在构建企业级大语言模型应用时,开发者们往往面临一个两难困境:为了让模型懂业务、守规矩,必须编写长达数千字的系统提示(System Prompt),注入公司政策、领域知识和安全约束;但这些冗长的上下文不仅显著推高了每次查询的成本,更让推理延迟变得难以忍受。
“能不能把这些知识直接‘烧录’进模型脑子里,而不是每次对话都重新念一遍?”
微软亚洲研究院最新提出的 “同策略上下文蒸馏”(On-Policy Context Distillation, 简称 OPCD) 框架,正是为了解决这一痛点而生。这项技术能让模型在训练阶段直接内化复杂的业务规则和安全约束,从而在推理时彻底摆脱对长提示的依赖,实现速度与性能的双重飞跃。
- 论文:https://arxiv.org/pdf/2602.12275
为什么长系统提示成了企业的“不可承受之重”?
上下文学习(In-Context Learning)虽然灵活,但在企业规模化应用中弊端尽显:
- 高昂的成本:每次请求都要重复发送数万 Token 的公司手册或安全规范,Token 消耗量巨大。
- 致命的延迟:处理长上下文需要更多的计算时间,导致用户等待时间过长,体验下降。
- 短暂的记忆:上下文知识无法跨对话持久化,每次会话都要“从头教起”。
微软研究员田天竺指出:“企业常用长提示来强制执行安全约束(如仇恨言论检测)或提供专业知识(如医疗建议),但这显著增加了计算开销和延迟。”
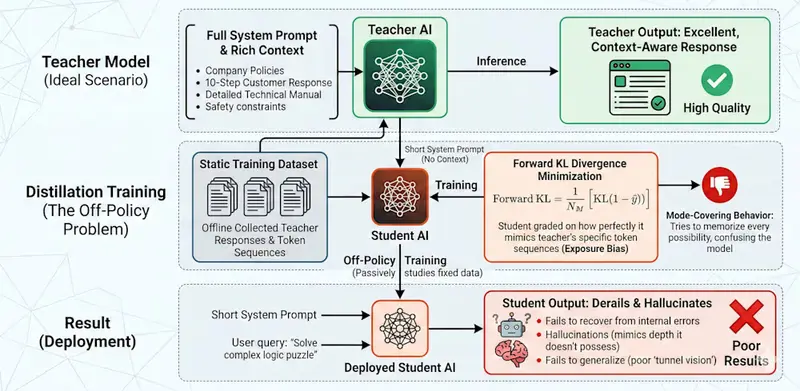
传统的上下文蒸馏技术试图通过将“教师模型”(带长提示)的知识迁移给“学生模型”(无长提示)来解决此问题,但往往陷入两个陷阱:
- 暴露偏差(Exposure Bias):传统方法使用静态数据集训练(离策略),学生模型只见过“标准答案”,从未练习过如何从自己的错误中恢复。一旦部署,稍有偏差便容易“翻车”。
- 覆盖模式(Covering Mode):为了模仿教师的复杂分布,学生模型往往被迫做出过于宽泛的猜测,导致幻觉频发,甚至自信地编造内容。
OPCD 的核心突破:从“看视频学车”到“上路实战”
OPCD 的革命性在于它将训练过程从**“离策略”(Off-Policy)转变为“同策略”(On-Policy)**。
- 旧模式(看视频):学生模型被动观看教师模型在完美上下文下的输出,缺乏自主决策练习。
- OPCD 新模式(上路实战):
- 学生独立生成:学生模型在没有长提示的情况下,尝试独立完成任务,生成自己的回答轨迹。
- 教师实时指导:拥有完整上下文知识的教师模型,对学生生成的每一步进行实时评估。
- 反向 KL 散度优化:这是关键所在。OPCD 使用**反向 KL 散度(Reverse KL Divergence)**作为损失函数。
- 它不强迫学生去覆盖教师所有可能的输出(这会导致宽泛和幻觉)。
- 它鼓励学生专注于自己认为高概率的区域,并抑制那些学生认为不可能、但教师认为可能的 token。
- 结果:学生模型学会了“自我纠错”,其输出分布更加聚焦、准确,有效避免了幻觉。
正如田天竺所言:“这就像让学生亲自开车,并在犯错时即时纠正,而不是只看教学视频。”
实测数据:性能飙升,且不忘本
研究人员在多个基准测试中验证了 OPCD 的威力,结果令人瞩目:
1. 经验知识内化:小模型也能变专家
- 数学推理:一个 8B 参数的模型,在通过 OPCD 内化了过去的解题经验后,准确率从 75.0% 提升至 80.9%。
- 复杂导航:在“冰冻湖”游戏中,一个仅 1.7B 参数的小模型,成功率从可怜的 6.3% 跃升至 38.3%。这意味着小模型也能通过内化经验,具备解决复杂问题的能力。
2. 系统提示蒸馏:安全与专业性的质变
企业最关心的安全合规与领域专业性,提升更为显著:
- 安全与毒性检测:一个 3B 参数的 Llama 模型,在基础状态下安全评分仅为 30.7%。经过 OPCD 内化安全提示后,准确率飙升至 83.1%。
- 医学问答:同一模型在医学任务上的得分从 59.4% 提升至 76.3%。
3. 拒绝“灾难性遗忘”
微调最怕的是“顾此失彼”——学会了新规则,忘了旧知识。测试显示,OPCD 在将严格的安全规则内化后,模型在无关医学问题上的通用能力不仅未下降,反而比传统离策略方法高出约 4 个百分点。这证明了 OPCD 能在专业化的同时,完美保留模型的通用智能。
落地前景:低门槛、易集成
对于企业而言,OPCD 不仅效果好,而且落地成本极低:
- 硬件亲民:复现研究结果仅需约 8 块 A100 GPU,无需超算集群。
- 数据需求少:经验蒸馏仅需约 30 个种子示例;系统提示蒸馏可直接利用现有的优化提示和标准数据集。
- 无缝集成:OPCD 可轻松集成到现有的 RLVR(强化学习)工作流中,基于开源库
verl即可实现,无需重构架构。
未来展望:从“训练时智能”到“测试时进化”
OPCD 的意义远超单纯的提示压缩。它代表了一种范式转变:
“模型的核心改进将从训练时转移到测试时。” —— 田天竺
未来,部署后的模型可以通过与真实用户的交互,自动提取成功经验,并利用 OPCD 不断自我更新参数。模型将不再是静态的产品,而是一个能在使用中持续进化、越用越聪明的生命体。
虽然 OPCD 不能完全取代 RAG(针对动态更新的海量数据库),但对于那些需要固化静态知识、安全规范和领域专家行为的场景,它无疑是当前最优解。
随着微软计划开源其实现代码,我们有理由相信,一场关于“模型内化能力”的技术革命即将在企业级 AI 应用中爆发。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











