新型通用且一致的单目人类重光照和协调模型 Comprehensive Relighting :能够从单张图像或视频中控制和协调任意身体部位的人类的光照属性,并使其与背景场景(即背景图像)自然融合南加州大学、Adobe 研究院、Runway的研究人员推出新型通用且一致的单目人类重光照(relighting)和协调(harmonization)模型 Comprehensive Relightin...新技术11个月前02550
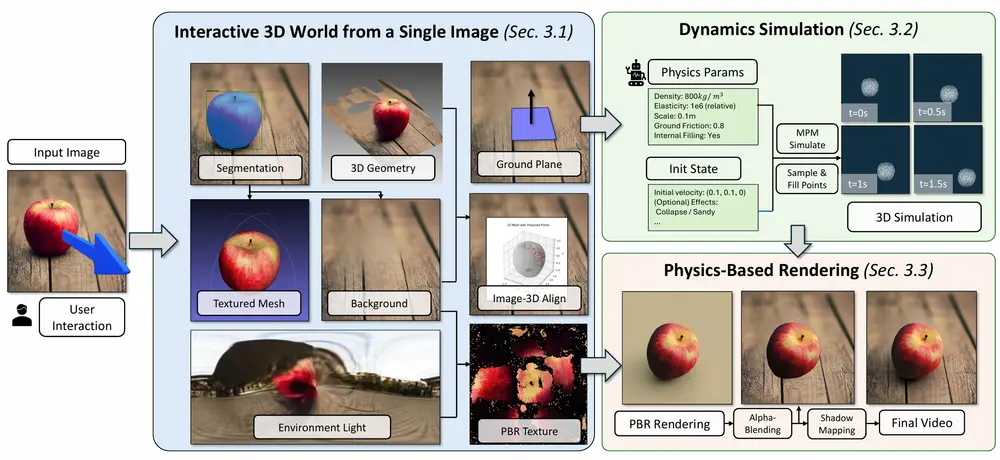
PhysGen3D:从一张图片创造真实物理世界的交互式3D场景清华大学、伊利诺伊大学厄巴纳香槟分校和哥伦比亚大学的研究人员携手推出了一项创新成果—PhysGen3D,将单一图像转化为非模态、以相机为中心的交互式 3D 场景。 项目主页:https://by-lu...新技术# 3D场景# PhysGen3D12个月前05400
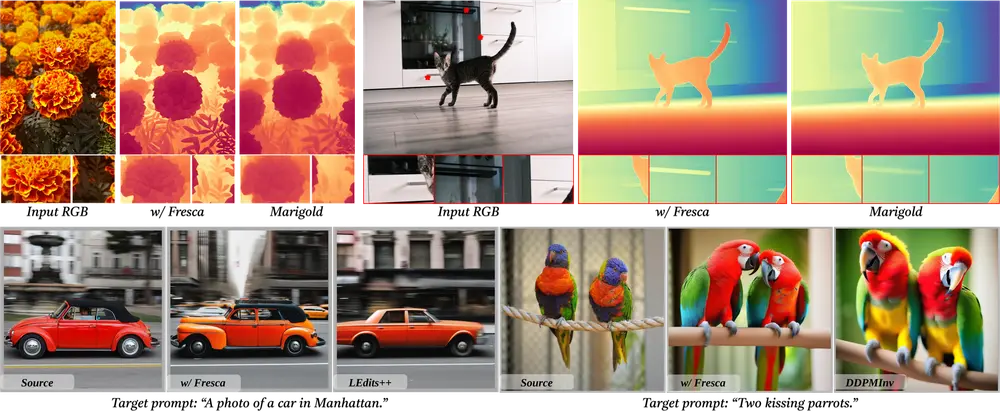
FreSca:用于增强扩散模型在图像编辑和图像理解任务中的性能罗切斯特大学、Netflix Eyeline Studios和德克萨斯大学达拉斯分校的研究人员推出 FreSca,用于增强扩散模型(Diffusion Models)在图像编辑和图像理解任务中的性能...新技术# FreSca# 图像理解# 图像编辑12个月前03090
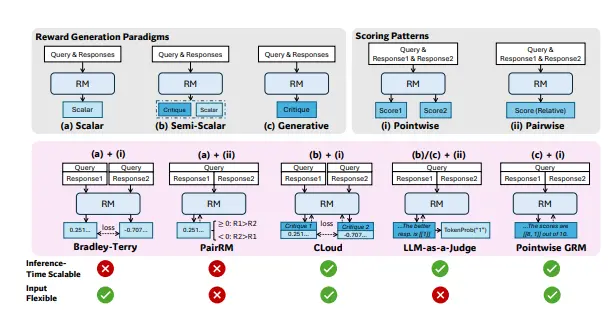
通过推理计算来提高通用奖励建模(RM)的推理时间可扩展性强化学习(RL)在大语言模型(LLM)的后续训练中已被广泛应用,尤其是在提升模型的推理能力方面。然而,如何在各种领域中为LLM获得准确的奖励信号,仍然是一个关键挑战。 论文:https://arxiv...新技术# DeepSeek# 奖励建模# 清华大学12个月前03210
Anthropic发布AI安全性研究:链式推理(CoT)的忠实度评估Anthropic最近发布了一篇关于推理模型的链式推理(CoT)忠实度的研究论文。这项研究深入探讨了CoT在AI安全中的应用,尤其是其在监控模型意图和推理过程中的有效性。 研究背景 CoT的重要性 链...新技术# Anthropic# CoT# 思维链12个月前03330
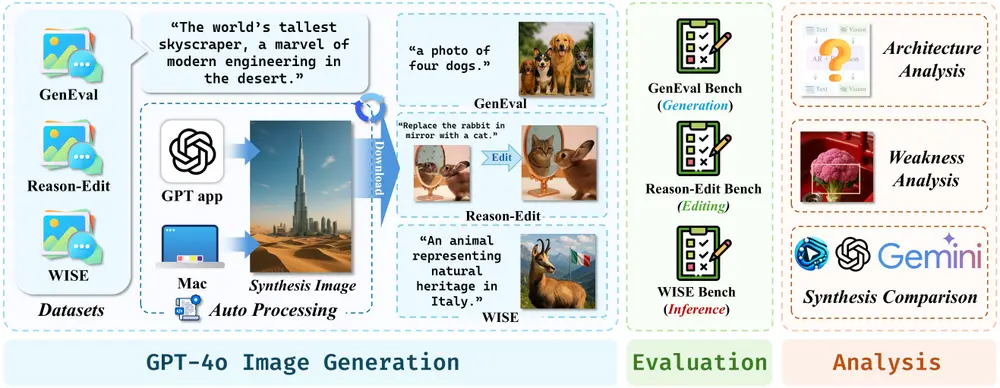
首个针对 GPT-4o 图像生成能力进行定量和定性评估的基准测试GPT-ImgEval北京大学深圳研究生院、中山大学、Rabbitpre AI、上海人工智能实验室、深圳大学和香港科技大学(广州)的研究人员发布首个针对 GPT-4o 图像生成能力进行定量和定性评估的基准测试GPT-Img...新技术# GPT-4o# GPT-ImgEval12个月前07400
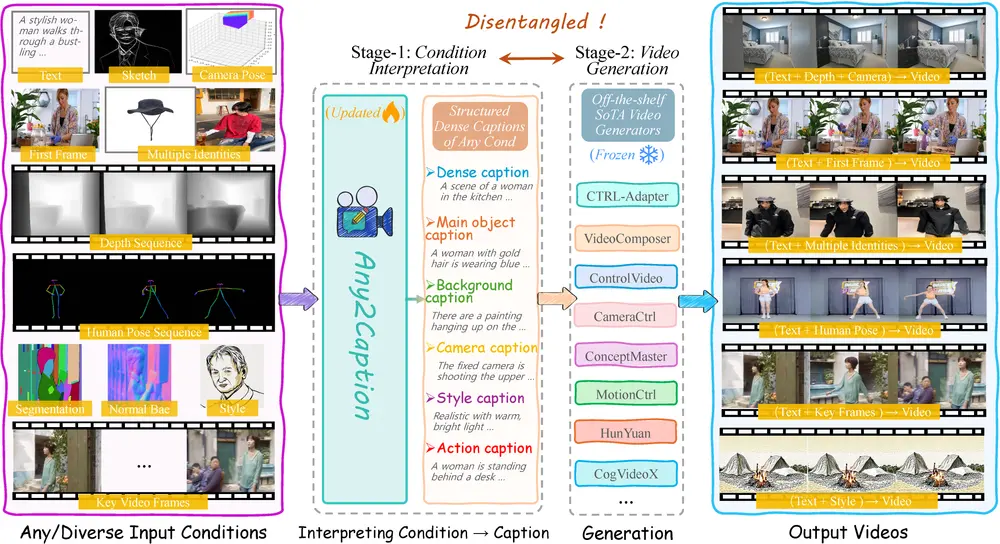
Any2Caption:通过将多样化的输入条件(如文本、图像、视频、人体姿态、相机运动等)转化为结构化的详细字幕,从而实现可控的视频生成快手和新加坡国立大学的研究人员推出新型框架 Any2Caption ,通过将多样化的输入条件(如文本、图像、视频、人体姿态、相机运动等)转化为结构化的详细字幕,从而实现可控的视频生成。这一框架的核心思...新技术# Any2Caption# 视频生成12个月前02940
字节跳动推出基于DiT模型的人类图像动画框架DreamActor-M1:实现整体性、表现力和鲁棒性的人类图像动画生成字节跳动推出一个基于DiT模型的人类图像动画框架DreamActor-M1,实现整体性(holistic)、表现力(expressive)和鲁棒性(robust)的人类图像动画生成。该框架通过混合引导...新技术# DiT模型# DreamActor-M1# 字节跳动12个月前02820
大语言模型真的具备推理能力吗?——RoR-Bench研究揭示真相随着大语言模型(LLMs)在各种任务上的表现越来越接近人类水平,人们开始质疑这些模型是否真的具备人类意义上的推理能力,还是仅仅是在重复训练过程中见过的解决方案。 论文:https://arxiv.or...新技术# 大语言模型# 推理能力12个月前02550
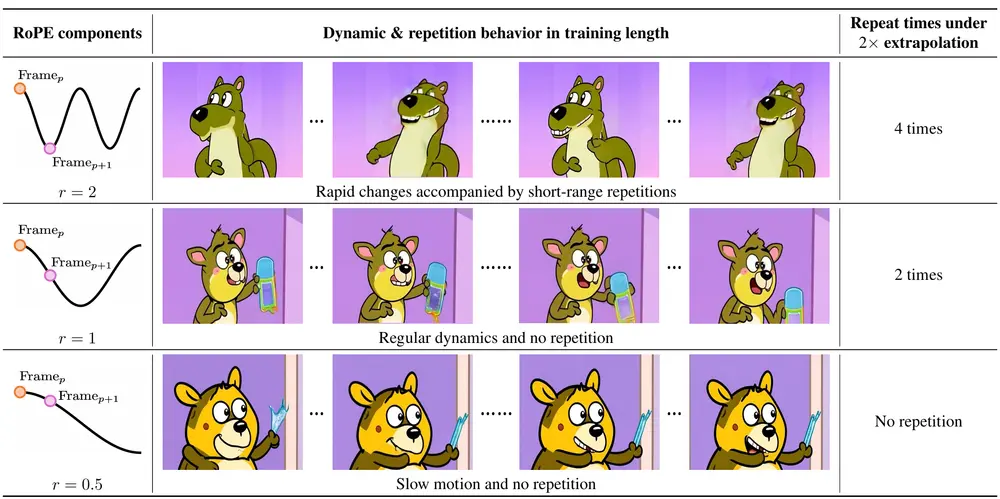
清华大学推出RIFLEx:解决视频扩散模型在生成更长视频时的时空连贯性问题清华大学的研究人员推出RIFLEx,解决视频扩散模型在生成更长视频时的时空连贯性问题。该方法通过调整位置编码中的内在频率,有效抑制重复内容的生成,同时保持运动一致性,无需额外训练或修改模型。 项目主页...新技术# RIFLEx# 清华大学# 视频扩散模型12个月前04740
最优步长蒸馏(OSS):通过优化采样步长来加速扩散模型的生成过程,同时保持生成质量扩散模型是一种强大的生成模型,能够生成高质量的图像、视频等内容。然而,传统的扩散模型在采样过程中需要大量的步骤来逐步去除噪声并生成最终结果,这使得采样过程计算成本高昂。例如,在生成一张高质量的图像时...新技术# OSS# 扩散模型# 最优步长蒸馏12个月前04330
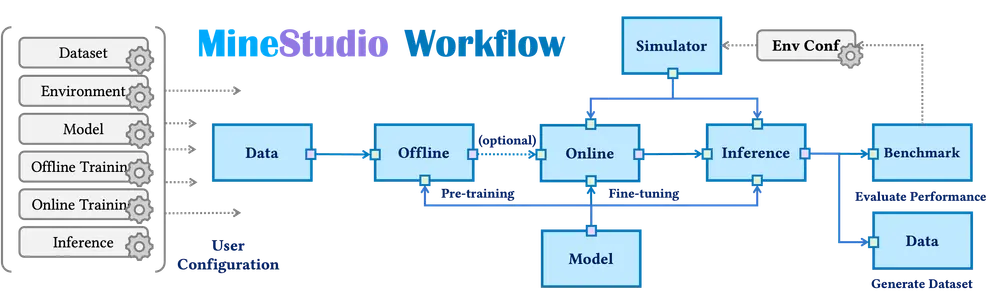
MineStudio:用于简化《我的世界(Minecraft)》中AI代理开发的开源软件包北京大学和加州大学洛杉矶分校的研究人员推出MineStudio,这是一个用于简化《我的世界(Minecraft)》中AI代理开发的开源软件包。它通过整合七个关键工程组件(模拟器、数据、模型、离线预训练...新技术# MineStudio# 我的世界12个月前04780