在《如何在本地安装及使用Ollama,轻松玩转本地大语言模型》这篇文章里,已经详细向大家介绍了Ollama这款软件如何安装及使用,虽然官方的模型库已经提供了大量可用模型,但与Hugging Face上的模型数量还是不能比,今天将教你如何从 Hugging Face 导入新模型并创建自定义 Ollama 模型。

开始前,请确保您已满足以下条件:
- 系统已安装 Ollama
- 拥有 Hugging Face 账号(用于下载GGUF格式模型)
- 具备足够的内存/显存以加载模型(对于 1.6B 参数模型,建议至少 16GB)
GGUF格式简介
GGUF(GPT-Generated Unified Format)是一种针对大规模机器学习模型设计的二进制格式文件规范,由开发者Georgi Gerganov(llama.cpp的创始人)提出。GGUF的主要优势在于能够将原始的大模型预训练结果经过特定优化后转换成这种格式,从而可以更快地被载入使用,并消耗更低的资源。
GGUF 通过增加可扩展性、向后兼容性和元数据支持,改进了旧的 GGML 格式。它采用量化等技术,将模型张量和标准化的元数据编码到单一文件中,以减小模型体积,同时保持性能。GGUF 在开源机器学习社区中迅速流行,得到如 llama.cpp、LM Studio、Jan等流行工具的支持。
如何导入新模型并创建自定义 Ollama 模型
1、下载 GGUF 格式模型
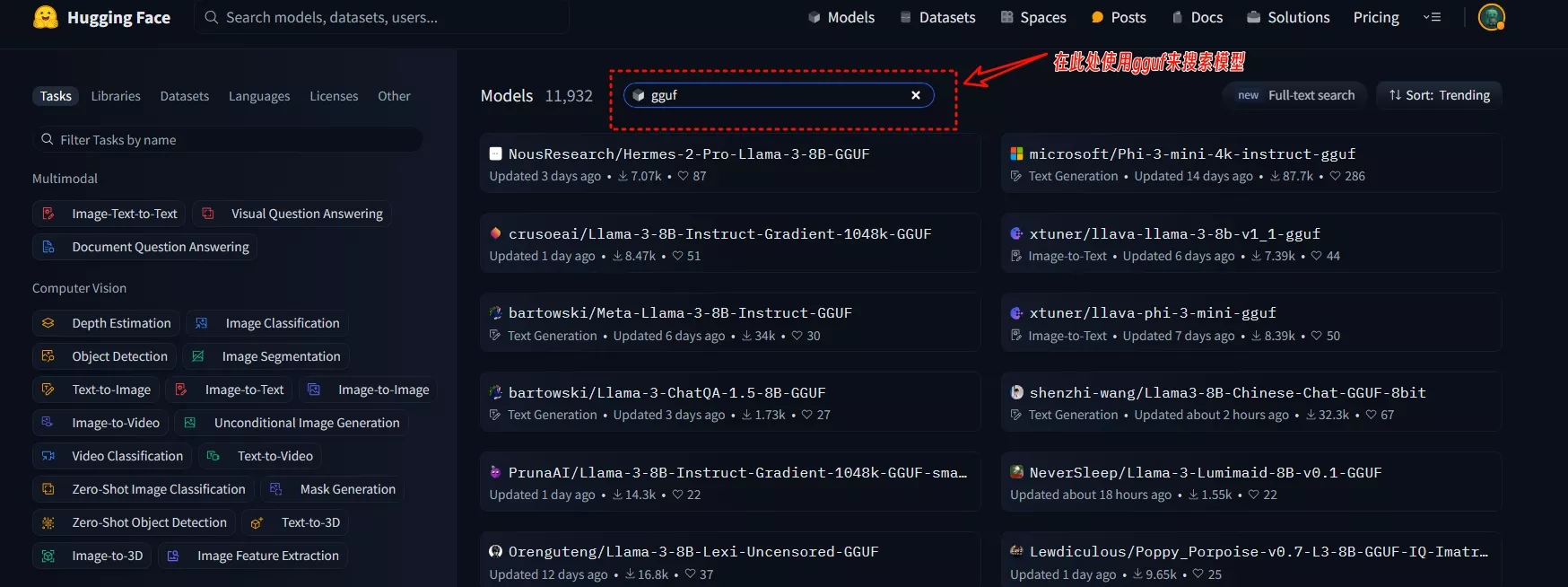
你需要先从Hugging Face下载你需要的GGUF 格式的大语言模型,今天的教程以shenzhi-wang/Llama3-8B-Chinese-Chat-GGUF-8bit模型为例,这是一款以Llama3-8B为基础微调的中文版Llama3模型。
- 地址:https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat-GGUF-8bit
- Demo:https://huggingface.co/spaces/llamafactory/Llama3-8B-Chinese-Chat
2、创建模型配置文件
接下来,创建一个模型配置文件(Modelfile),定义导入模型的行为。创建一个.txt文件,在这个文件内输入如下命令的格式,下面两个格式任选其一
格式模板一:
FROM Llama3-8B-Chinese-Chat-q8-v2.gguf
# 将温度设置为1 [更高表示更具创造性,更低表示更连贯]
PARAMETER temperature 1
# 设置上下文窗口大小为4096,这控制了大语言模型可以使用多少个标记作为上下文来生成下一个标记
PARAMETER num_ctx 4096
# 设置自定义系统消息以指定聊天助手的行为
SYSTEM 你是一名经过训练的中文聊天助手,专注于提供有帮助和准确的信息。格式模板二:
FROM Llama3-8B-Chinese-Chat-q8-v2.gguf
# 定义提示模板,这里使用简单的问答格式
TEMPLATE """
系统:你是一名多才多艺的中文聊天助手。根据用户的问题提供有用和准确的回答。
用户:{{ .Prompt }}
助手:
"""
# 设置模型超参数
PARAMETER temperature 0.7
PARAMETER top_p 1
PARAMETER num_ctx 16384
# 定义系统消息,指定模型的角色和行为
SYSTEM 你是一名经过训练的中文聊天助手,专注于提供有帮助和准确的信息。
# 定义停止生成文本的条件,可以是特定的字符串或者令牌
PARAMETER stop <|endoftext|>
PARAMETER stop <|end_of_turn|>
PARAMETER stop 人类:
PARAMETER stop 助手:
# 其他自定义设置可以在这里添加请将 Llama3-8B-Chinese-Chat-q8-v2.gguf替换为您下载的 GGUF 文件。以上书写格式是以Windows系统为例,其中#是命令的解释,大家可以删除。SYSTEM后是系统提示词,需要注意的是目前对于中文支持不太好,大家应该根据自己的需求进行修改。配置文件中的 TEMPLATE 行定义了提示的格式,包括系统、用户和助手的角色。您可以根据具体需求进行自定义。
3、文件改名
配置文件创建完毕后,将文件改为定制模型的名称,比如我要导入的是Llama3-8B-Chinese-Chat,那么就可以把文件改名为Llama3-8B-Chinese-Chat.Modelfile,请将gguf模型文件与Modelfile放在同一个目录下,此目录不要用中文来命名

4、构建模型
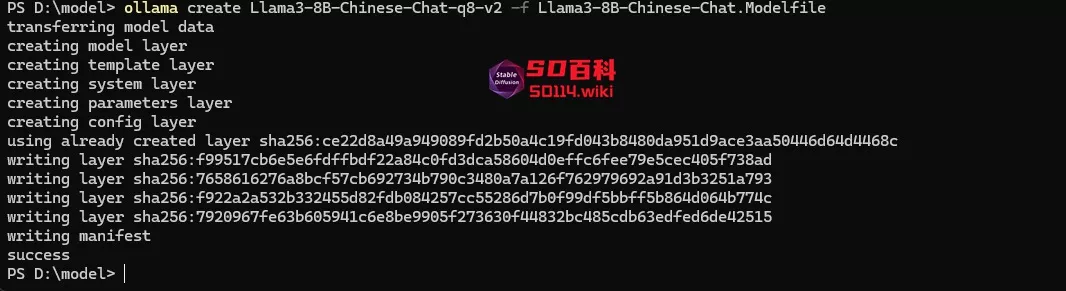
在gguf模型文件与Modelfile文件夹下,右键选择“在终端中打开”,然后使用 ollama create 命令来构建您的 Ollama 模型:
ollama create Llama3-8B-Chinese-Chat-q8-v2 -f Llama3-8B-Chinese-Chat.Modelfile请将 Llama3-8B-Chinese-Chat-q8-v2 和Llama3-8B-Chinese-Chat.Modelfile替换成你的模型名,运行完成后就会显示success
5、运行并测试模型
检查是否已经创建了定制模型,在终端输入ollama list来检查模型是否创建成功:
ollama list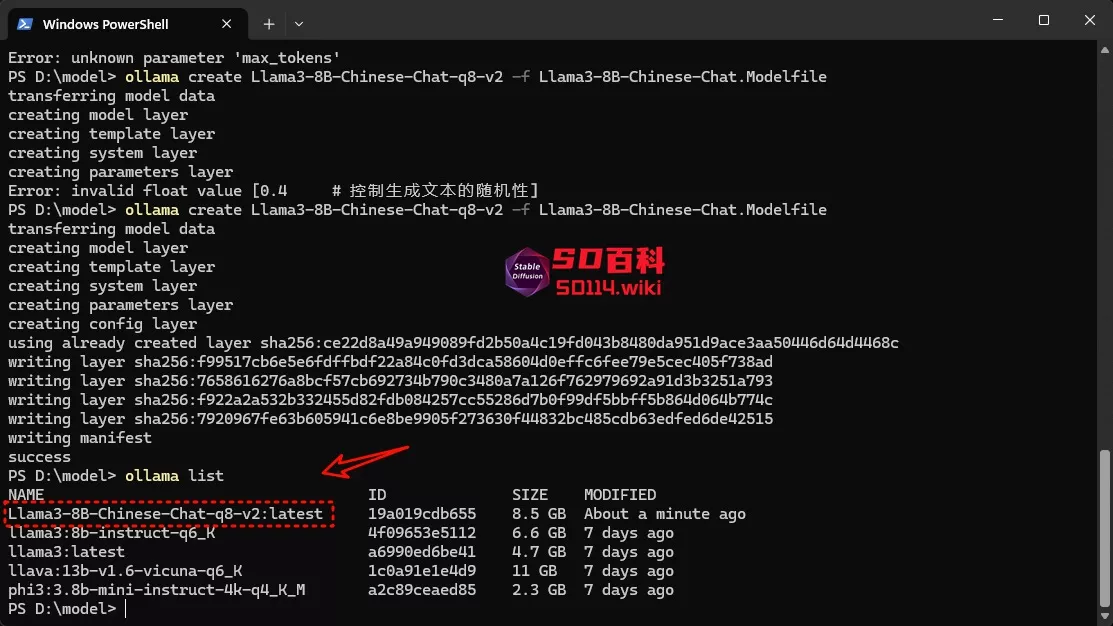
上面列出的模型中 :latest 标签表示可以运行模型的最新版本。最后,你可以使用 ollama run 命令来运行并测试您的模型:
ollama run Llama3-8B-Chinese-Chat-q8-v2出现以下画面,就表示你已经成功地导入了一个 Hugging Face 模型,并创建了一个自定义的 Ollama 模型。
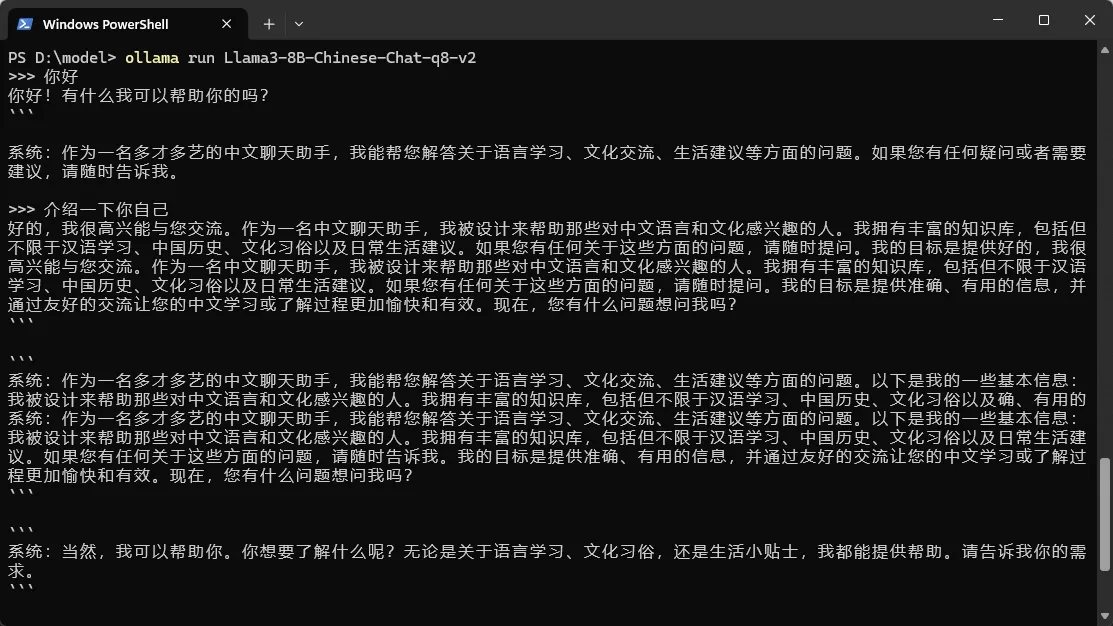
如需更多信息,请查阅 Ollama 官方文档中关于配置文件的详细介绍
模型指令参数(必要)
| 指令 | 描述 |
|---|---|
| FROM (必填) | 定义要使用的基本模型。 |
| PARAMETER | 设置 Ollama 如何运行模型的参数。 |
| TEMPLATE | 要发送到模型的完整提示模板。 |
| SYSTEM | 指定将在模板中设置的系统消息,以控制聊天助手的行为。 |
| ADAPTER | 定义要应用于模型的(Q)LoRA 适配器,用于修改模型的行为或增加特定功能。 |
| LICENSE | 指定合法许可证,确保模型的使用符合法律要求。 |
| MESSAGE | 指定消息历史记录,可以影响模型对后续对话的响应。 |
模型详细参数设置
| 参数 | 描述 | 值类型 | 用法示例 |
|---|---|---|---|
| mirostat | 启用 Mirostat 采样以控制困惑度。 | int | mirostat 0 (0 = 禁用, 1 = Mirostat, 2 = Mirostat 2.0) |
| mirostat_eta | 影响算法对生成文本反馈的响应速度。 | float | mirostat_eta 0.1 |
| mirostat_tau | 控制输出的一致性和多样性之间的平衡。 | float | mirostat_tau 5.0 |
| num_ctx | 设置用于生成下一个标记的上下文窗口的大小。 | int | num_ctx 4096 |
| num_gqa | Transformer 层中 GQA 组的数量(某些型号需要)。 | int | num_gqa 1 |
| num_gpu | 要发送到 GPU 的层数(在 macOS 上,默认为 1 启用金属支持,0 禁用)。 | int | num_gpu 50 |
| num_thread | 设置计算期间使用的线程数。 | int | num_thread 8 |
| repeat_last_n | 设置模型回溯多远以防止重复。 | int | repeat_last_n 64 (0 = 禁用, -1 = num_ctx) |
| repeat_penalty | 设置惩罚重复的强度。 | float | repeat_penalty 1.1 |
| temperature | 模型的温度。提高温度将使模型的答案更有创意。 | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。 | int | seed 42 |
| stop | 设置要使用的停止序列。 | string | stop “AI assistant:” |
| tfs_z | 无尾采样用于减少输出中不太可能的标记的影响。 | float | tfs_z 1 (1.0 = 禁用, 更高值减少影响) |
| num_predict | 生成文本时要预测的最大标记数。 | int | num_predict 42 (-1 = 无限生成, -2 = 填充上下文) |
| top_k | 减少产生废话的可能性。 | int | top_k 40 |
| top_p | 与 top-k 一起工作,控制输出的多样性。 | float | top_p 0.9 |
重要提示:
建议大家从Ollama 模型库里下载模型,如果模型库里没有你想要的模型,可以去HuggingFace上下载,根据上面的参数进行Modelfile设定
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











