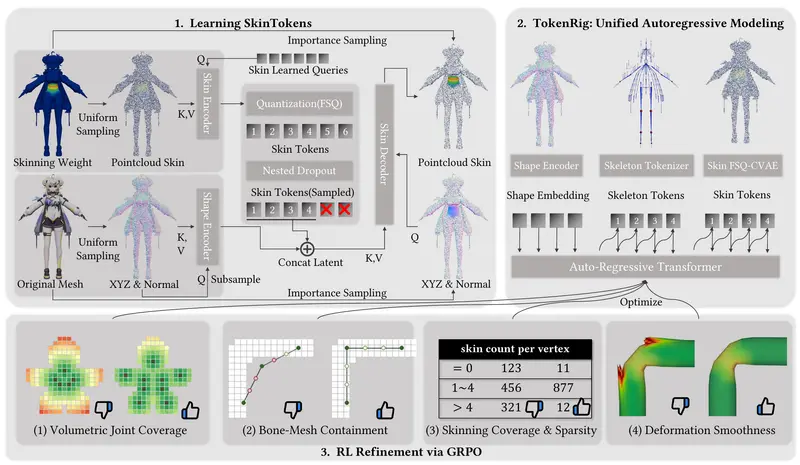
清华大学与 VAST 联合推出 SkinTokens:用离散令牌统一建模 3D 绑定(Rigging)在生成式 3D 模型快速发展的背景下,绑定(Rigging)——即为静态 3D 模型添加骨骼与蒙皮权重以支持动画——已成为自动化流程中的关键瓶颈。现有方法通常将蒙皮(Skinning)视为一个高维、不...3D模型# SkinTokens# VAST# 清华大学2个月前0620
SageAttention3 发布:FP4 推理加速与 8 位训练新探索清华大学研究团队近日推出 SageAttention3,一项聚焦于提升 Transformer 注意力机制效率的新研究成果。该工作在推理阶段引入基于 FP4 的微缩放量化技术,并首次系统性探索了 8 ...新技术# SageAttention3# 清华大学6个月前01210
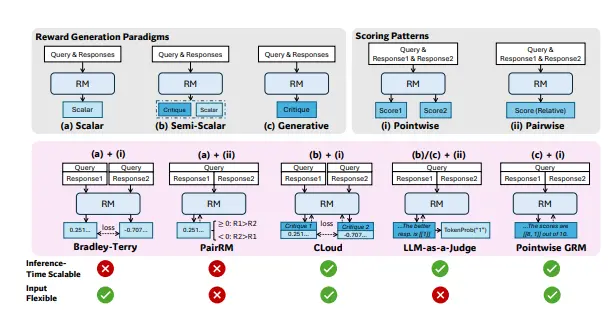
通过推理计算来提高通用奖励建模(RM)的推理时间可扩展性强化学习(RL)在大语言模型(LLM)的后续训练中已被广泛应用,尤其是在提升模型的推理能力方面。然而,如何在各种领域中为LLM获得准确的奖励信号,仍然是一个关键挑战。 论文:https://arxiv...新技术# DeepSeek# 奖励建模# 清华大学1年前03260
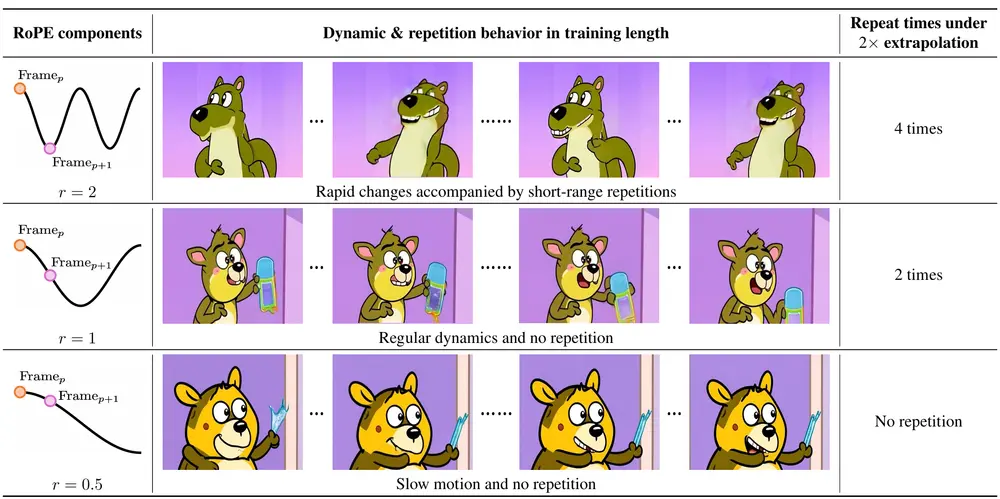
清华大学推出RIFLEx:解决视频扩散模型在生成更长视频时的时空连贯性问题清华大学的研究人员推出RIFLEx,解决视频扩散模型在生成更长视频时的时空连贯性问题。该方法通过调整位置编码中的内在频率,有效抑制重复内容的生成,同时保持运动一致性,无需额外训练或修改模型。 项目主页...新技术# RIFLEx# 清华大学# 视频扩散模型1年前04790
高效稀疏注意力机制 SpargeAttn:加速大模型的推理过程,同时不损失模型性能清华大学和加州大学伯克利分校的研究人员推出高效稀疏注意力机制 SpargeAttn,旨在加速大模型的推理过程,同时不损失模型性能。注意力机制在现代深度学习模型中扮演着重要角色,但由于其计算复杂度与序列...新技术# SpargeAttn# 加州大学伯克利分校# 清华大学1年前05970
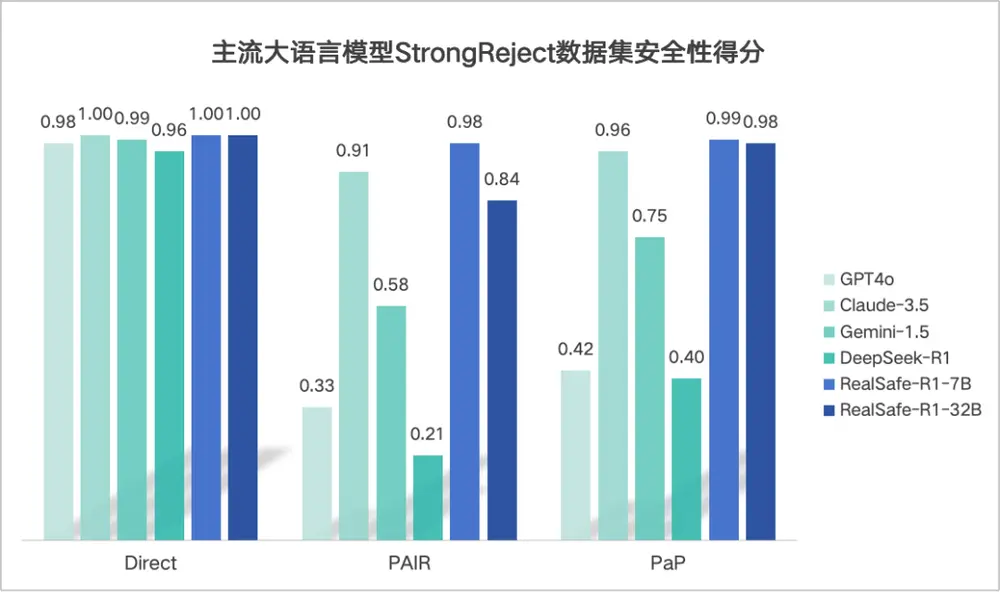
清华大学与瑞莱智慧联合团队推出RealSafe-R1:基于 DeepSeek R1 的安全优化大语言模型随着大语言模型(LLMs)在各个领域的广泛应用,其安全性问题日益受到关注。尽管这些模型在性能上表现出色,但在面对恶意查询和越狱攻击时,仍存在一定的风险。为了应对这一挑战,清华大学与瑞莱智慧联合团队推出...新技术# DeepSeek-R1# RealSafe-R1# 大语言模型1年前05590
清华大学和新畅元科技推出Human4DiT:能够根据单幅图像及任意视点生成高质量、时空连贯的人类视频清华大学和新畅元科技推出新技术Human4DiT,它是一种用于生成高质量、时空一致的人类视频的4D扩散变换器(4D Diffusion Transformer)。这项技术可以从单张图片生成逼真的人类动...新技术# Human4DiT# 新畅元科技# 清华大学2年前08770
新型实时端到端目标检测系统YOLOv10:快速地识别图像中的多个对象,并且告诉用户这些对象的具体位置清华大学的研究人员推出新型实时端到端目标检测系统YOLOv10,目标检测是计算机视觉领域的一个重要任务,它的目的是识别出图像中的对象,并确定它们的位置。例如,你在玩一个视频游戏,需要快速识别并射击屏幕...新技术# YOLOv10# 清华大学# 目标检测2年前01,1340
AI视频生成新框架Motion-I2V:让用户通过简单的轨迹绘制或区域选择来控制生成的视频内容来自NVIDIA AI、香港中文大学、商汤科技、清华大学、CPII、上海人工智能实验室、Avolution AI的研究人员推出图像到视频生成(I2V)新框架Motion-I2V,它是一个用于将静态图片...新技术# AI视频生成# Motion-I2V# 清华大学2年前08770
无需训练的组合式文本到图像生成方法CompAgent来自清华大学、华为诺亚方舟实验室、香港大学的研究人员提出了一种无需训练的组合式文本到图像生成方法CompAgent,该方法利用大语言模型(LLM)智能体进行复杂文本提示的分析与规划,将文本分解为单个对...新技术# CompAgent# 华为诺亚方舟# 文生图2年前06940