Google DeepMind 发布设备端 Gemini 机器人模型:离线运行也能拥有旗舰级能力Google DeepMind 宣布推出其旗舰 AI 模型 Gemini Robotics 的设备端版本,这一视觉-语言-动作(VLA)模型可以在没有互联网连接的情况下直接在机器人上运行,并展现出接近...早报# Gemini 机器人模型# Google DeepMind6个月前01830
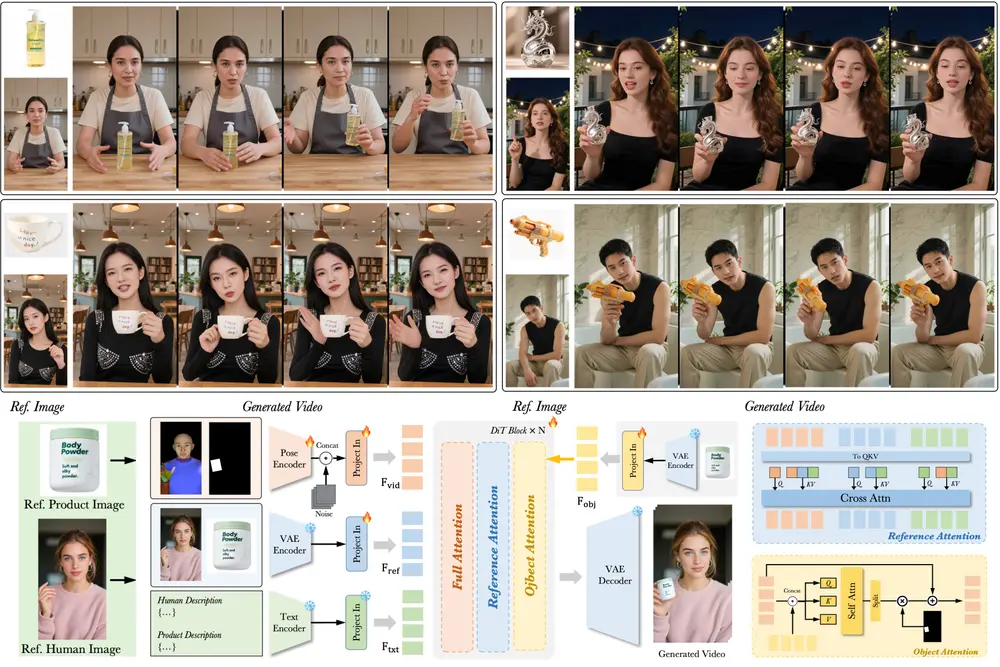
DreamActor-H1:字节跳动推出高保真人类-产品演示视频生成框架在电商广告、虚拟试穿、交互式媒体等场景中,如何高效生成高质量的人类-产品演示视频,一直是视觉生成领域的重要挑战。 近日,字节跳动 AI 实验室提出了一种全新的视频生成框架——DreamActor-H1...新技术# DreamActor-H1# 字节跳动6个月前02650
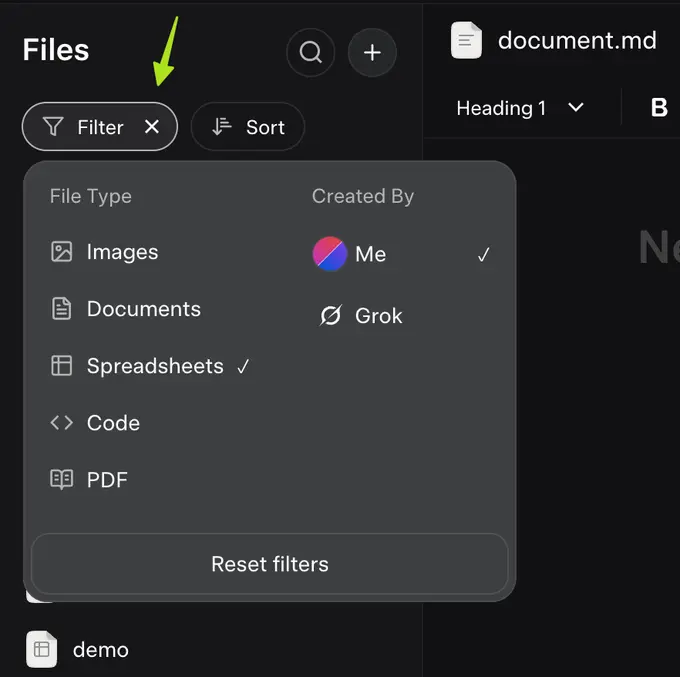
Grok 即将更新:新增集中化文件管理选项卡,提升日常使用效率据最新消息,Elon Musk 旗下的 xAI 团队正在为其 AI 模型 Grok 的网页界面引入一项重要更新——集中化的“文件选项卡”功能。这项改进旨在为用户提供一个统一的文件管理空间,进一步强化 ...早报# Grok# 文件6个月前01970
1亿美元投入AI研究:Databricks联合创始人发起独立科研支持计划周一,计算机科学家、Databricks 和 Perplexity 联合创始人 Andy Konwinski 宣布成立一家新的 AI 研究机构——Laude 研究所,并承诺个人出资 1亿美元,用于支持...早报# Andy Konwinski# Databricks# Perplexity6个月前01490
腾讯混元推出新型框架 Hunyuan-GameCraft:为游戏环境生成高动态、交互式的视频内容腾讯混元项目组和华中科技大学的研究人员推出新型框架 Hunyuan-GameCraft,为游戏环境生成高动态、交互式的视频内容。Hunyuan-GameCraft 能够从单张图像和对应的提示出发,生成...新技术# Hunyuan-GameCraft# 腾讯混元6个月前03160
美国参议院通过AI监管暂停措施关键程序步骤当地时间周六,美国参议院一项旨在暂停各州对人工智能(AI)进行独立监管的提案,成功通过了一个关键的立法程序障碍。 这项规则由参议院商务委员会主席、共和党议员Ted Cruz提出并重写,目的是使其符合预...早报# AI监管# 美国参议院6个月前01950
OpenAI撤下Jony Ive相关宣传内容,因商标纠纷遭法院限制令OpenAI从其官网和YouTube频道中移除了一段曾引发广泛关注的视频内容。该视频重点展示了公司CEO Sam Altman与苹果前首席设计官 Jony Ive 之间的合作关系,并提及OpenAI以...早报# Jony Ive# OpenAI6个月前01580
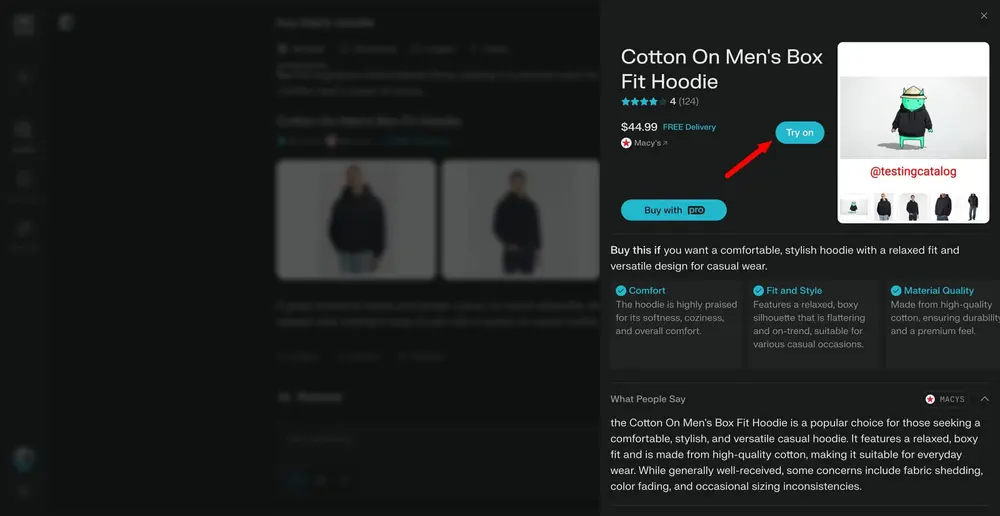
Perplexity 开发 AI 试穿功能,助力在线购物“所见即所得”在线购物虽然方便,但“看不到实物”始终是用户的一大顾虑。为了解决这一痛点,Perplexity 正在开发一项基于人工智能的“虚拟试穿”功能,让用户在购买服装前,能通过上传个人照片生成穿着效果预览图,从...早报# AI 试穿# Perplexity6个月前03400
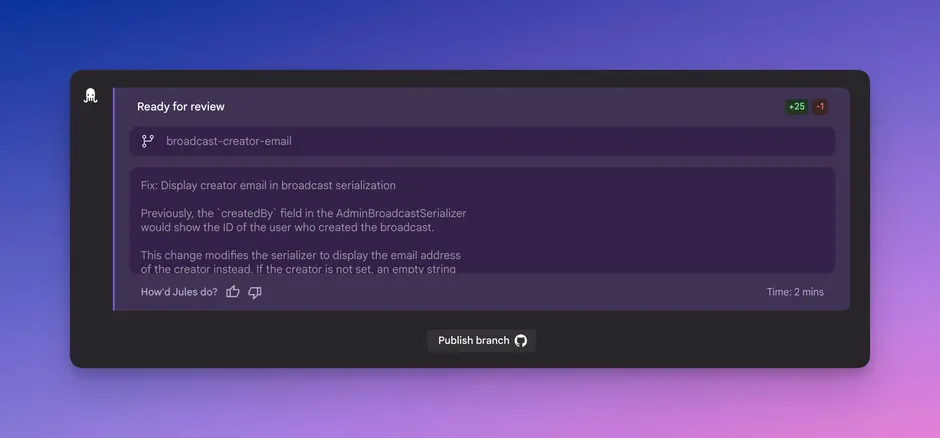
Jules代理升级:更强的上下文感知能力与自动化性能提升Jules 是谷歌推出专注于软件开发自动化的 AI 代理工具,尤其适用于那些项目结构复杂、有特定配置需求的代码仓库。近日,Jules 推出了新一轮重要更新,带来了多项改进,显著增强了其在实际开发场景中...早报# Jules# 谷歌6个月前02020
微软 Copilot 或已免费上线 ChatGPT 的 o4-mini-high 模型?微软 Copilot 虽然在用户认知中不如 ChatGPT 那么热门,但它一直在悄悄提供一些原本需要付费才能使用的 GPT 功能。最近有用户测试发现,Copilot 的“Think Deeper”功能...早报# Copilot# o4-mini-high# 微软6个月前02490
Cloudflare CEO:AI爬虫正在侵蚀互联网的商业模式Cloudflare 首席执行官 Matthew Prince 近日再次发声,警告生成式人工智能(AI)驱动的爬虫和摘要技术,正在对互联网的内容生态和商业模式构成“存在性威胁”。 他指出,随着 AI ...早报# AI# Cloudflare6个月前01730
AI 音乐泛滥?Deezer 推出标签系统,让听众看清“谁”在唱歌随着 AI 技术在音乐创作领域的广泛应用,流媒体平台正面临一个前所未有的挑战:大量由 AI 生成的曲目涌入平台,试图通过虚假播放量牟取版税收益。 为应对这一趋势,全球知名音乐流媒体服务 Deezer ...早报# AI 音乐# Deezer6个月前02610