来自南洋理工大学、上海人工智能实验室和香港中文大学的研究团队推出3D生成框架ComboVerse,它能够从单张图片中生成复杂的三维资产。
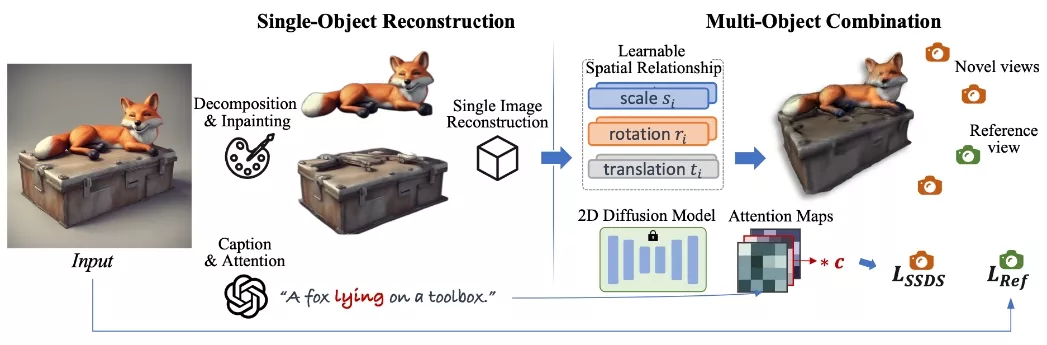
首先,从模型和数据两个维度对“多物体差距”进行了深入分析。接着,利用不同物体的重建3D模型,调整它们的大小、旋转角度和位置,以构建与给定图像相匹配的3D场景。为了自动化这一过程,利用预训练的扩散模型中的空间感知分数蒸馏采样(SSDS)技术来指导物体的精准定位。与标准的分数蒸馏采样相比,ComboVerse更加注重物体间的空间对齐,从而实现了更精确的结果。

想象一下,你有一张包含多个物体的图片,比如一只松鼠坐在一个纸盒上,ComboVerse能够根据这张图片生成一个高质量的3D模型,其中松鼠和纸盒都是清晰且位置准确的。
主要功能和特点:
- 组合生成: ComboVerse能够分别生成图片中的每个物体,然后将它们自动组合成一个整体的3D模型。
- 空间感知: 该框架使用空间感知的分数蒸馏采样(SSDS)来指导物体的定位,从而实现更准确的空间排列。
- 高质量渲染: 通过深度分析现有模型在处理多物体时的不足,ComboVerse能够生成具有复杂组合的高质量3D资产。
工作原理:
- 单物体重建: 首先,ComboVerse对输入图片中的每个物体进行分割和重建,使用图像到3D的模型来创建单个物体的3D模型。
- 多物体组合: 然后,框架通过优化每个物体的尺寸、旋转角度和位置来自动组合这些生成的3D物体,使其与输入图片和语义空间关系相匹配。这个过程使用预训练的扩散模型作为空间指导,以加快优化过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











