谷歌今天宣布,其 AI 视频生成模型 Veo 3 已新增对图生视频的支持。这项功能已通过 Gemini 应用 和新推出的 Flow 工具 向用户开放。
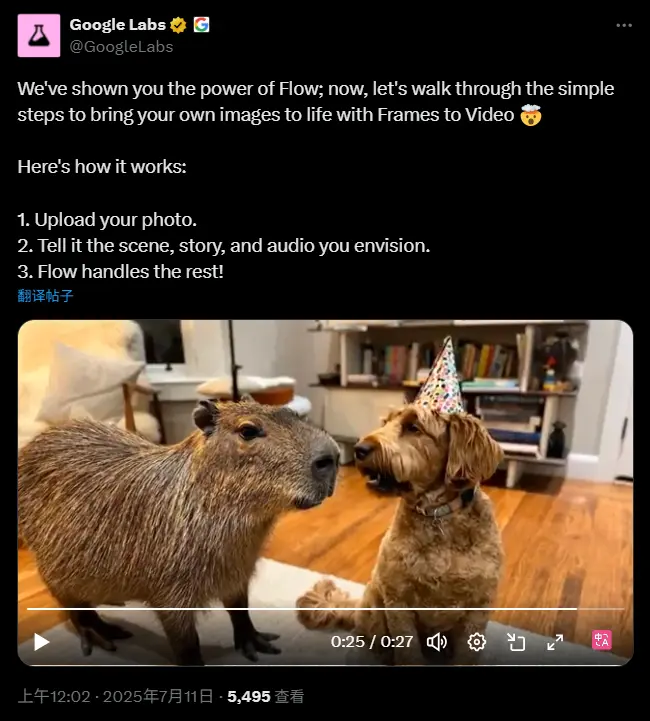
该功能最初在 5 月的 Google I/O 开发者大会上首次亮相,并于近期在全球超过 150 个国家上线。目前,只有订阅 Google One AI Ultra 和 AI Pro 计划的用户可使用该功能,每日限制为三次视频生成,不支持累计次数。
图像驱动的视频生成:操作简单,效果可控
借助这一更新,用户现在可以在 Gemini 应用或 Flow 工具中:
- 在提示框中点击“工具”菜单,选择“视频”选项;
- 上传一张图片作为视频的视觉基础;
- 通过文本描述添加音频或其他视频元素;
- 生成一段由 AI 驱动的动态视频片段;
- 下载或分享生成结果。
这一功能极大地拓展了 AI 视频生成的应用场景,从纯文本驱动升级为图文结合驱动,使创作者能够更好地控制视频内容的视觉风格与叙事方向。
用户活跃度高,AI 视频创作加速普及
自七周前发布以来,用户已在 Gemini 应用和 Flow 工具中创建了超过 4000 万个视频,显示出市场对 AI 视频生成工具的强烈需求。
为提升透明度,谷歌对所有 Veo 3 生成的视频均添加了:
- 可见水印“Veo”,标明视频来源;
- 不可见的 SynthID 数字水印,用于识别 AI 生成内容。
此外,谷歌今年早些时候还推出了 SynthID 内容检测工具,帮助用户识别是否为 AI 生成内容,进一步推动 AI 内容的负责任使用。
技术背后:Veo 3 的持续进化
Veo 3 是谷歌在 AI 视频生成领域的重要成果,具备强大的多模态理解和生成能力。此次加入图像输入支持,意味着其不仅能理解文字描述,还能基于真实或合成图像生成连贯、高质量的视频内容。
这种技术演进为教育、广告、创意媒体等领域提供了新的内容生产方式,同时也对内容真实性、版权保护等提出了更高的要求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











