HunyuanVideo是腾讯开源的一个参数量超过130亿的大型视频生成模型,ComfyUI官方发布博文宣布原生支持HunyuanVideo,相较于之前介绍的《混元文生视频模型HunyuanVideo的ComfyUI插件》,原生支持对于硬件要求更低,问题更少,虽然功能不如第三方节点多,但还是建议非英伟达RTX4090用户,使用官方原生节点。
- 模型:https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged (显存大于12G的用户,从此处下载模型)
- 模型:https://huggingface.co/Kijai/HunyuanVideo_comfy(显存在12G或12G以下的用户,从此处下载模型)
HunyuanVideo 亮点
1. 统一图像与视频生成:HunyuanVideo 采用“双流到单流”Transformer架构,能够高效融合文本和视觉信息,显著增强了运动一致性、图像质量和对齐效果。这种设计使得生成的视频不仅在视觉上更加连贯,还能更好地捕捉文本描述中的细节。
2. 卓越的文本-视频对齐:HunyuanVideo 配备了先进的MLLM(多模态语言模型)文本编码器,性能优于CLIP和T5等传统模型。这使得它在指令跟随、细节捕捉和复杂推理方面表现出色,确保生成的视频内容与输入的文本提示高度一致。
3. 高效视频压缩:通过自定义的3D VAE(变分自编码器),HunyuanVideo 能够将视频压缩到紧凑的潜在空间中,同时保持高分辨率和帧率。这一技术减少了token的数量,从而提高了生成效率,同时确保视频质量不受影响。
4. 增强的提示控制:HunyuanVideo 提供了两种提示模式,帮助用户根据需求生成不同风格的视频:
- 普通模式:适用于大多数用户,能够准确解释用户的意图,生成符合预期的视频。
- 大师模式:专为追求高质量和创意的专业用户设计,优化了构图、光线和视觉质量,生成更具艺术感的作品。
在 ComfyUI 中使用 HunyuanVideo
HunyuanVideo 现已原生支持 ComfyUI,您可以无缝生成视频和静态图像。以下是详细的使用步骤:
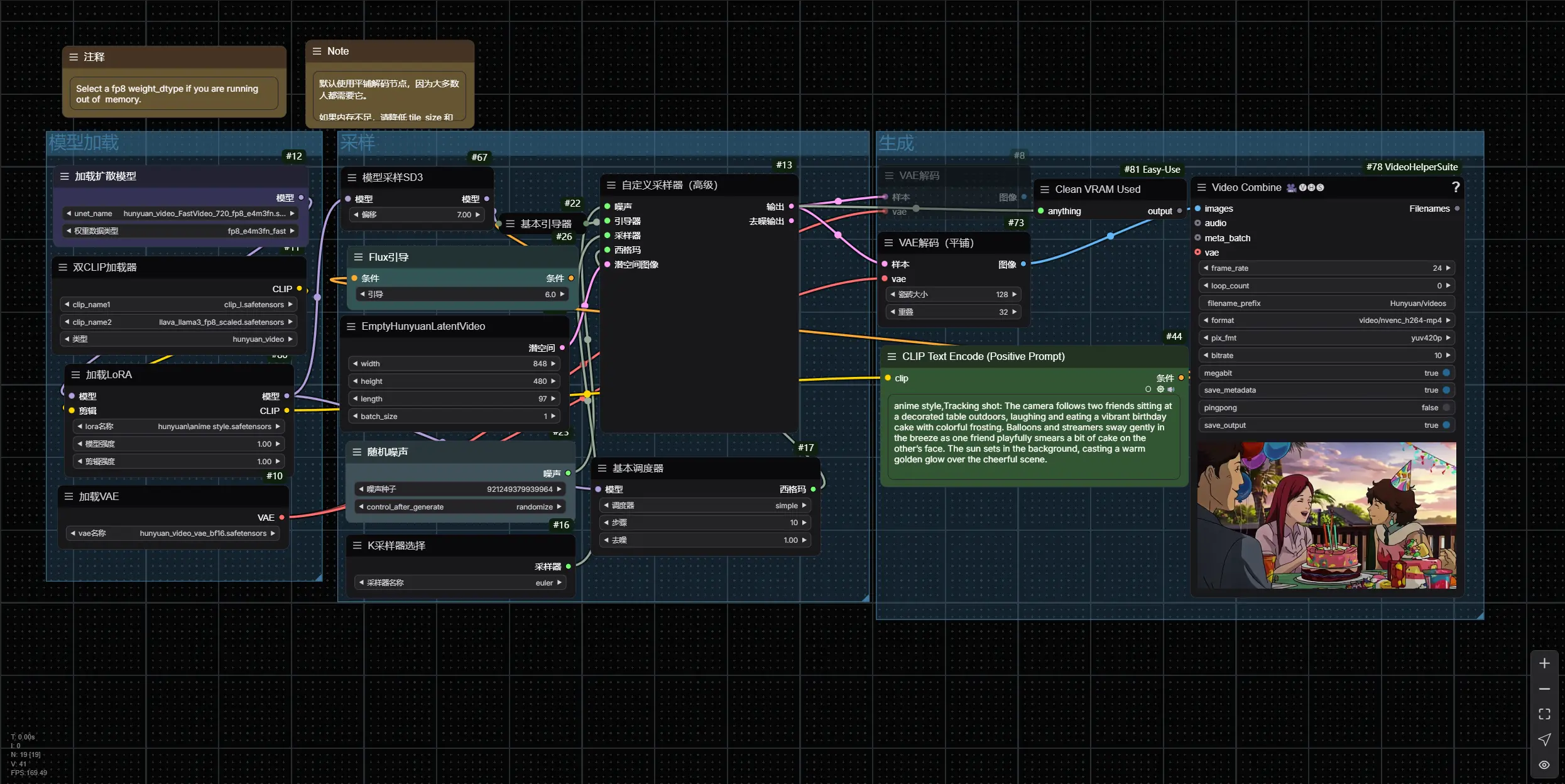
文本到视频示例工作流程
1、更新 ComfyUI
- 确保您已安装并更新到最新版本的 ComfyUI
2、下载模型文件
下载以下模型文件,并将其放置在指定的目录中:
hunyuan_video_t2v_720p_bf16.safetensors→ 放置在ComfyUI/models/diffusion_modelsclip_l.safetensors和llava_llama3_fp8_scaled.safetensors→ 放置在ComfyUI/models/text_encodershunyuan_video_vae_bf16.safetensors→ 放置在ComfyUI/models/vae
3、加载工作流程
- 将提供的
workflow JSON文件加载到 ComfyUI 中,或直接拖放到界面中
4、生成视频
- 输入您的文本提示,并调整其他参数(如视频长度、分辨率等)
- 点击“生成”按钮,等待模型生成视频
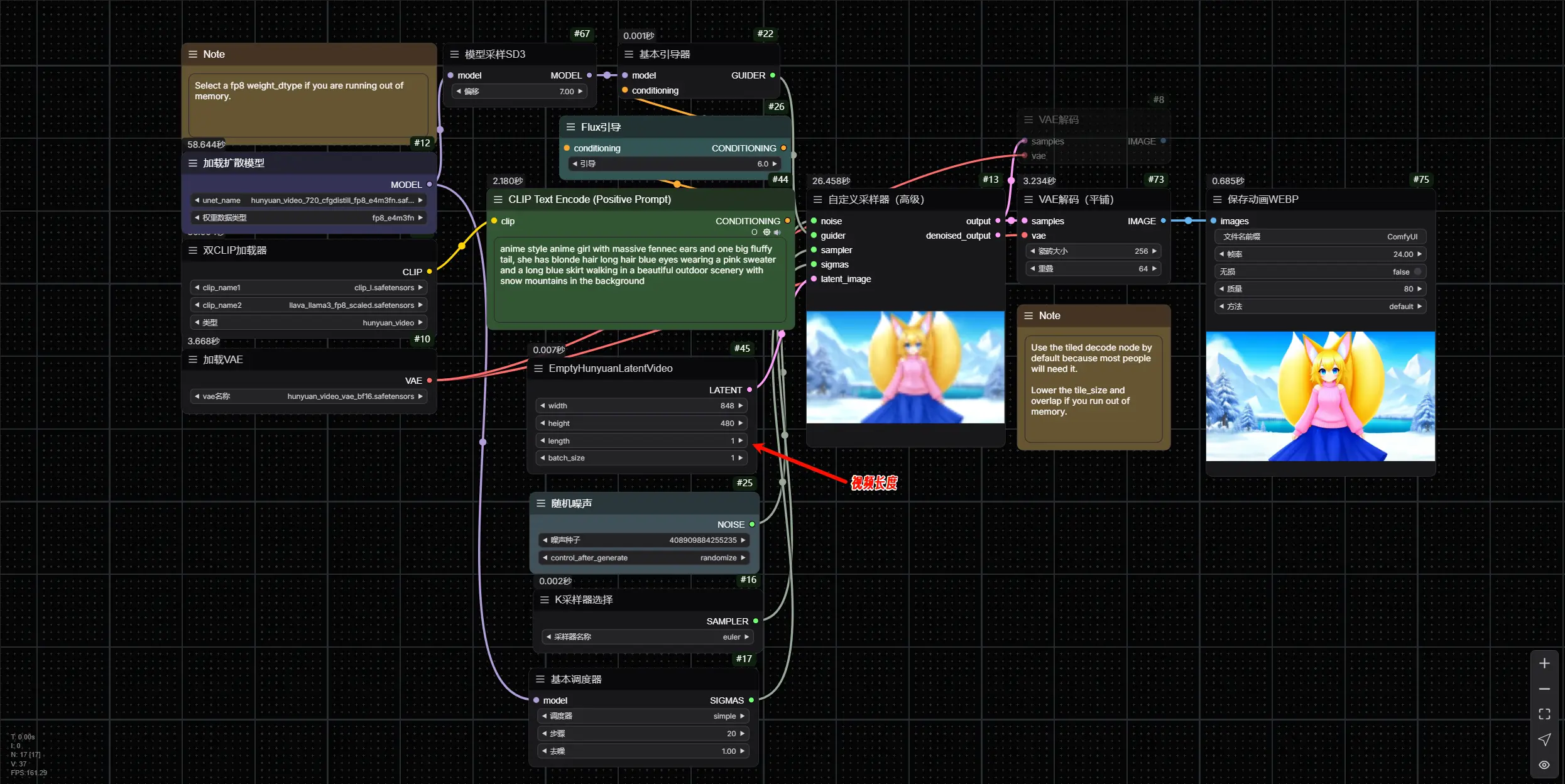
使用相同工作流程生成静态图像
如果您想生成静态图像,只需将视频长度设置为 1。这样,HunyuanVideo 会生成一张静态图像,而不是一段视频。这使得该模型不仅可以用于视频生成,还能轻松生成高质量的静态图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











