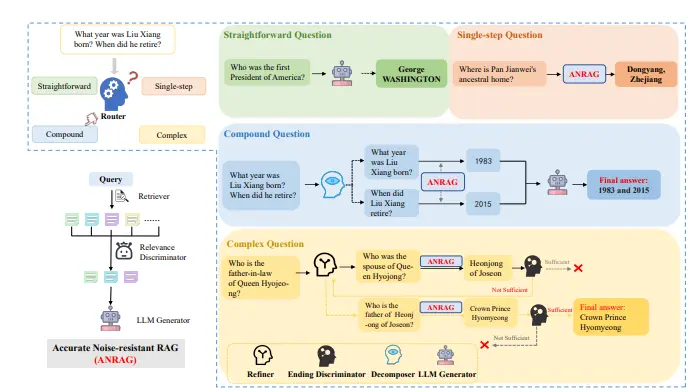
蚂蚁集团发布针对多跳问答任务的增强型检索-生成(RAG)框架HANRAG蚂蚁集团发布新型框架HANRAG,这是一个针对多跳问答任务的增强型检索-生成(RAG)框架,通过结合启发式方法和强大的“启示者”(Revelator)主代理,高效处理各种复杂性的问题,提高多跳问答系统...新技术# HANRAG# 蚂蚁集团5个月前01000
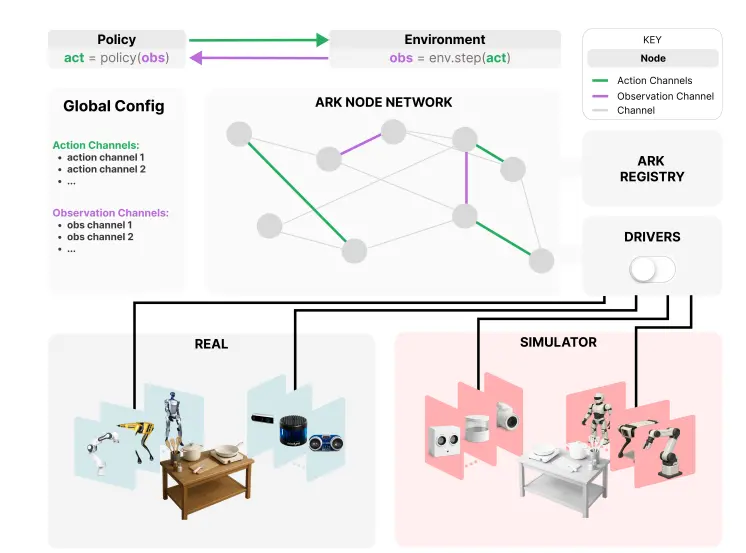
开源机器人学习框架Ark:简化机器人软件开发和部署而设计达姆施塔特工业大学、华为诺亚方舟、伦敦帝国理工学院、牛津大学和伦敦大学学院的研究人员推出开源机器人学习框架Ark,通过提供一个基于 Python 的、易于使用的环境来加速机器人学习的研究和商业部署。 ...新技术# Ark# 机器人学习框架5个月前0640
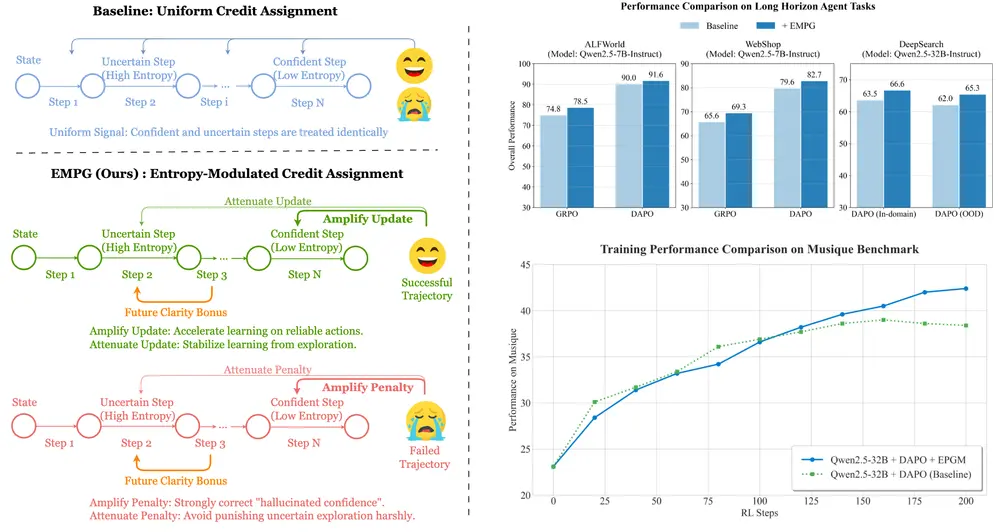
新型强化学习算法框架EMPG:提升了智能体在长时域任务中的性能与稳定性在复杂任务中,如网页购物、虚拟环境导航或深度信息检索,大语言模型(LLM)作为智能体的表现正日益受到关注。然而,一个长期困扰研究者的难题是:这些任务往往只在最终成功或失败时给出奖励信号——中间成百上千...新技术# EMPG# 强化学习算法5个月前01750
RewardDance:用生成式奖励重塑视觉强化学习,让AI生成的图像和视频真正“理解”你的需求在视觉生成领域,强化学习(Reinforcement Learning, RL)正成为提升模型表现的关键手段。其中,奖励模型(Reward Model, RM)作为引导生成方向的核心组件,直接影响最终...新技术# RewardDance# 字节跳动5个月前01230