上下文工程是 AI 领域中逐渐兴起的一个新术语。讨论的焦点正从“提示工程”转向一个更广泛、更强大的概念:上下文工程。Tobi Lutke 将其描述为“为任务提供所有上下文以使大语言模型(LLM)能够合理解决问题的艺术”,他是对的。
随着智能体的兴起,我们加载到“有限工作记忆”中的信息变得更加重要。我们发现,决定智能体成功或失败的主要因素是你提供的上下文质量。大多数代理失败不再是模型失败,而是上下文失败。
什么是上下文?
要理解上下文工程,首先必须扩展我们对“上下文”的定义。它不仅仅是你发送给 LLM 的单一提示。可以将其视为模型在生成回答之前看到的所有内容。
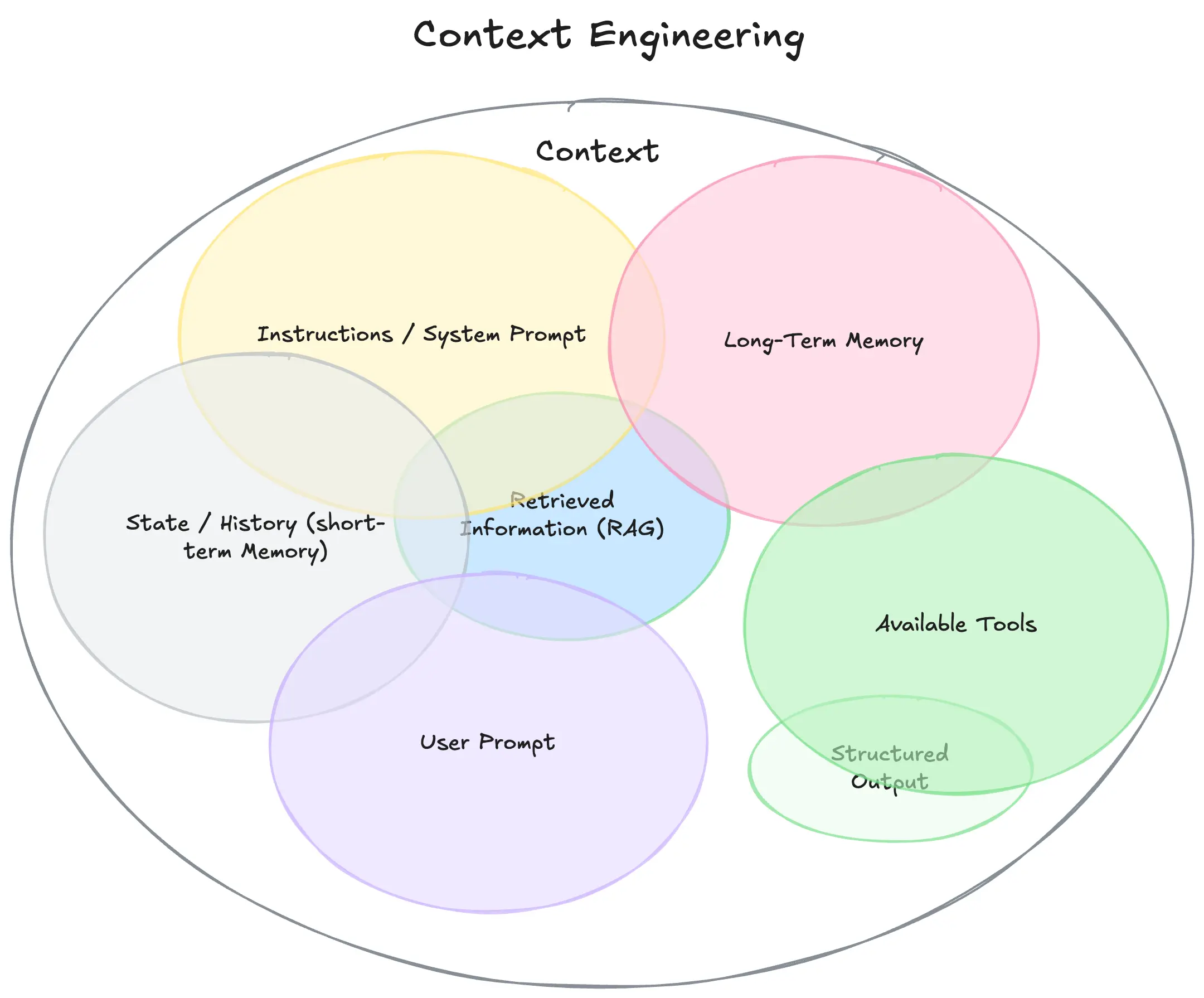
- 指令/系统提示:定义模型在对话中行为的一组初始指令,可以/应该包括示例、规则等。
- 用户提示:用户提出的即时任务或问题。
- 状态/历史(短期记忆):当前对话,包括用户和模型的响应,记录了到此刻为止的对话过程。
- 长期记忆:持久的知识库,跨多次先前对话收集,包含学习到的用户偏好、过去项目的摘要或被要求记住以备将来使用的事实。
- 检索信息(RAG):外部、实时的知识,来自文档、数据库或 API 的相关信息,以回答特定问题。
- 可用工具:模型可调用的所有功能或内置工具的定义(例如,check_inventory、send_email)。
- 结构化输出:模型回答格式的定义,例如 JSON 对象。
为什么重要:从廉价演示到神奇产品
构建真正有效的 AI 智能体的秘诀,与你编写的代码复杂度无关,而与你提供的上下文质量密切相关。
构建智能体与你使用的代码或框架关系不大。廉价演示与“神奇”代理之间的区别在于你提供的上下文质量。想象一个 AI 助手被要求根据一封简单的电子邮件安排会议:
嘿,只是想确认你明天是否有空进行一次快速同步。
“廉价演示”代理的上下文很差。它只看到用户请求,没有其他信息。它的代码可能完全正常——调用 LLM 并获得响应——但输出无用且机械:
感谢您的消息。明天对我来说可以。请问您考虑的是什么时间?
“神奇”代理则由丰富的上下文驱动。代码的主要任务不是确定如何回应,而是收集 LLM 完成目标所需的信息。在调用 LLM 之前,你会扩展上下文,包含:
- 你的日历信息(显示你全天都排满了)。
- 你与此人的历史邮件(以确定适当的非正式语气)。
- 你的联系人列表(以识别对方为关键合作伙伴)。
- 用于 send_invite 或 send_email 的工具。
然后,你可以生成以下响应:
嘿,Jim!明天我这边全天排满。星期四上午有空,适合你吗?已发送邀请,告诉我是否合适。
神奇之处不在于更智能的模型或更巧妙的算法,而在于为特定任务提供正确的上下文。这就是上下文工程重要的原因。代理失败不仅仅是模型失败,而是上下文失败。
从提示工程到上下文工程
什么是上下文工程?虽然“提示工程”专注于打造完美的单一文本指令集,但上下文工程的范围要广泛得多。简单来说:
上下文工程是设计和构建动态系统的学科,它在正确的时间、以正确的格式提供正确的信息和工具,为 LLM 完成任务提供所需的一切。
上下文工程是:
- 系统,而非字符串:上下文不仅仅是静态的提示模板。它是一个在主 LLM 调用之前运行的系统的输出。
- 动态性:根据即时任务动态创建。对于一个请求,可能是日历数据;对于另一个,可能是电子邮件或网络搜索。
- 提供正确的信息和工具,在正确的时间:核心任务是确保模型不缺少关键细节(“垃圾输入,垃圾输出”)。这意味着仅在需要且有帮助时提供知识(信息)和能力(工具)。
- 格式很重要:信息的呈现方式很重要。简洁的摘要优于原始数据堆砌。清晰的工具架构优于模糊的指令。
结论
构建强大且可靠的 AI智能体越来越不依赖于寻找神奇的提示或模型更新,而是关于上下文工程——在正确的时间、以正确的格式提供正确的信息和工具。这是一个跨职能的挑战,涉及理解你的业务用例、定义输出,并结构化所有必要信息,以便 LLM 能够“完成任务”。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











