Midjourney 推出全新外部图像编辑功能、图像重新纹理化以及下一代AI审查系统
由前 Magic Leap 工程师 David Holz 创立的 AI 图像生成初创公司Midjourney,昨晚...


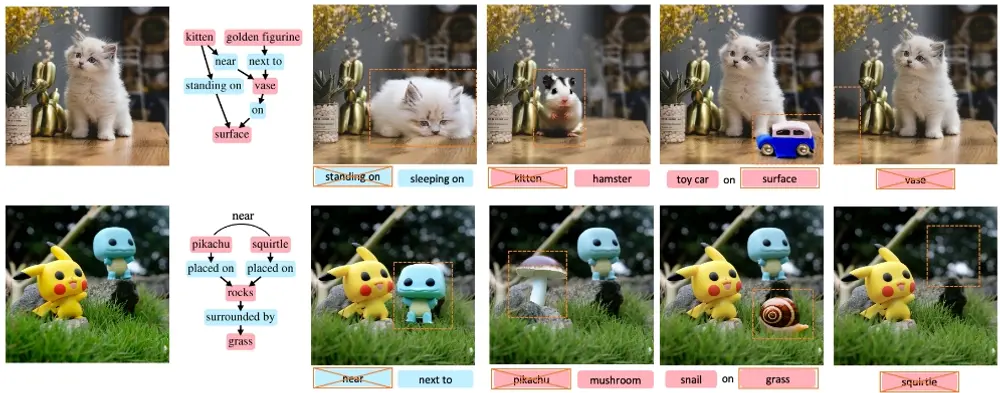
新型多模态大语言模型PUMA:不仅能理解文本指令,还能根据这些指令创作出精细的图像,或者对现有图像进行精确的编辑
近年来,多模态基础模型在视觉-语言理解领域取得了显著进展,同时也开始探索多模态...

重塑创意工作流程!Ideogram 推出无限画布Canvas功能,用于操作和组合生成的图像
Ideogram 是一家由前 Google Brain AI 研究人员创立的加拿大初创公司,以其能够生...
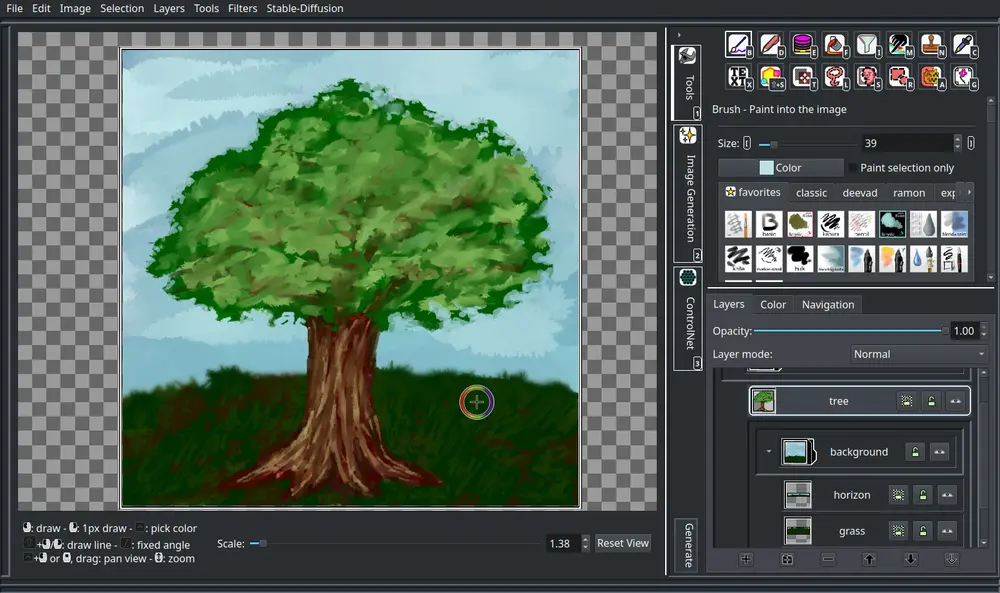
免费且开源的桌面图像编辑器IntraPaint:将传统数字绘画艺术技术与 AI 修复相结合
IntraPaint 是一款免费且开源的桌面图像编辑器,专为 Windows 和 Linux 用户设计。...
![LibreFLUX:基于FLUX.1 [schnell]的免费、开源、去蒸馏FLUX 模型](https://pic.sd114.wiki/wp-content/uploads/2024/10/1729674970-LibreFLUX.webp~tplv-o4t1hxlaqv-image.image)
LibreFLUX:基于FLUX.1 [schnell]的免费、开源、去蒸馏FLUX 模型
LibreFLUX是基于FLUX.1 [schnell] 的去蒸馏版本,旨在提供完整的 T5 上下文长度支...
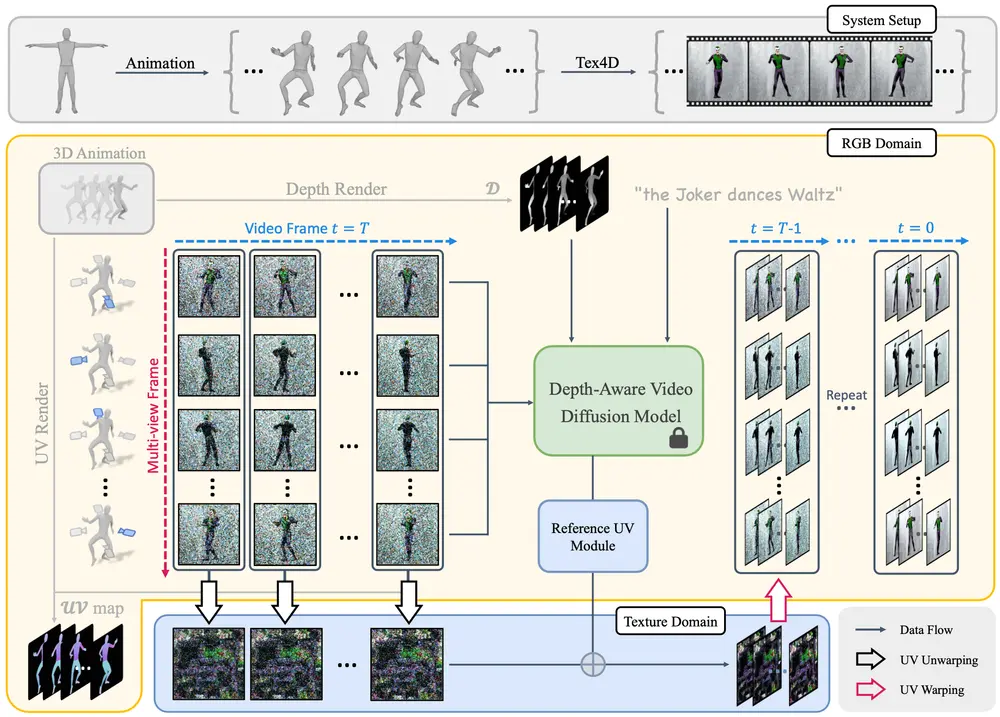
4D 场景纹理化Tex4D:使用视频扩散模型为未纹理化的动画网格序列生成多视图、时间一致的 4D 纹理
来自香港中文大学(深圳)、NVIDIA 和加州大学默塞德分校的研究人员开发了 Tex4D,...