
AI智能体(AI Agent)的构建正在成为大模型应用的前沿方向。然而,要打造一个稳定、高效、可扩展的智能体系统,远不只是调用一个大模型那么简单。
Manus团队在构建AI智能体的过程中,经历多次架构重构与工程实践,最终总结出一套关于上下文工程(Context Engineering)的核心方法论。这些经验不仅适用于AI智能体开发者,也对所有希望提升大模型应用效果的工程师具有重要参考价值。
为何选择上下文工程?
在Manus项目初期,团队面临一个关键选择:
- 是从头训练一个端到端的智能体模型?
- 还是利用现有大模型的上下文学习能力,构建基于提示的智能体系统?
最终,团队选择了后者。原因很简单:上下文工程具有更高的迭代效率。相比传统的模型微调,上下文工程可以在数小时内完成一次改进,而不需要数周的训练周期。
更重要的是,它让Manus能够与模型演进保持正交关系:当底层模型变强时,Manus也能随之提升,就像“船随潮水涨”。
上下文工程的本质:一场“随机研究生下降”
尽管上下文工程听起来很“工程”,但它本质上是一门实验科学。Manus团队已经四次重建智能体框架,每次都是在发现了更优的上下文设计后进行的。
他们戏称这个过程为“随机研究生下降”(Stochastic Graduate Descent):一种结合手动架构搜索、提示调整和经验猜测的探索过程。虽然不优雅,但非常有效。
关键经验一:KV缓存命中率是性能与成本的关键
在生产环境中,KV缓存命中率(Key-Value Cache Hit Rate)是衡量AI智能体性能的最重要指标之一。它直接影响推理延迟和成本。

为什么KV缓存如此重要?
典型的AI智能体流程如下:
- 接收用户输入;
- 调用工具,生成观察结果;
- 将动作与观察追加到上下文;
- 继续下一轮推理。
在这个过程中,输入上下文不断增长,而输出相对较短(如一个函数调用)。这种输入输出比例严重失衡的特性,使得KV缓存的命中率直接决定了性能与成本。
以Claude Sonnet为例:
- 缓存的输入令牌成本:0.30美元/百万;
- 未缓存的输入令牌成本:3美元/百万;
差价高达10倍。
提升KV缓存命中率的三大实践:
- 保持提示前缀稳定
即使一个token的变化也会导致缓存失效。例如,系统提示中加入时间戳虽然能提供当前时间,但会严重破坏缓存。 - 上下文仅追加,不修改
确保序列化过程是确定性的。许多JSON库不保证键顺序,可能导致缓存失效。 - 明确缓存断点标记
如果推理框架不支持自动缓存管理,需要手动插入断点。例如,系统提示结束后插入缓存分隔符。
关键经验二:屏蔽动作空间,而非动态删除工具
随着智能体能力增强,其动作空间(Action Space)会变得越来越复杂。工具数量激增会导致模型更容易选择错误动作或走低效路径。
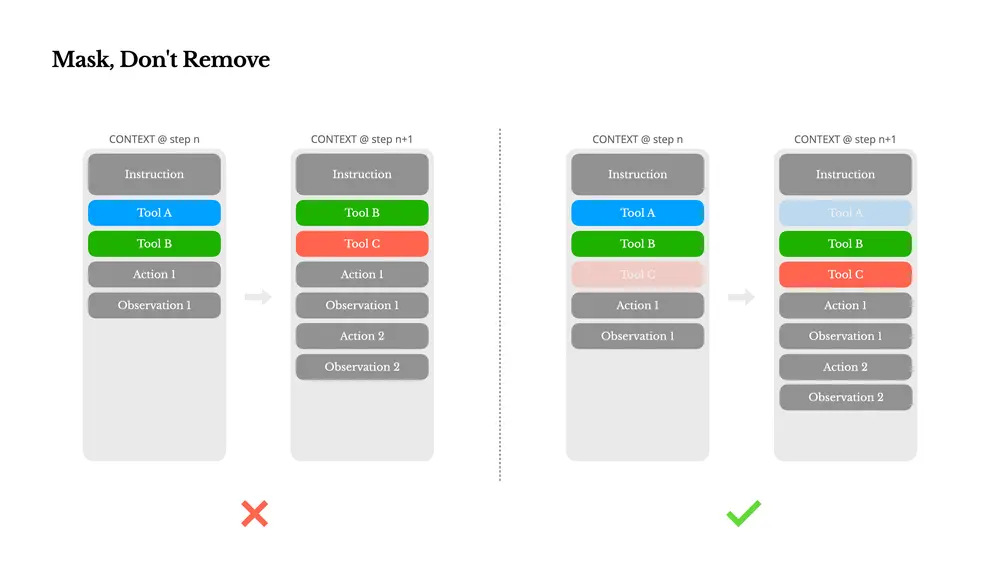
一种常见的做法是使用类似RAG的方式动态加载工具,但Manus团队发现这会带来两个问题:
- 工具定义通常位于上下文前部,修改会导致缓存失效;
- 模型可能引用已删除的工具,导致幻觉或模式错误。
解决方案:上下文感知的工具屏蔽机制
Manus采用了一种更稳定的方式:
- 不解绑工具定义;
- 通过解码时屏蔽token logits来控制可用动作。
例如,当用户输入新问题时,必须先回复,不能执行工具调用。此外,所有工具命名采用统一前缀(如 browser_、shell_),便于在特定上下文中限制动作范围。
关键经验三:用文件系统做上下文扩展
虽然现代大模型支持128K token的上下文窗口,但在实际智能体场景中,仍然面临三大挑战:
- 观察结果过大(如网页、PDF);
- 模型性能随上下文长度下降;
- 长输入带来高昂成本。
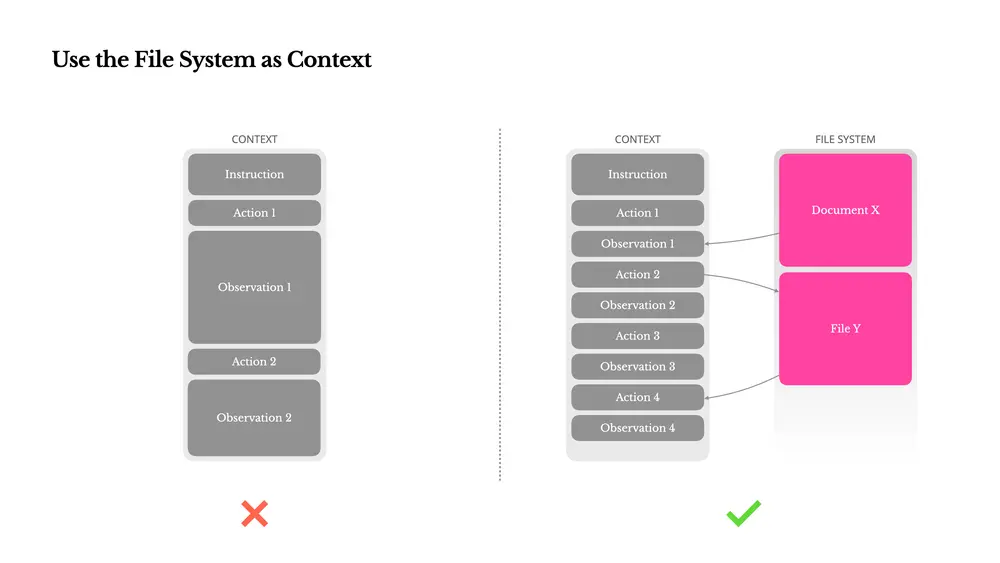
解决思路:将文件系统作为“外部记忆”
Manus将文件系统视为无限容量、持久化、可操作的记忆空间。模型学会按需读写文件,实现上下文的外部化存储。
例如:
- 网页内容可保存为文件,仅保留URL;
- 文档内容可存储路径,按需读取。
这种方式既能控制上下文长度,又不会永久丢失信息。
关键经验四:复述目标以操控注意力
在处理复杂任务时,Manus会创建一个 todo.md 文件,并随着任务进展不断更新。这不是“可爱”行为,而是一种刻意设计的注意力操控机制。
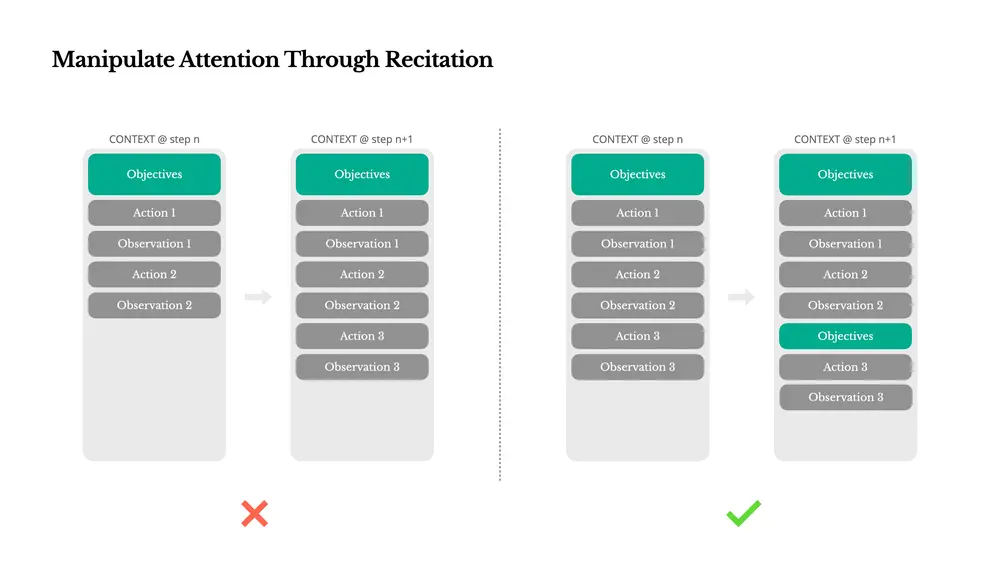
为什么这样做?
LLM在长序列中容易遗忘早期目标。通过不断重写待办事项,Manus将任务目标推入模型的近期注意力窗口,避免“中间丢失”现象。
关键经验五:保留错误信息,让智能体学会“从失败中学习”
智能体系统会出错,这是常态,而非异常。然而,常见的做法是隐藏错误、重试或重置状态。这种做法看似“干净”,但代价是抹去了失败的证据。
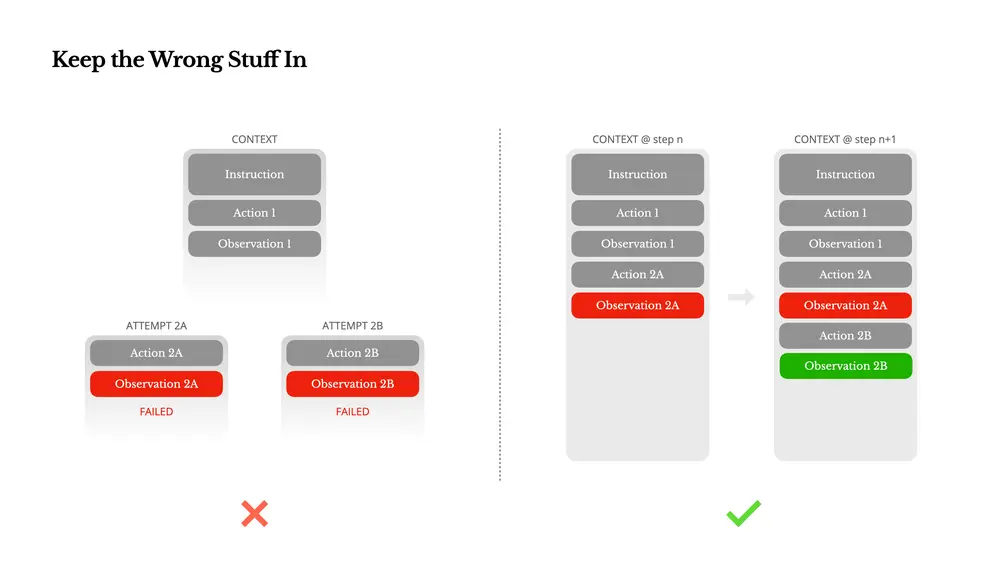
Manus的处理方式:
- 保留错误动作与观察结果;
- 让模型看到失败的上下文;
- 通过观察错误,模型会隐式更新内部信念,降低重复错误概率。
我们认为,错误恢复能力是衡量智能体智能程度的重要指标之一,但在大多数学术研究中却被低估。
关键经验六:避免“少样本陷阱”
少样本提示(Few-shot Prompting)常用于提升LLM输出质量。但在智能体系统中,它可能带来副作用:
- 模型容易模仿上下文中的行为模式;
- 在重复任务中容易陷入固定节奏,导致泛化失败或幻觉。
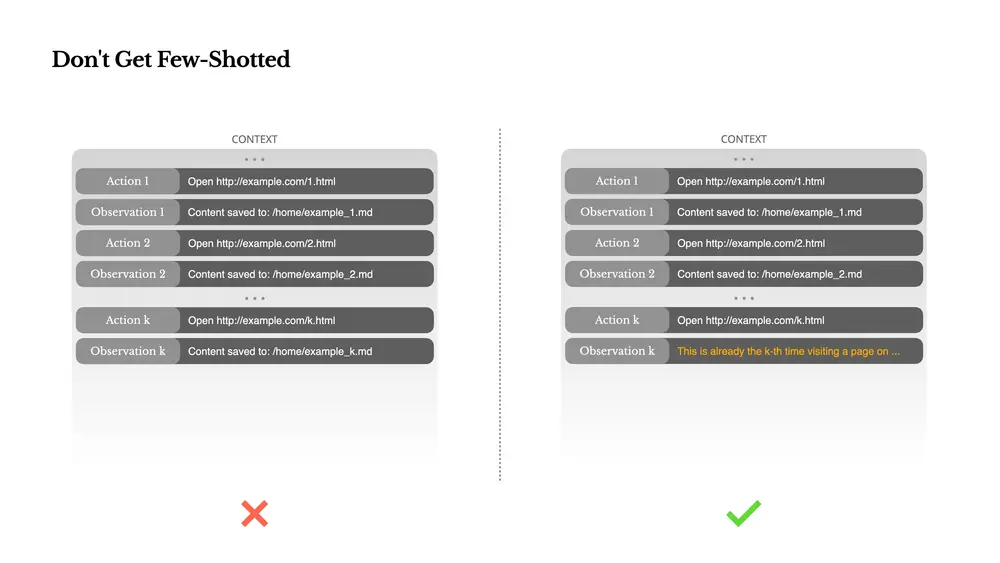
解决方案:引入结构化多样性
Manus在动作与观察中引入少量结构化变化,如:
- 不同的序列化模板;
- 替代措辞;
- 格式与顺序的微小噪声。
这种受控的随机性帮助模型跳出固定模式,提升泛化能力。
总结:上下文是智能体行为的核心
上下文工程虽然仍处于探索阶段,但它已经成为AI智能体系统的核心设计维度。
在Manus的实践中,我们发现:
- 再强的模型也无法替代记忆、环境和反馈的作用;
- 上下文的设计方式,决定了智能体的速度、鲁棒性与扩展性。
我们分享的这些经验并非通用真理,而是我们通过数百万次用户交互、反复重构与实验总结出的“局部最优解”。
如果你正在构建AI智能体,希望这些经验能帮你少走弯路。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











