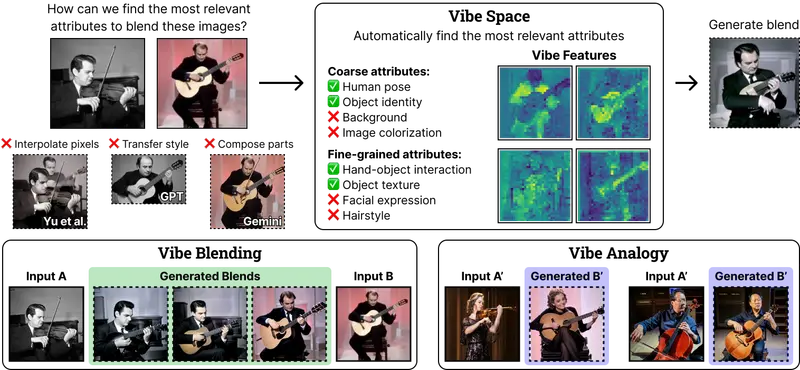
当 AI 被要求“融合一个小提琴演奏者和一个吉他演奏者”,它该生成什么?是乐器颜色的平均?演奏姿态的混合?还是创造出一种新型弦乐器演奏者——比如手持鲁特琴、姿势介于两者之间的形象?
传统方法往往停留在像素插值或风格迁移层面,而人类的直觉则关注共享的语义属性:乐器、演奏方式、肢体语言——这种直觉,被宾夕法尼亚大学、纽约市立大学和加州大学伯克利分校的研究者称为 “vibe”(氛围)。
- 项目主页:https://huzeyann.github.io/VibeSpace-webpage
- GitHub:https://github.com/huzeyann/VibeSpace
- Demo:https://huggingface.co/spaces/huzey/VibeSpace
他们提出的 Vibe Space 框架,首次在 CLIP 等视觉特征空间中学习低维测地线(geodesics),使 AI 能沿着“有意义的语义路径”实现概念间的平滑过渡,而非简单线性混合。
什么是 “Vibe Blending”?
“Vibe” 源自 1960 年代爵士乐俚语,指音乐、人物或场景所传递的整体氛围或感觉。在视觉上下文中,它代表一组跨概念共享的、可迁移的语义属性。
Vibe Blending 是一项新任务:给定两张图像,识别其最相关的共享属性(即 “vibe”),并据此生成连贯、合理且富有创意的混合体。
例如:
- 小提琴手 + 吉他手 → 鲁特琴演奏者(保留“弦乐器”+“持琴姿势”)
- 哥特教堂 + 摩天楼 → 尖顶玻璃塔(融合“垂直感”+“尖拱结构”)
- 猫 + 战斗机 → 流线型猫形飞行器(提取“敏捷”+“空气动力学外形”)
关键在于:忽略颜色、背景等无关变量,聚焦语义核心。
技术实现:Vibe Space 如何工作?
Vibe Space 是一个分层图流形(hierarchical graph manifold),通过以下步骤构建语义路径:
- 特征提取
使用 DINO 提取图像的密集视觉特征,作为图的节点。 - 图扩散映射(Graph Diffusion Map)
基于特征相似性构建图,计算其拉普拉斯矩阵的特征向量,形成低维嵌入——这一步捕捉了数据流形的内在几何结构。 - Vibe Space 学习
训练两个轻量级 MLP(编码器 + 解码器):- 编码器:将 DINO 特征映射到低维 Vibe Space
- 解码器:将 Vibe Space 坐标映射回 CLIP 特征空间
- 路径生成与渲染
- 在 Vibe Space 中进行线性插值(实际对应原始空间中的非线性测地线)
- 通过 IP-Adapter 将特征路径解码为最终图像
核心特性
- ✅ 语义优先的融合:不依赖像素或风格,而是基于可解释的视觉属性
- ✅ 多尺度结构保持:通过 Flag Space 同时建模全局构图与局部细节
- ✅ 负属性控制:用户可指定“不要出现汽车”“避免红色”等排除项,精细调控输出
- ✅ 多图像扩展:支持三个及以上概念的混合(如“猫 + 飞机 + 潜艇”)
实验结果:人类更喜欢“有 vibe”的混合
研究团队在 Totally Looks Like 数据集及自建建筑风格对上进行了评估:
- 人类偏好测试:在高难度(语义差异大)图像对上,Vibe Blending 生成的混合体被显著评为更具创意性与连贯性,优于 Gemini、GPT-4V 等基线。
- 定量指标:在 Attribute-Masked DreamSim(屏蔽属性后的感知相似度)上表现最佳,证明其保留了核心语义。
- 路径非线性评分(PNS):能自动识别“难以融合”的图像对,为后续研究提供高质量挑战样本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...