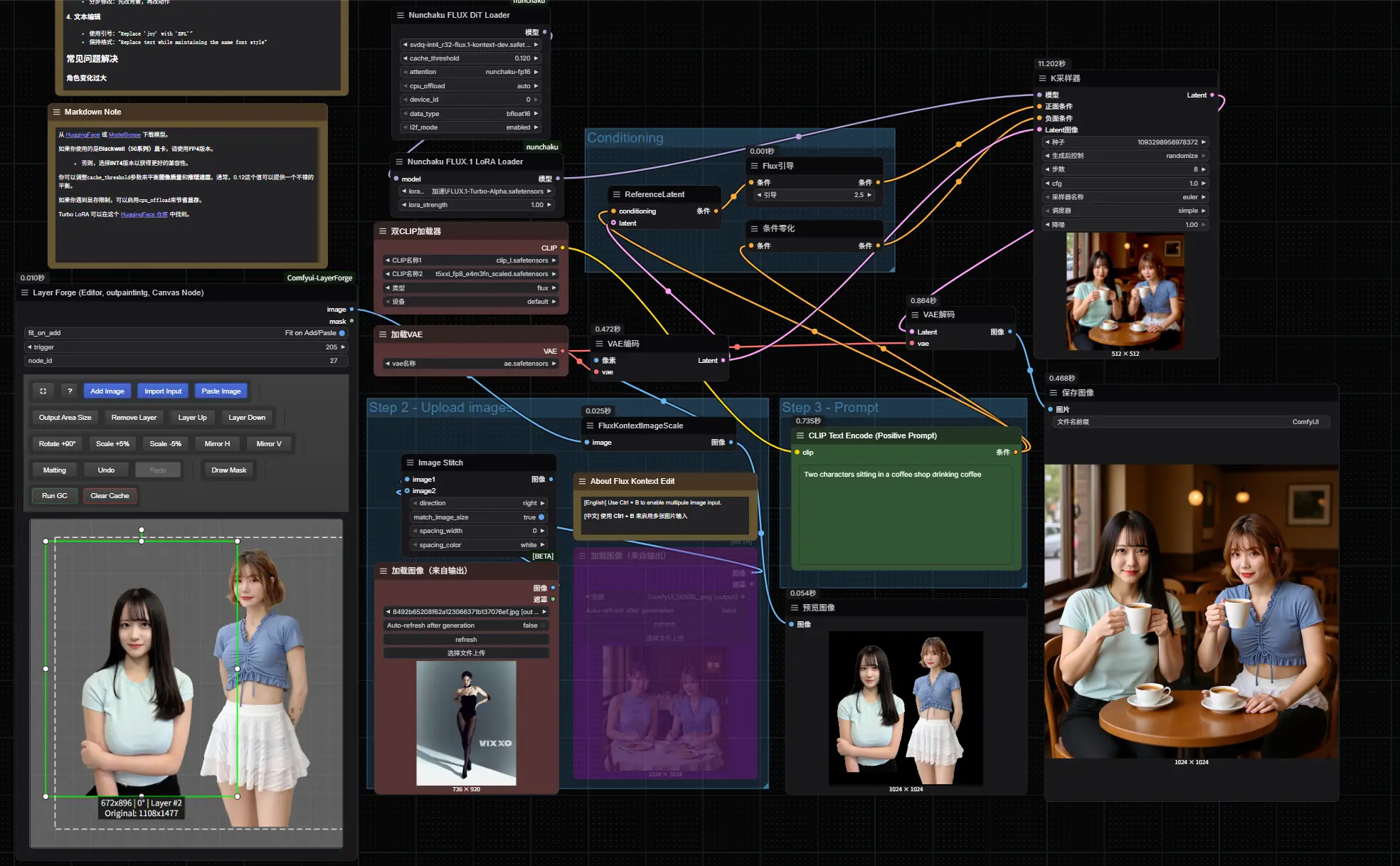
Nunchaku正式支持FLUX.1 Kontext Dev:低显存用户的福音在6月26日,黑森林实验室(Black Forest Labs)发布了其图像编辑模型FLUX.1 Kontext开源版本 FLUX.1 Kontext [dev]。尽管这一模型在图像编辑质量上表现优异...工作流# FLUX.1 Kontext [dev]# Nunchaku# nunchaku-flux.1-kontext-dev9个月前01,4890
统一视觉理解与生成框架UniWorld:支持 20+语义图片编辑任务北京大学深圳研究生院、鹏城实验室、兔展AI的研究人员推出统一视觉理解与生成框架UniWorld,它基于强大的视觉-语言模型和对比语义编码器,能够同时处理图像感知和图像操控任务。 GitHub:http...图像模型# UniWorld# 图像生成# 图像编辑10个月前04580
ComfyUI 新玩法:用 Flux.1 Kontext Pro 和 Max 图像 API 节点轻松实现智能图像编辑在图像编辑领域,高效且精准的工具是提升工作效率的关键。今天,我们将深入探讨如何在 ComfyUI 中利用 Flux.1 Kontext Pro Image API 节点来实现强大的图像编辑功能。通过简...工作流# ComfyUI# Flux.1 Kontext Pro# 图像编辑10个月前09460
基于Flux模型的图像编辑框架Insert Anything:通过用户指定的灵活控制,将参考图像中的对象无缝整合到目标场景中来自 浙江大学、哈佛大学 和 南洋理工大学 的研究人员提出了一种名为 Insert Anything 的创新框架,通过用户指定的灵活控制,将参考图像中的对象无缝整合到目标场景中。这一方法无需为每个任务...图像模型# Insert Anything# 图像编辑11个月前01670
字节跳动推出新型图像编辑方法 SuperEdit :通过改进监督信号来提升基于指令的图像编辑性能字节跳动和佛罗里达中央大学计算机视觉研究中心的研究人员推出新型图像编辑方法 SuperEdit ,通过改进监督信号来提升基于指令的图像编辑性能。 项目主页:https://liming-ai.gith...图像模型# SuperEdit# 图像编辑# 字节跳动11个月前02920
浙江大学与哈佛大学联合推出高效图像编辑框架In-Context Edit:用自然语言指令轻松实现图像修改浙江大学和哈佛大学的研究人员联合推出了ICEdit(In-Context Edit),这是一个高效且强大的基于指令的图像编辑框架。 与传统方法相比,ICEdit 仅需 1% 的可训练参数(2 亿)和 ...图像模型# FLUX# ICEdit# In-Context Edit11个月前06480
谷歌 Gemini 聊天机器人升级图像编辑功能谷歌 Gemini 聊天机器人正在迎来一项重大升级,为用户带来更强大的图像编辑功能。根据谷歌周三发布的博客文章,Gemini 现在不仅支持用户修改 AI 生成的图像,还可以编辑从手机或电脑上传的图像...早报# Gemini# 图像编辑# 谷歌11个月前02030
新型指令式图像编辑框架FireEdit:利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑中山大学深圳校区、腾讯混元、清华大学和香港科技大学的研究人员推出新型指令式图像编辑框架FireEdit,它通过利用区域感知的视觉语言模型(VLM),实现了对用户指令的细粒度理解和精确图像编辑。Fire...新技术# FireEdit# 图像编辑# 视觉语言模型12个月前05570
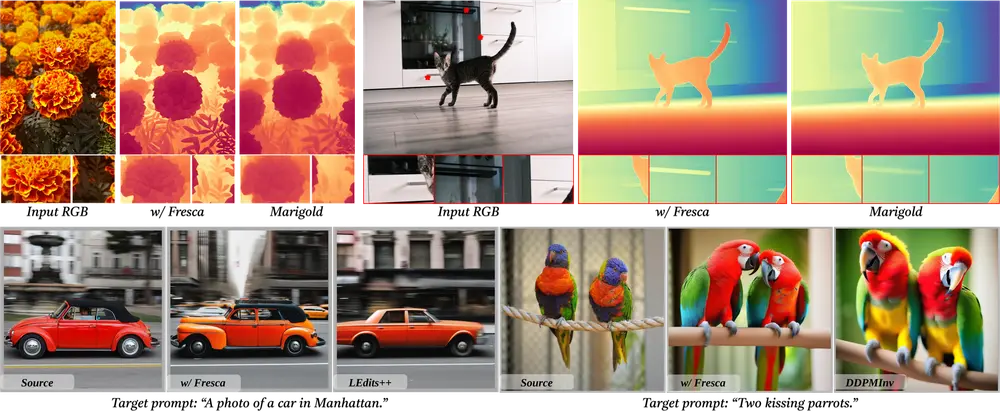
FreSca:用于增强扩散模型在图像编辑和图像理解任务中的性能罗切斯特大学、Netflix Eyeline Studios和德克萨斯大学达拉斯分校的研究人员推出 FreSca,用于增强扩散模型(Diffusion Models)在图像编辑和图像理解任务中的性能...新技术# FreSca# 图像理解# 图像编辑1年前03160
个性化图像生成和编辑方法SISO:适合在只有单张主题图像的情况下使用巴伊兰大学和英伟达的研究人员推出一种无需训练的方法SISO,用于从单张主题图像进行个性化图像生成和编辑。SISO 是一种无需训练的方法,通过优化与输入主题图像的相似度分数来实现图像的个性化生成和编辑...图像模型# SISO# 图像生成# 图像编辑1年前02060
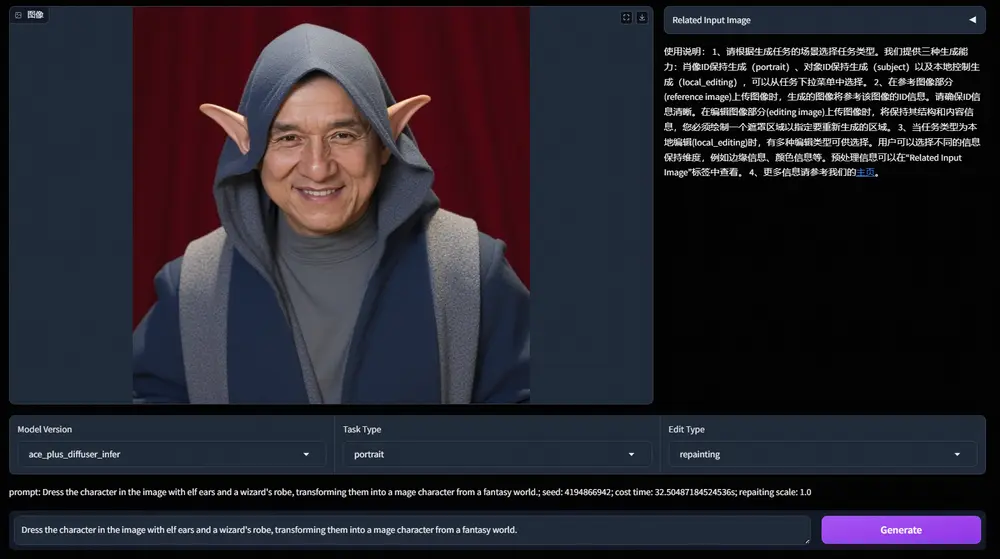
通义实验室推出基于指令的图像生成和编辑框架ACE++:基于FLUX.1-dev模型,实现多种图像生成和编辑任务阿里巴巴通义实验室推出基于指令的图像生成和编辑框架ACE++,这是之前介绍过的新型多模态生成模型ACE升级版,ACE++ 通过改进的长上下文条件单元(LCU++)和两阶段训练方案,能够高效地利用预训练...图像模型# ACE# FLUX.1-dev# 图像生成1年前03520
新型图像编辑框架PixelMan:基于扩散模型,通过像素操作和生成来实现一致性的对象编辑阿尔伯塔大学电子与计算机工程系、华为技术加拿大公司和华为麒麟解决方案的研究人员推出新型图像编辑框架PixelMan,它基于扩散模型(Diffusion Models, DMs),通过像素操作和生成来实...新技术# PixelMan# 图像编辑1年前03340