
虽然“上下文工程”这一术语背后的原理并非全新,但这个措辞提供了一个有用的抽象概念,使我们能够思考构建有效 AI 代理时面临的最紧迫挑战。在本文中,我想探讨三件事:上下文工程的含义、它与“提示工程”的区别。
什么是上下文工程
AI 代理需要与任务相关的上下文,才能以合理的方式执行该任务。我们早已知道这一点,但鉴于 AI 领域的快速发展与新鲜感,我们不断提出新的抽象概念,以便以易于理解的方式探讨最佳实践和新方法。
Andrey Karpathy 的帖子对此做了很好的总结:
人们将提示与日常使用中给 LLM 的简短任务描述联系起来。然而,在每一个工业级 LLM 应用中,上下文工程是一门精妙的艺术与科学,旨在为下一步填充恰到好处的上下文信息。
虽然“提示工程”专注于为 LLM 提供正确的指令,但“上下文工程”更侧重于为 LLM 的上下文窗口填充最相关的信息,无论这些信息来自何处。
你可能会问:“这不就是 RAG(检索增强生成)吗?这似乎很像专注于检索。”这个问题问得很好。但上下文工程这一术语让我们能够超越检索步骤,考虑上下文窗口作为一个需要谨慎策划的整体,同时也要考虑其限制:即上下文窗口的容量限制。
上下文的构成
在撰写这篇博客之前,我们阅读了 Philipp Schmid 的文章《AI 新技能不是提示工程,而是上下文工程》,他在文中很好地分解了 AI 代理或 LLM 上下文的构成。因此,我们基于他的列表并加入了一些补充内容,总结了“上下文”的构成:
- 系统提示/指令:为代理设定场景,说明我们希望它执行的任务类型。
- 用户输入:可以是问题、完成任务的请求等。
- 短期记忆或聊天历史:为 LLM 提供关于当前对话的上下文。
- 长期记忆:可用于存储和检索长期聊天历史或其他相关信息。
- 从知识库检索的信息:可以是基于向量搜索的数据库检索,也可以是通过 API 调用、MCP 工具或其他来源检索的相关信息。
- 工具及其定义:为 LLM 提供它可访问的工具的额外上下文。
- 工具的响应:将工具运行的响应返回给 LLM,作为额外的上下文。
- 结构化输出:提供我们期望从 LLM 获得的输出格式的上下文,也可以反过来为特定任务提供简洁的结构化信息。
- 全局状态/上下文:特别适用于使用 LlamaIndex 构建的代理,允许我们使用工作流的 Context 作为一种便签板,跨代理步骤存储和检索全局信息。
上述内容的某种组合几乎构成了当前所有代理 AI 应用的底层 LLM 的上下文。这引出了一个关键点:精确思考上述哪些内容应构成代理的上下文,以及以何种方式构成,正是上下文工程的核心。因此,让我们看看一些需要考虑上下文策略的场景,以及如何使用 LlamaIndex 和 LlamaCloud 实现这些策略。
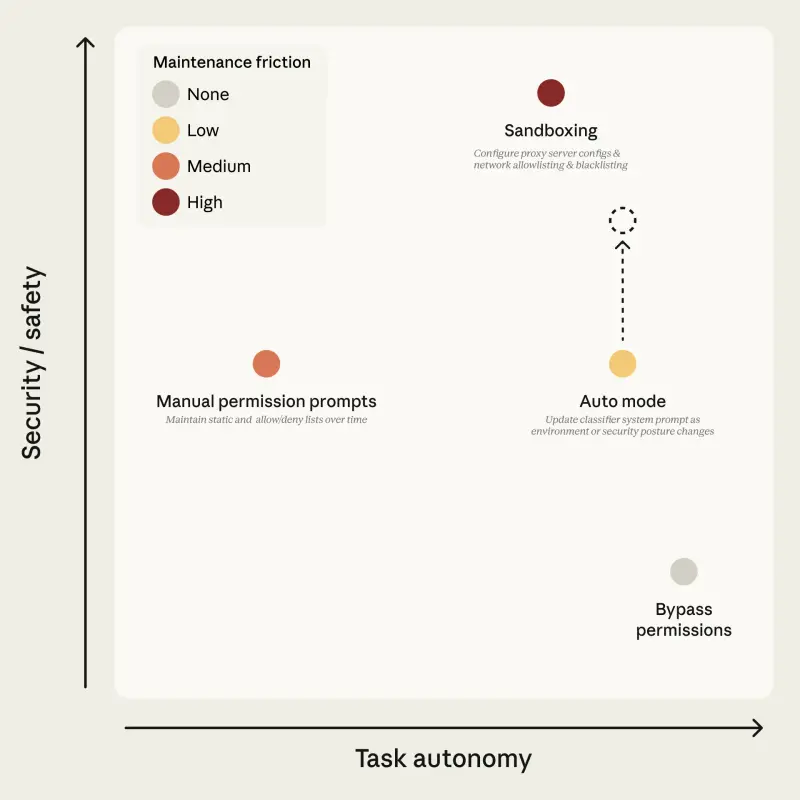
上下文工程的技巧与策略
快速浏览上述列表,你可能已经注意到,构成上下文的元素可能有很多。这意味着我们面临两个主要挑战:选择正确的上下文,以及使上下文适应窗口限制。虽然这个列表可能会不断扩展,但让我们来看看在为代理策划正确上下文时需要考虑的一些架构选择:
知识库或工具选择
当我们提到 RAG 时,通常指的是设计用于对单一知识库(通常是向量存储)进行问答的 AI 应用。但对于如今的许多代理应用,情况已不再如此。我们现在看到的应用需要访问多个知识库,可能还需添加能够返回更多上下文或执行特定任务的工具。
在从知识库或工具检索额外上下文之前,LLM 拥有的第一个上下文是关于可用工具或知识库的信息本身。这种上下文使我们能够确保代理 AI 应用选择正确的资源。
上下文排序或压缩
上下文工程的另一个重要考虑因素是上下文窗口的限制。我们能使用的空间是有限的。这导致了一些实现方式,试图通过上下文摘要等技术充分利用这一空间,例如在检索步骤后对结果进行摘要,然后再将其添加到 LLM 上下文中。
在某些情况下,不仅上下文内容重要,内容的顺序也很关键。考虑一个用例,我们不仅需要检索数据,数据的日期也高度相关。在这种情况下,加入一个排序步骤,使 LLM 按最相关的顺序接收信息,也会非常有效。
长期记忆存储与检索的选择
如果我们的应用需要与 LLM 进行持续对话,对话历史本身就会成为上下文。在 LlamaIndex 中,我们为此提供了多种长期记忆实现,以及一个可扩展的 Base Memory Block,以满足任何独特的记忆需求。
例如,我们提供的一些预构建记忆块包括:
- VectorMemoryBlock:将聊天消息批存储到向量数据库并从中检索的记忆块。
- FactExtractionMemoryBlock:从聊天历史中提取事实的记忆块。
- StaticMemoryBlock:存储静态信息的记忆块。
在与代理的每次迭代中,如果长期记忆对用例很重要,代理会在决定下一步最佳行动之前从中检索额外的上下文。这使得决定需要哪种长期记忆以及应该返回多少上下文成为一个相当重要的决策。在 LlamaIndex 中,我们支持使用上述长期记忆块的任意组合。
结构化信息
在创建代理 AI 系统时,一个常见错误是提供所有上下文,即使它们并不必要;这可能会在不需要时过度拥挤上下文窗口。
结构化输出是近年来引入 LLM 的一个我最喜欢的功能之一,原因就在于此。它们对为 LLM 提供最相关的上下文有重大影响。这种影响是双向的:
- 请求的结构:我们可以为 LLM 提供一个模式,要求输出符合该模式。
- 作为额外上下文提供的结构化数据:这是一种在不让 LLM 因额外、不必要上下文而过载的情况下提供相关上下文的方式。
LlamaExtract 是一个 LlamaCloud 工具,允许你利用 LLM 的结构化输出功能,从复杂且冗长的文件和来源中提取最相关的数据。一旦提取,这些结构化输出可作为下游代理应用的简洁上下文。
工作流工程
虽然上下文工程专注于优化每次 LLM 调用的输入信息,但工作流工程则退后一步,思考:我们需要怎样的 LLM 调用和非 LLM 步骤序列来可靠地完成这项工作?最终,这也有助于优化上下文。LlamaIndex Workflows 提供了一个事件驱动框架,让你可以:
- 定义明确的步骤序列:规划完成复杂工作所需的确切任务进程。
- 战略性地控制上下文:精确决定何时调用 LLM,何时使用确定性逻辑或外部工具。
- 确保可靠性:内置验证、错误处理和回退机制,这是简单代理无法提供的。
- 针对特定结果优化:创建始终交付业务所需结果的专用工作流。
从上下文工程的角度来看,工作流至关重要,因为它们防止了上下文过载。与其将所有内容塞进一次 LLM 调用并期待最佳结果,不如将复杂任务分解为专注的步骤,每个步骤都有其优化的上下文窗口。
这里的战略洞察是,每个 AI 构建者最终都在构建专用工作流——无论他们是否意识到这一点。文档处理工作流、客户支持工作流、编码工作流——这些是实用 AI 应用的构建模块。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











