

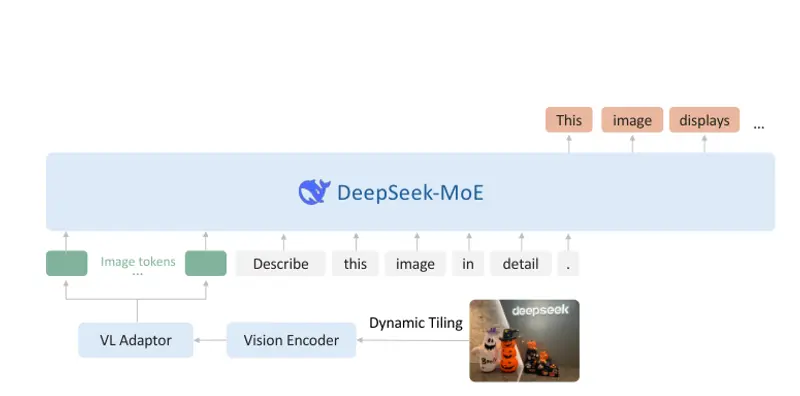
深度求索推出开源视觉模型DeepSeek-VL2 :支持动态分辨率、处理科研图表、解析各种梗图等
DeepSeek-VL2 是由深度求索(DeepSeek-AI)推出的一系列先进混合专家(MoE, Mixtur...
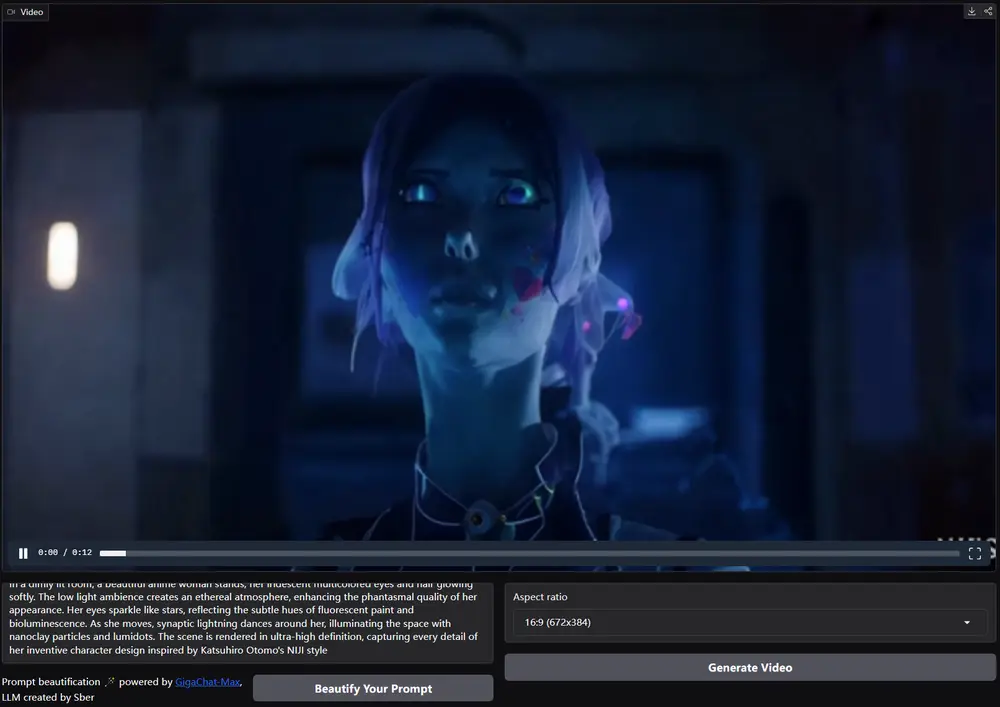
Sber AI 推出新一代多模态生成模型Kandinsky 4.0:包含3个视频生成模型(T2V、T2V Flash、I2V)和一个视频生成音频模型(V2A)
去年,在 AI Journey 2023 大会上,Sber AI 推出了两款引人注目的模型:用于图像生...

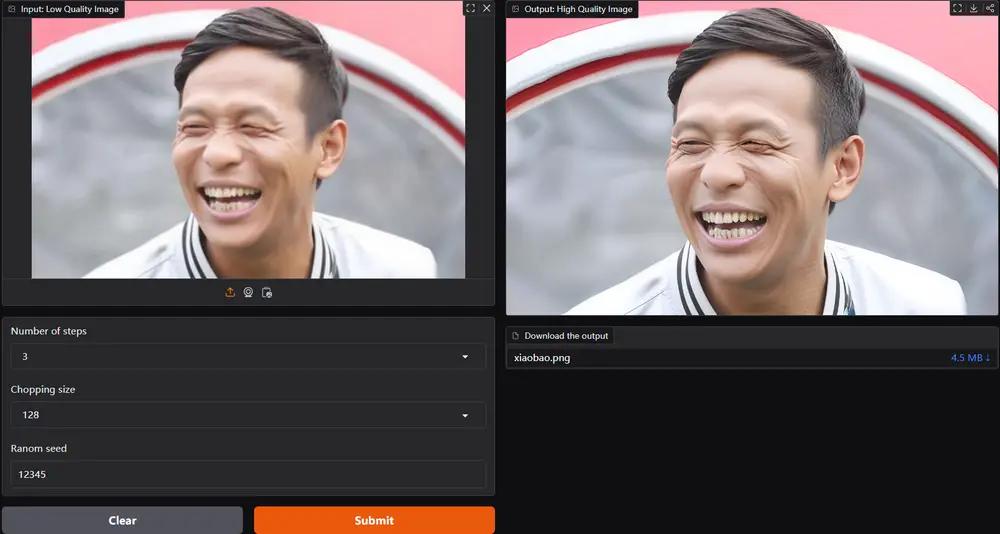
图像超分辨率技术InvSR:基于扩散反转(Diffusion Inversion)来提高图像的分辨率
南洋理工大学(NTU)S-Lab提出了一种新的图像超分辨率(Super-Resolution, SR)技...


人体图像动画生成DisPose:从参考图像和驱动视频中生成视频,同时保持人物外观的一致性,并允许对动画进行精确控制
可控的人体图像动画旨在使用驱动视频从参考图像生成视频。为了确保运动对齐,最近...

多模态大语言模型Lyra:专注于增强多模态能力,特别是高级长语音理解、声音理解、跨模态效率和无缝语音交互
随着多模态大语言模型(MLLMs)的发展,扩展到单一领域之外的能力对于满足更通用和...


Neural LightRig:从单张图片中准确估计物体的表面法线(normals)和物理基础渲染(PBR)材料
香港中文大学、上海AI实验室和南洋理工大学的研究人员推出新型框架Neural LightRig...
