
由腾讯开源的 HunyuanVideo-Foley 是一个面向视频内容的音效生成模型,能够根据视频帧或文本提示自动生成高质量、时间同步的环境音与动作音效。现在,这一能力已通过第三方节点 ComfyUI-HunyuanVideo-Foley 被集成进 ComfyUI 生态,支持可视化编排、批处理与显存优化,使得研究者和创作者可以在中等配置的显卡上高效使用。
这不仅是一个简单的封装,而是一次面向实际部署的工程优化:从 FP8 量化到 torch.compile 加速,再到内置卸载机制,它让原本对硬件要求较高的音效生成任务变得触手可及。
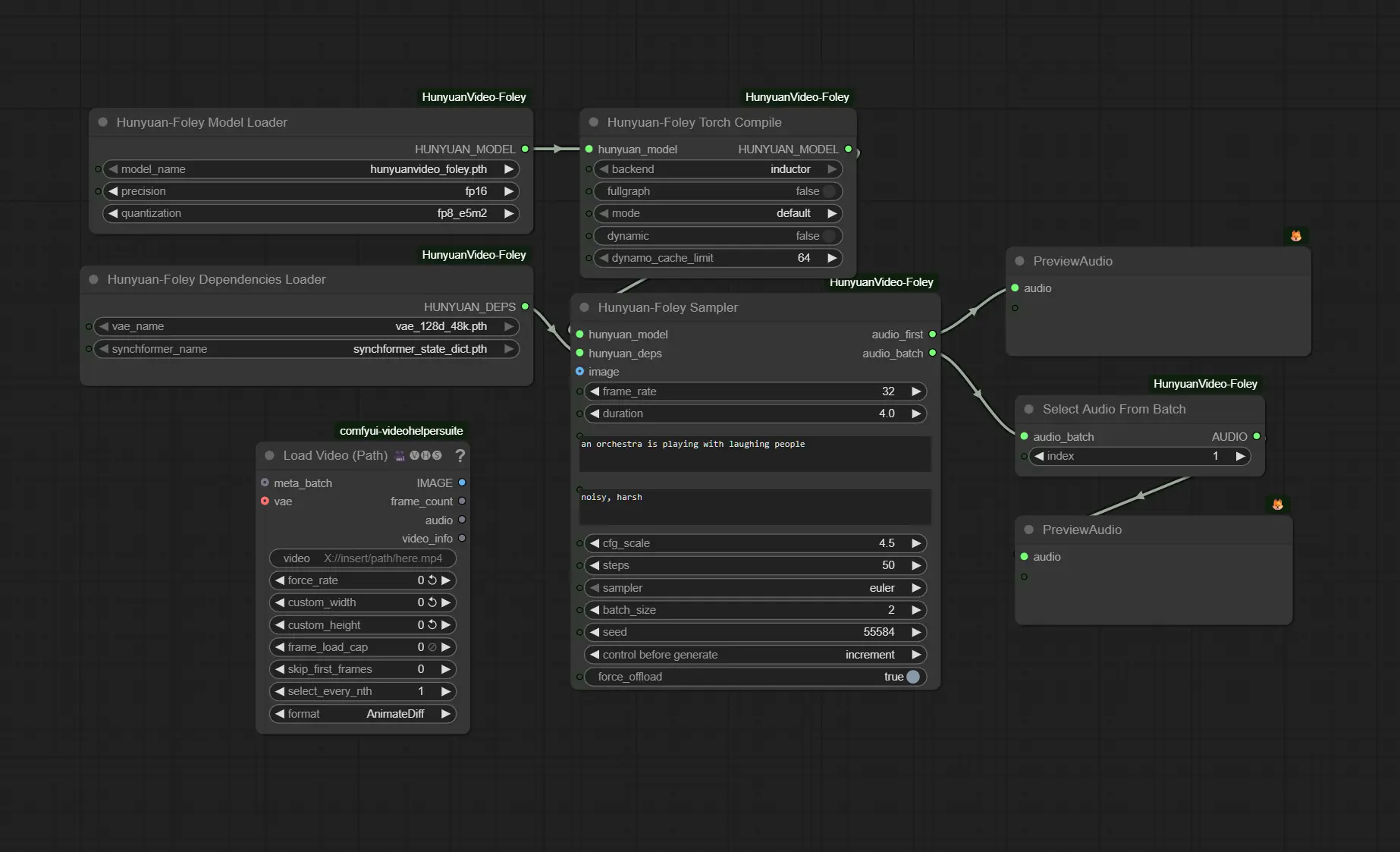
节点功能概览
该 ComfyUI 插件包含四个核心节点,构成完整的工作流:
1. Hunyuan-Foley Model Loader
加载主模型 hunyuanvideo_foley.pth,提供两个关键控制选项:
- 精度选择:支持
bf16、fp16、fp32,默认推荐bf16(兼顾速度与稳定性) - FP8 量化(仅权重):将线性层权重以 FP8 存储,显著降低 VRAM 占用,计算仍以高精度进行,音质无损
适用于显存 ≤12GB 的用户,是低资源运行的关键开关。
2. Hunyuan-Foley Dependencies Loader
加载模型依赖的四个子模块:
- DAC-VAE:用于音频编码/解码(
vae_128d_48k.pth) - SigLIP2:图像编码器
- Synchformer:跨模态同步建模组件(
synchformer_state_dict.pth) - CLAP:文本-音频对齐模型
这些组件自动按需加载,无需手动干预。
3. Hunyuan-Foley Sampler
音效生成主节点,支持:
- 纯文本输入(Text-to-Audio):无需图像,直接根据提示生成音效
- 视频帧序列输入(Video-to-Audio):传入图像批次并设置
frame_rate实现时间对齐 - 负面提示(Negative Prompt):排除不希望出现的声音类型
- 批处理(Batch Size):一次性生成多个变体,便于筛选
推荐参数:
- 采样器:
Euler - CFG:≈4.5
- 步数(Steps):≈50
4. Hunyuan-Foley Torch Compile(可选)
启用 PyTorch 2.7+ 的 torch.compile 功能:
- 首次运行需编译(稍慢)
- 后续推理速度提升约 30%
- 对 A100、RTX 30/40 系列显卡效果显著
⚠️ 首次使用建议先关闭此节点测试流程,确认无误后再开启加速。
📦 模型文件部署
从 Hugging Face或魔塔下载模型文件:
- Hugging Face:https://huggingface.co/tencent/HunyuanVideo-Foley/tree/main
- 魔塔:https://www.modelscope.cn/models/Tencent-Hunyuan/HunyuanVideo-Foley
将以下文件放入 ComfyUI 模型目录:
ComfyUI/models/foley/
├── hunyuanvideo_foley.pth (~10.3 GB) # 主模型
├── synchformer_state_dict.pth (~0.95 GB) # 同步编码器
└── vae_128d_48k.pth (~1.49 GB) # DAC-VAE 解码器
💡 若目录不存在,请手动创建
foley文件夹。
测试环境与依赖
- PyTorch 版本:已在 2.7 和 2.8 上验证
- CUDA 支持:需安装支持 CUDA 12 的 PyTorch(如
torch==2.8.0+cu12) - 关键依赖包(来自
https://download.pytorch.org/whl/cu126):torch,torchaudio,torchvisionnvidia-cudnn-cu12,nvidia-cublas-cu12等底层 CUDA 库xformers(可选,用于优化注意力计算)
内存与性能表现
在 24GB 显卡(如 RTX 3090/4090) 上生成一段 5 秒音频(50 步)的典型显存占用:
| 配置 | 显存占用 |
|---|---|
| 基准 | ~10–12 GB |
| 启用 Ping-Pong 卸载(内置) | ~9–10 GB |
| + FP8 量化 | 再降 ~1–2+ GB |
| + Torch Compile | 首次编译后,推理快 30% |
✅ 低于 12GB 显存的运行方案:
- 开启 FP8 量化
- 保持
batch_size=1 - 控制
steps ≤ 50 - 如仍 OOM,可在 Sampler 中启用
force_offload
无需顶级硬件,即可完成生成任务。
🧪 批处理与后筛选
- 设置
batch_size > 1可一次性生成多个音效变体 - VRAM 消耗大致与 batch size 成正比
- 使用
Select Audio From Batch节点从结果中挑选最佳片段
适用于:
- 多种音效风格对比
- 视频剪辑中不同音效方案试听
- 自动化内容生产流水线
🛠️ 常见问题与修复
| 问题 | 解决方案 |
|---|---|
| OOM(显存不足) | 降低 batch_size,减少 steps,开启 force_offload |
| 首次运行极慢 | 正常现象,torch.compile 正在编译计算图 |
| 音频失真或静音 | 检查 DAC-VAE 是否正确加载,确认模型路径无误 |
| FP8 不生效 | 确保显卡 支持 FP8(如 H100/A100/4090),驱动和 CUDA 版本匹配 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











