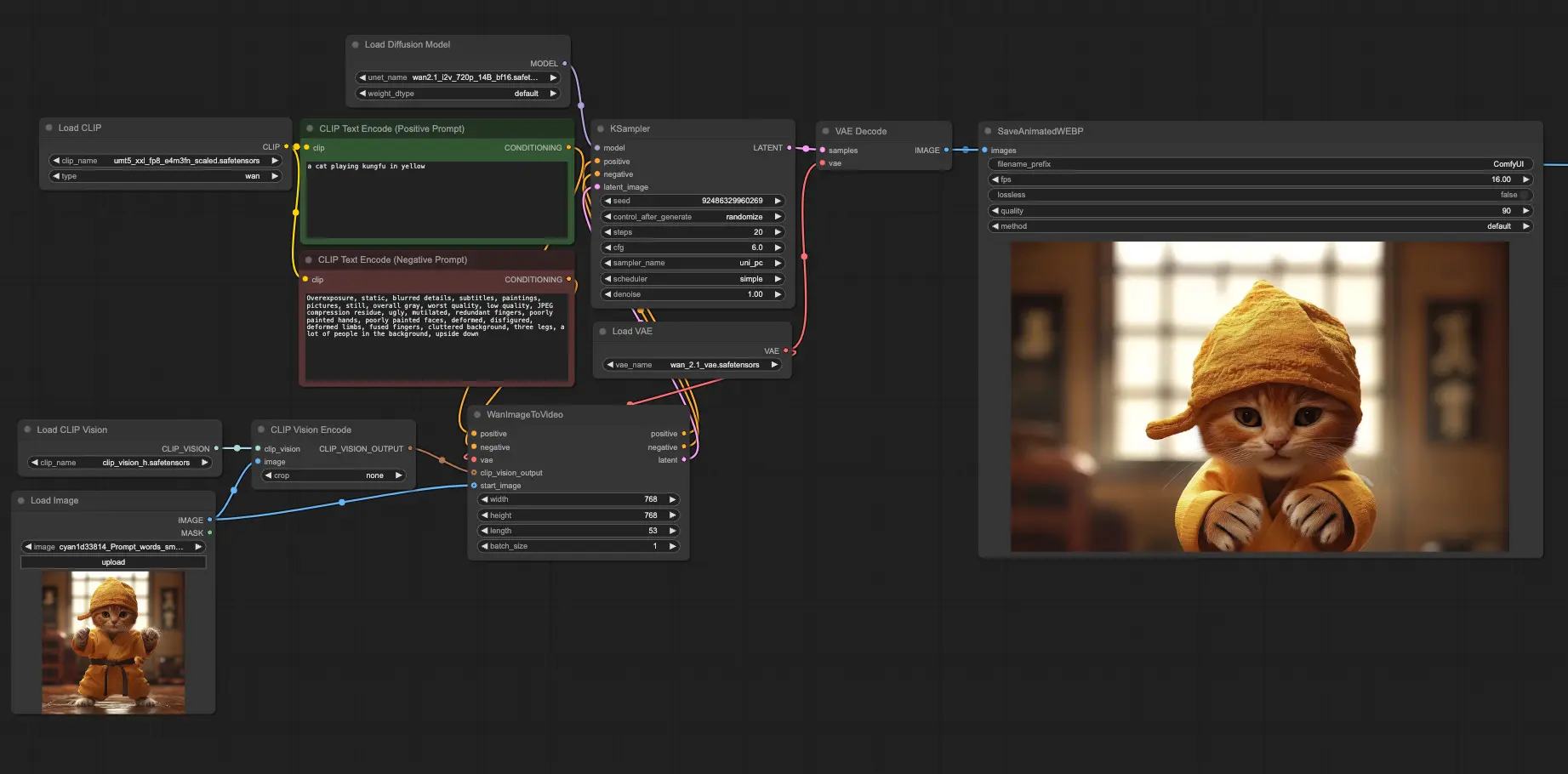
LTX-Video 是一个仅20亿参数的基于DiT架构的视频生成模型,因为其占用硬件资源低,也颇受欢迎,而近期推出的新型采样引导方法STG也让生成的视频清晰度上升了一大截,今天分享的这个工作流是由reddit网友根据Civitai网友tremolo28的LTX IMAGE to VIDEO工作流打造,而本人又对此工作流做了节点删减和替换,此工作流基于 LTX Videos 和 STG ,可轻松创建高质量、动感丰富的视频。
- 工作流地址:GitHub/Civitai
- 备份:https://www.123684.com/s/I1oZVv-xnbGA 提取码:rxx2
主要功能:
- 快速高效的动态图像生成:将静态图像转换为 3-6 秒的动态图像,使用本地 GPU 确保速度和质量。
- 先进的自动提示词和视频提示生成器:结合 Florence2 和 Llama3.2 的图像到视频提示生成功能,通过自定义 ComfyUI 节点实现。只需上传一张图片,工作流即可基于它生成令人惊叹的动态图像。
- 支持用户自定义指令:包含一个可选的用户输入节点,允许你添加特定指令,进一步定制生成内容,调整风格、主题或叙事以匹配你的需求。
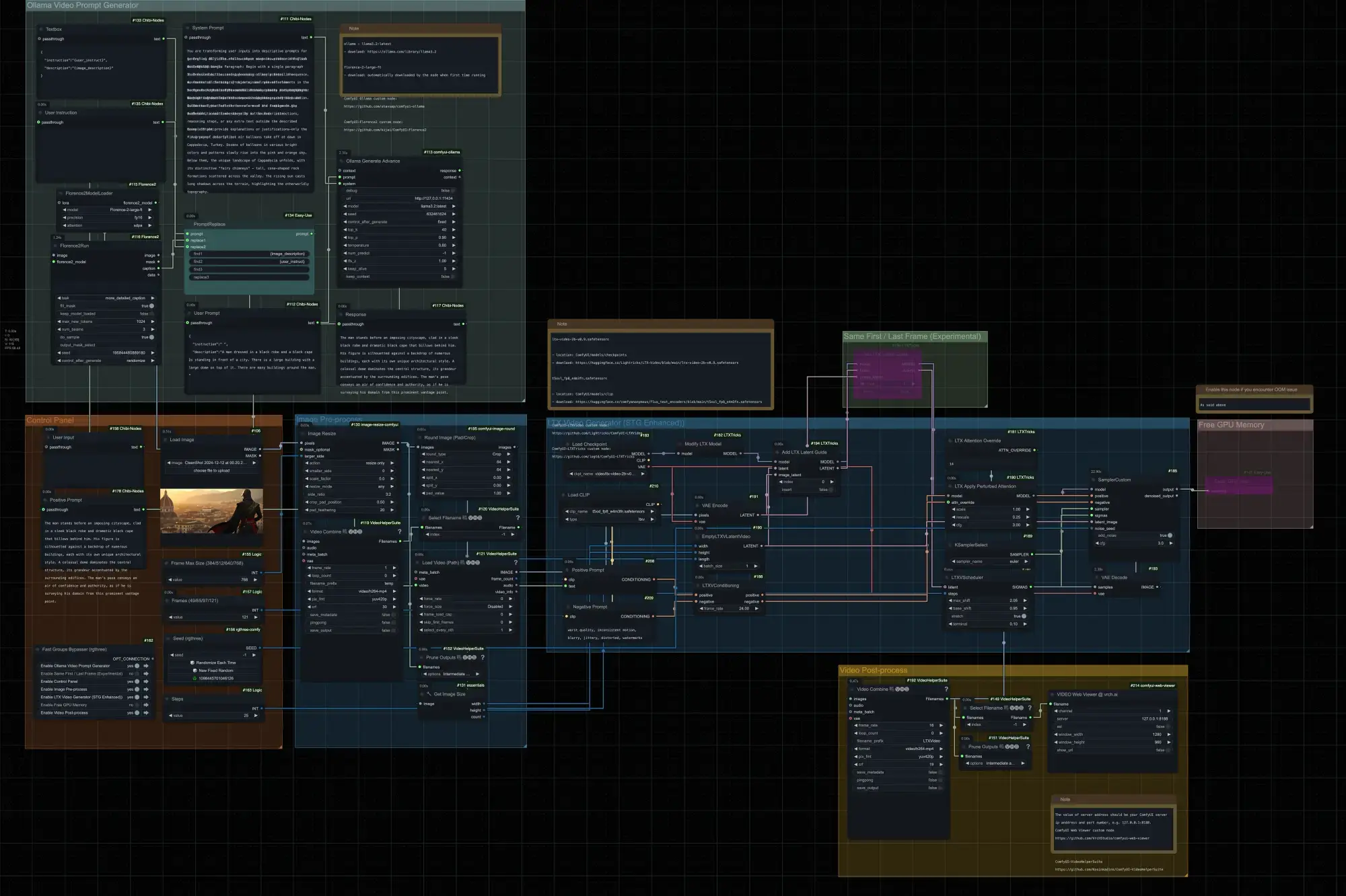
准备工作
1、下载工具和模型
- Ollama - Llama3.2:https://ollama.com/library/llama3.2
- Florence-2-Large-FT:首次使用时自动下载。
- LTX-Video-2B v0.9:https://huggingface.co/Lightricks/LTX-Video/blob/main/ltx-video-2b-v0.9.safetensors(位置: ComfyUI/models/checkpoints)
- T5XXL_FP8_E4M3FN:https://huggingface.co/comfyanonymous/flux_text_encoders/blob/main/t5xxl_fp8_e4m3fn.safetensors(位置: ComfyUI/models/clip)
2、安装 ComfyUI 自定义节点
注意:你可以使用 ComfyUI Manager 直接在 ComfyUI 网页中安装这些节点,其他缺失节点也可通过ComfyUI Manager 来进行安装
- ComfyUI Ollama:https://github.com/stavsap/comfyui-ollama
- ComfyUI Florence2: https://github.com/kijai/ComfyUI-Florence2
- ComfyUI LTXVideo: https://github.com/Lightricks/ComfyUI-LTXVideo
- ComfyUI LTXTricks:https://github.com/logtd/ComfyUI-LTXTricks
- ComfyUI Video Helper Suite: https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
如何使用
1、在 ComfyUI 中运行工作流
运行此工作流时,可以在控制面板中调整以下关键参数:
Frame Max Size(帧最大分辨率):设置生成帧的最大分辨率(例如:384、512、640、768)。 Frames(帧数):控制动态图像中的总帧数(例如:49、65、97、121)。 Steps(迭代次数):指定每帧的迭代次数;更高的步数可以提高质量,但会增加处理时间。 User Input(用户输入,可选):允许用户输入额外指令以自定义生成内容,直接影响输出的风格和主题。注意:测试表明用户输入可能并不总是有效。
使用这些设置在 ComfyUI 的控制面板组中调整工作流,以获得最佳效果。
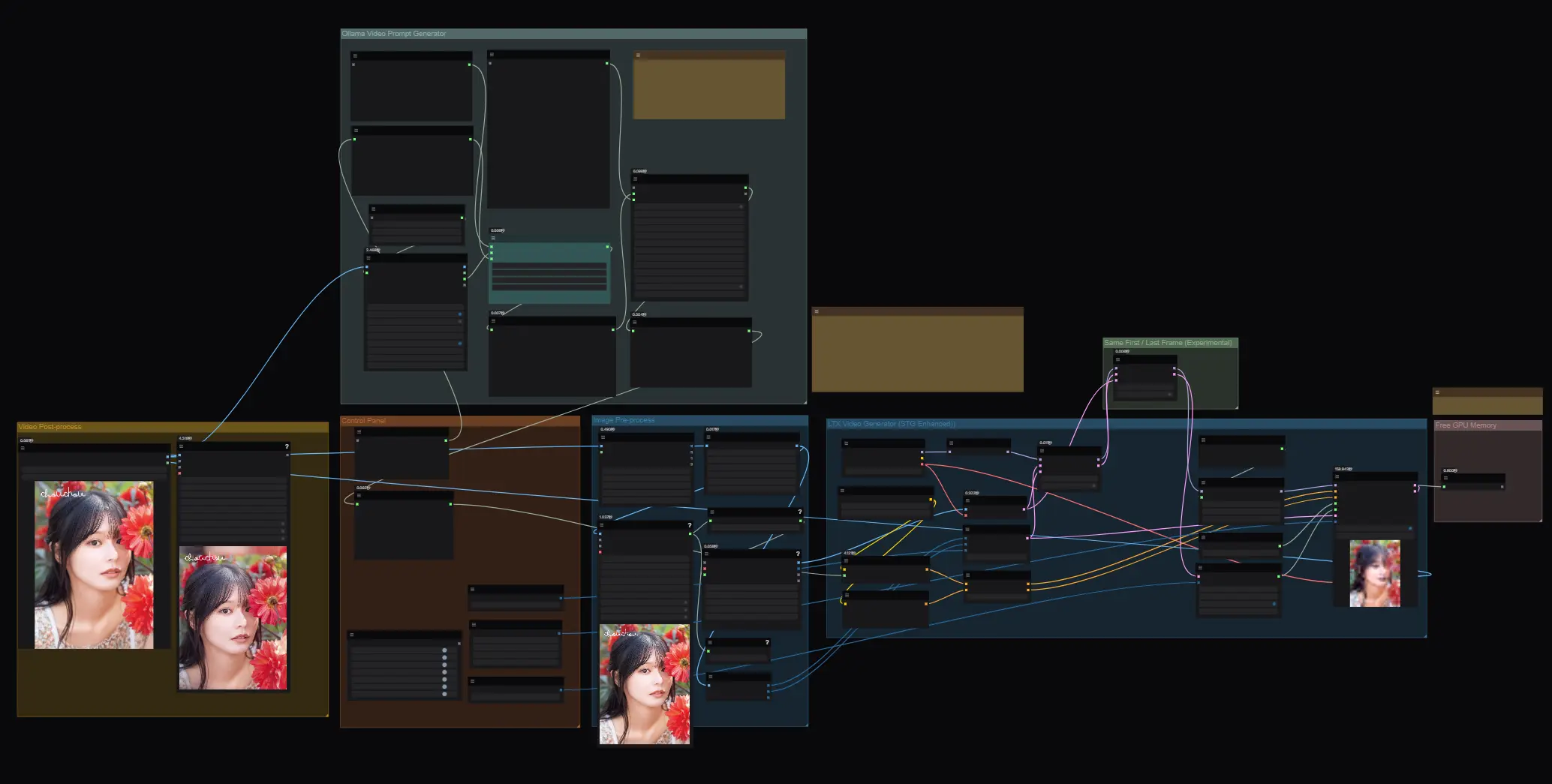
2、分步骤讲解
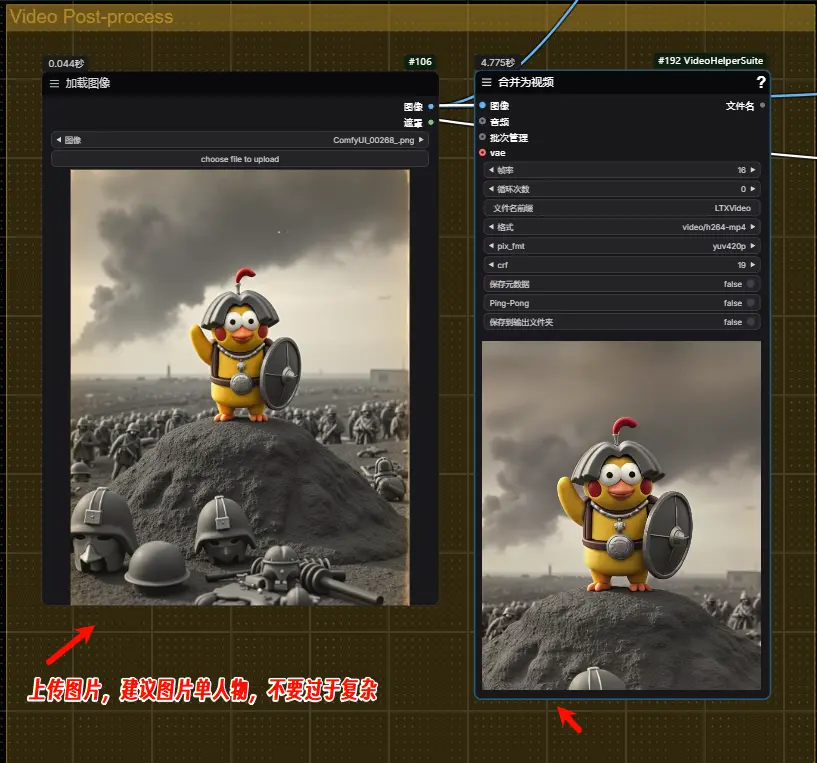
上传图片,图片里的人物、背景等不易复杂,最后生成视频处可调整帧率,应该根据自己的显存情况来设置
通过视觉语言模型Florence2来生成图片描述,再通过Ollama+LLM(大语言模型)来将图片描述优化转换为适合生成视频的提示词

由LTX模型能力的限制,图片尺寸过大会直接爆显存或无法生成,因此需要将图片缩放到指定尺寸,建议的宽度是768;将图片转换为0帧视频后,利用LTX模型来进行视频转视频
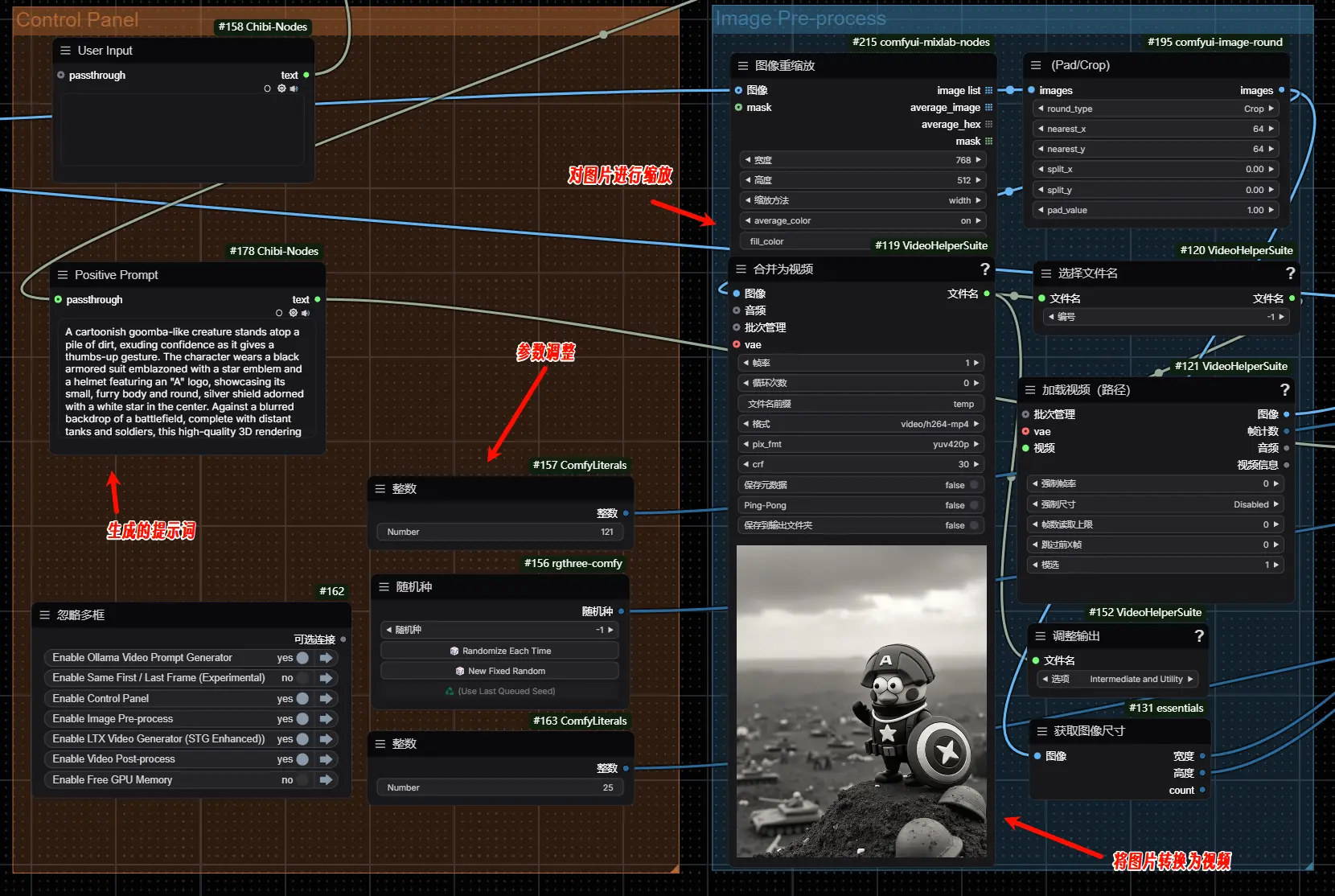
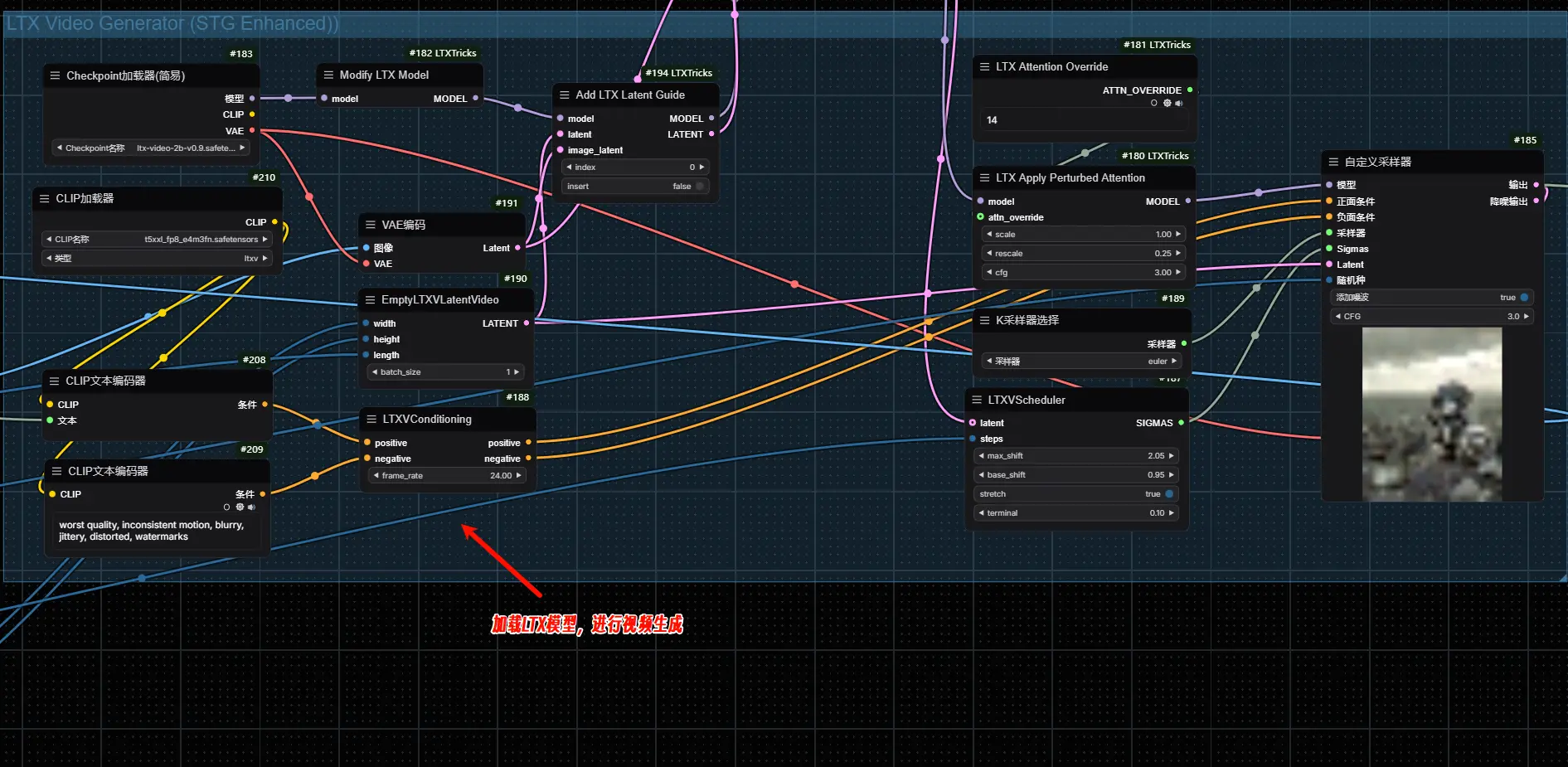
LTX模型+STG来进行视频生成,经过STG可生成更大、质量更高的视频
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











