
来自香港科技大学与小冰AI的研究人员推出名为“子对象级图像标记化”(subobject-level image tokenization)的新方法,这是一种用于计算机视觉模型的图像处理技术。这种方法受到自然语言处理(NLP)中子词标记化的启发,旨在更有效地将图像转换为模型可以理解的格式。与传统的将图像分割成固定大小的正方形块的方法不同,子对象级标记化使用由分割模型(如“分割任何东西”模型)生成的有意义的图像片段。
子对象级图像标记化是一种创新的方法,它通过在图像处理中引入类似于自然语言处理中的子词标记化的概念,提高了计算机视觉模型的效率和准确性。
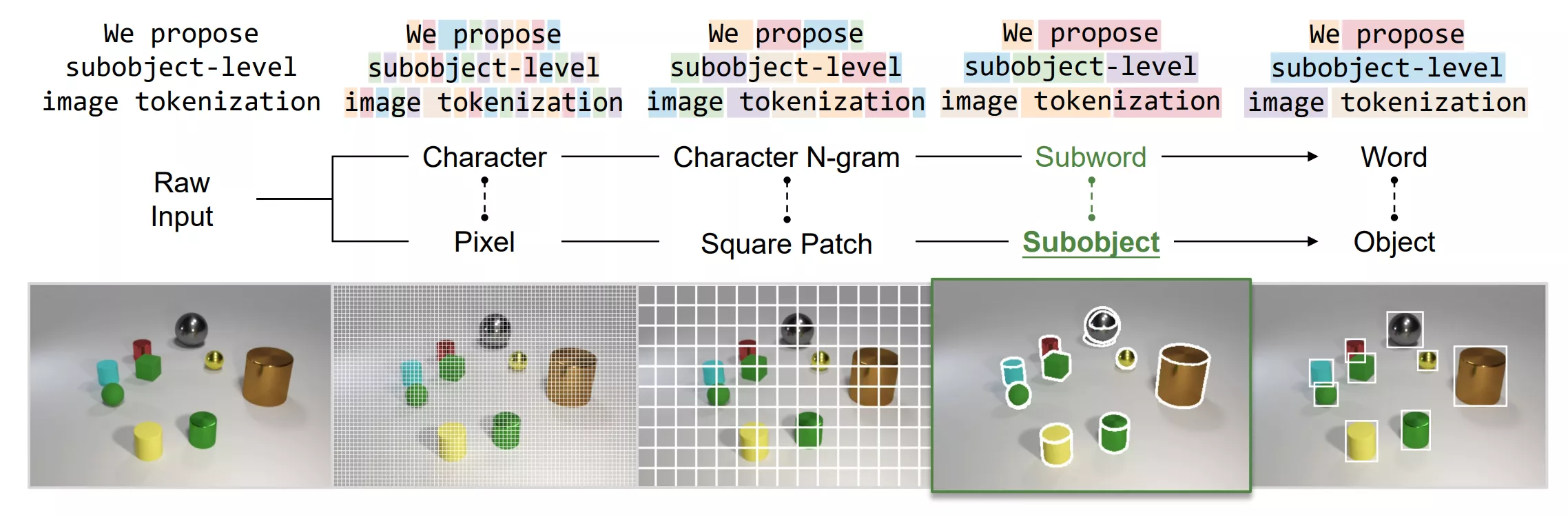
主要功能:
- 提高图像处理的适应性:通过使用有意义的图像片段,而不是固定大小的块,模型能够更好地适应图像内容。
- 加速视觉-语言学习:通过子对象级标记化,模型能够更快地学习将图像转换为对象和属性描述。
主要特点:
- 子对象表示:使用语义上有意义的图像片段,这些片段是通过图像分割模型获得的。
- 紧凑的嵌入向量:通过序列到序列的自编码器(SeqAE)将不同大小和形状的子对象片段压缩成紧凑的嵌入向量。
- 大型视觉语言模型(LVLM):将子对象标记嵌入到大型语言模型(LLM)中,以进行视觉-语言学习。
工作原理:
- 分割:使用图像分割模型(如SAM)将图像分割成子对象边界。
- 嵌入:通过SeqAE将子对象的原始像素转换为紧凑的向量嵌入。
- 建模:构建一个模型,该模型接受嵌入的子对象标记作为输入,用于视觉-语言学习。
应用场景:
- 图像描述生成:使用子对象级标记化,模型可以更准确地描述图像中的对象、属性(如大小、材质和形状)以及对象数量。
- 视觉问答系统:在视觉问答任务中,子对象级标记化可以帮助模型更好地理解和回答关于图像内容的问题。
- 图像检索和分类:在图像检索和分类任务中,子对象级标记化可以提高模型对图像内容的理解,从而提高检索和分类的准确性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











