
在现代人工智能的基石——GPU 加速计算领域,编写高性能 CUDA 内核 一直是一项只有少数人类专家才能掌握的“黑魔法”。尽管大语言模型在普通编程上表现优异,但在涉及底层硬件架构、内存管理和并行计算的 CUDA 优化任务中,它们往往束手无策,甚至不如传统的自动编译工具(如 torch.compile)。
- 项目主页:https://cuda-agent.github.io
- GitHub:https://github.com/BytedTsinghua-SIA/CUDA-Agent
字节跳动 Seed 团队 与 清华大学智能产业研究院(AIR) 联合推出了 CUDA Agent。这是一个基于大规模强化学习训练的智能体,它不仅能自动编写 CUDA 代码,更能像人类专家一样进行多轮调试、分析和优化,最终生成的内核在性能上全面超越工业级编译器,确立了 AI 系统级优化的新标杆。
核心突破:AI 不再是“代码生成器”,而是“优化工程师”
CUDA Agent 的核心价值在于它突破了传统 AI 编程的局限,实现了真正的自主优化闭环:
1. 全栈自动化能力
- 🔍 瓶颈分析:自动剖析 PyTorch 模型,精准定位计算热点与低效算子。
- 💻 内核编写:从零生成包含 CUDA 核心逻辑、Python 绑定及构建脚本的完整工程。
- 🐞 自动调试:自主编译、运行测试用例,验证数值正确性,并处理编译错误。
- 🔄 多轮迭代:根据性能反馈(Profiling 数据)和报错信息,像人类工程师一样反复修改代码,直至达到最优。
- 🧩 算子融合:智能识别可合并的计算步骤(如 Matrix Mul + Activation),减少显存搬运与 Kernel 启动开销。
- ⚙️ 硬件感知:针对特定 GPU 架构(如 NVIDIA H100/A100)自动启用 Tensor Core、调整 Block/Thread 配置。
2. 真正的自主决策
与传统“固定流程”(写→编→测→改)不同,CUDA Agent 通过强化学习学会了动态决策:它自己决定何时该查阅文档、何时该尝试激进优化、何时该回退策略。这种灵活性使其能应对前所未有的复杂场景。
技术亮点:如何训练出“不作弊”的专家?
训练 AI 编写底层系统代码面临巨大挑战:数据稀缺、奖励难定义、训练易崩溃。CUDA Agent 通过一系列创新设计解决了这些问题:
防作弊的严格环境
为了防止模型走捷径(如直接调用现成库、修改测试脚本),团队构建了沙盒隔离环境:
- 权限锁定:AI 只能修改自己的源码文件,严禁触碰测试脚本和评估逻辑。
- 多重验证:必须通过多个随机输入的正确性测试,且性能必须优于基线,才能获得奖励。
- 杜绝蒙混:禁止直接调用高层 PyTorch 函数,强制要求手写 CUDA 核函数。
稳定的超长训练策略
针对 CUDA 数据稀缺(预训练占比<0.01%)导致的训练崩溃问题,团队设计了三阶段渐进式训练:
- 单轮预热 (Warm-up):先让模型学会“一锤子买卖”,掌握基本语法和简单并行逻辑。
- 拒绝采样微调 (RSF):利用预热模型生成大量多轮交互轨迹,筛选出成功的高质量案例进行监督微调,让模型“观摩”专家解题过程。
- 多轮强化学习 (RL):引入价值网络 (Critic) 预热,先教会“评论家”评估动作好坏,再让模型在完整环境中自主探索。这使得模型能稳定训练 150+ 步,支持长达 12.8k Token 上下文和 200 轮交互。
鲁棒的奖励设计
摒弃简单的“速度倍数”奖励(容易被简单任务扭曲),采用里程碑式奖励机制:
- 正确运行:获得基础分。
- 超越基线 5%:获得额外加分。
- 超越编译器优化版 5%:获得高额奖励。
这种设计引导模型专注于攻克那些编译器都搞不定的“硬骨头”。
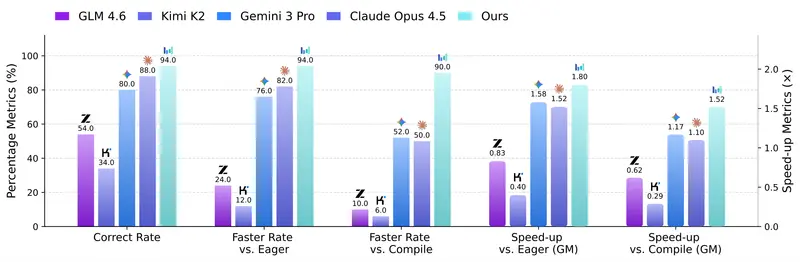
实测表现:碾压最强基线,超越工业编译器
在权威的 KernelBench 测试集上,CUDA Agent 展现了统治级的性能:
| 指标 | CUDA Agent | Claude Opus 4.5 | Gemini 3 Pro | torch.compile (工业编译器) |
|---|---|---|---|---|
| 代码通过率 | 98.8% | 95.2% | 91.2% | - |
| 优于编译器比例 | 96.8% | 66.4% | 69.6% | - |
| 几何平均加速比 | 2.60x (vs 原生) 2.11x (vs 编译器) | - | - | 1.0x (基准) |
分级表现亮点
- Level-1 (基础):100% 任务优于编译器,平均加速 1.87x。
- Level-2 (中等·算子融合):100% 任务优于编译器,平均加速 2.80x。这是编译器的弱项,却是 AI 的强项,它能发现跨操作的代数简化机会。
- Level-3 (困难·复杂模块):90% 任务优于编译器,平均加速 1.52x。而在同一级别,Claude 和 Gemini 的优胜率仅约 50%。
经典优化案例
- 对角矩阵乘法:AI 发现数学等价性,将复杂的矩阵运算简化为逐行缩放,加速 73 倍。
- 多操作融合:将矩阵乘、除、求和、缩放四步合并为两步,利用代数律减少计算量,加速 24 倍。
- ResNet 模块:自动折叠 BatchNorm 参数,调用 cuDNN 融合 API 并启用 Tensor Core,加速 3.6 倍。
应用前景:重塑 AI 基础设施
CUDA Agent 的出现不仅仅是编程工具的升级,更是 AI 基础设施的一次革命:
- 框架自动进化:PyTorch/TensorFlow 可利用它自动优化成千上万个算子,减少对人类专家的依赖,加速框架迭代。
- 定制化加速:针对特定大模型架构(如 MoE、新型 Attention),自动生成极致优化的内核,挖掘硬件最后一滴性能。
- 降低门槛:中小企业无需组建昂贵的 CUDA 专家团队,即可享受顶尖水平的性能优化。
- 硬件迁移助手:当新一代 GPU 发布时,自动迁移并重新优化现有代码库,大幅降低维护成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











