亚马逊发法律威胁,要求 Perplexity 关闭电商代理浏览功能一场关于 AI 智能体身份的法律博弈,正在重塑互联网的底层规则。 亚马逊向 AI 搜索引擎公司 Perplexity 发出法律警告,要求其 AI 购物助手 Comet 停止在亚马逊网站上代用户购物。P...早报# Perplexity# 亚马逊4个月前0270
微软用“假市场”测试 AI 智能体,结果暴露了严重短板AI 智能体(AI Agent)被广泛视为下一代人机交互的核心,但它们真的准备好独立工作了吗?微软最新研究给出了一个谨慎的答案:还远未达到可靠水平。 近日,微软与亚利桑那州立大学合作发布了一项新研究...早报# Magentic Marketplace# 微软4个月前0820
Tinder 用 AI 分析你的相册:是精准匹配,还是隐私让步?在连续九个季度付费用户下滑后,Tinder 正试图用 AI 重获用户信任与参与度。 近日,Match Group 在财报电话会上披露,Tinder 正在测试一项名为 “Chemistry” 的新功能...早报# Tinder4个月前0260
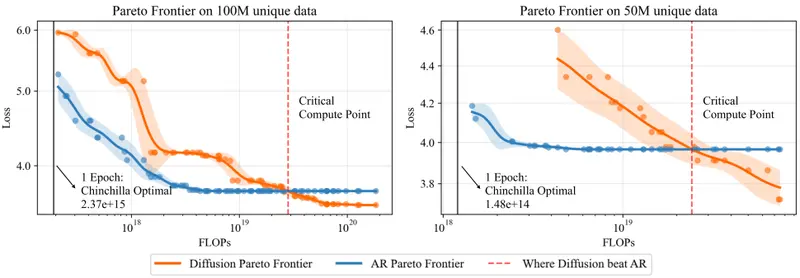
Inception 融资 5000 万美元,用扩散模型重塑代码生成在 AI 初创公司密集融资的背景下,一家由斯坦福大学教授 Stefano Ermon 领衔的新锐企业 Inception 宣布完成 5000 万美元种子轮融资,由 Menlo Ventures 领投...早报# Inception# 扩散模型4个月前0320
谷歌启动 Project Suncatcher,用轨道太阳能驱动太空 AI 数据中心谷歌正在研究一个极具前瞻性的能源与计算方案——将 AI 数据中心送入太空。该项目名为 Project Suncatcher,旨在通过部署运行在低地球轨道上的太阳能卫星,为大规模 AI 计算提供持续、高...早报# AI# 太空# 谷歌4个月前0340
彭博社报道苹果向谷歌付费为其打造基于Gemini的定制模型以用于Siri苹果此前曾因技术挑战将新版Siri的发布推迟至2026年。然而,彭博社最新报道称,AI增强版Siri可能会在明年3月至4月期间推出。苹果也已开始与谷歌合作,将基于Gemini的模型集成到新版Siri中...早报# Siri# 苹果4个月前0230
微软计划至2029年在阿联酋AI与云基础设施领域投资79亿美元G42是阿联酋的主权人工智能公司,总部位于阿布扎比。早在2023年,微软就与其签署了谅解备忘录,以探索联合业务开发和市场营销机会。随后在2024年,微软宣布向G42进行15亿美元的股权投资,旨在通...早报# G42# 微软4个月前0250
微软签署97亿美元协议以确保其AI算力供应微软已与数据中心运营商IREN签署了一项价值97亿美元的协议,以获取英伟达芯片。通过支付这笔巨额资金,微软获得了英伟达先进芯片的使用权,这有助于缓解其制约其从AI热潮中充分获益的算力短缺问题。微软的预...早报# 微软4个月前0240
OpenAI 与 AWS 签署价值 380 亿美元的 AI 基础设施合作伙伴关系OpenAI宣布与 AWS 达成一项重大的AI云基础设施合作伙伴关系。直到今年年初,微软 Azure 还与 OpenAI 拥有独家合作伙伴关系,为其提供 AI 和云基础设施。 由于 OpenAI 对算...早报# AWS# OpenAI4个月前0530
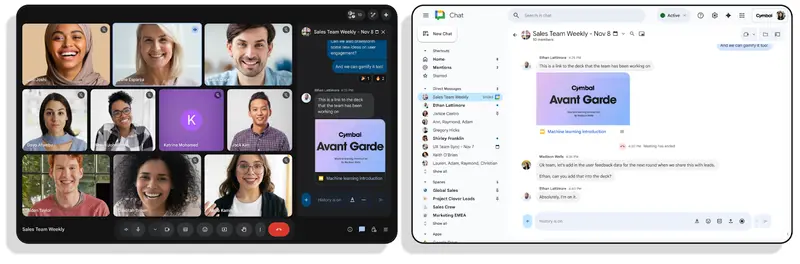
Google Meet 更新:会中消息自动转入 Chat,支持文件与表情回复从 2025 年 11 月 10 日起,Google Meet 将推出一项重要更新:会议中的聊天内容将自动同步至 Google Chat 对话,实现会前、会中、会后的信息无缝延续。 解决了什么问题? ...早报# Google Meet4个月前0510
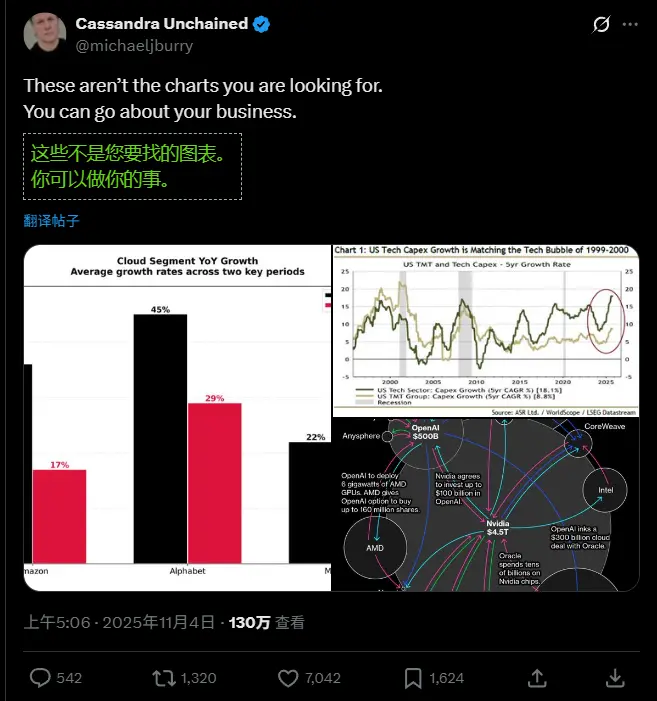
Michael Burry 大举做空英伟达与 Palantir,押注 AI 泡沫破裂以精准预判 2008 年次贷危机闻名的 Michael Burry,正再次采取逆向策略。其管理的 Scion Asset Management 最新披露文件显示,截至 2025 年 9 月 30 日...早报# Michael Burry# 英伟达4个月前0530
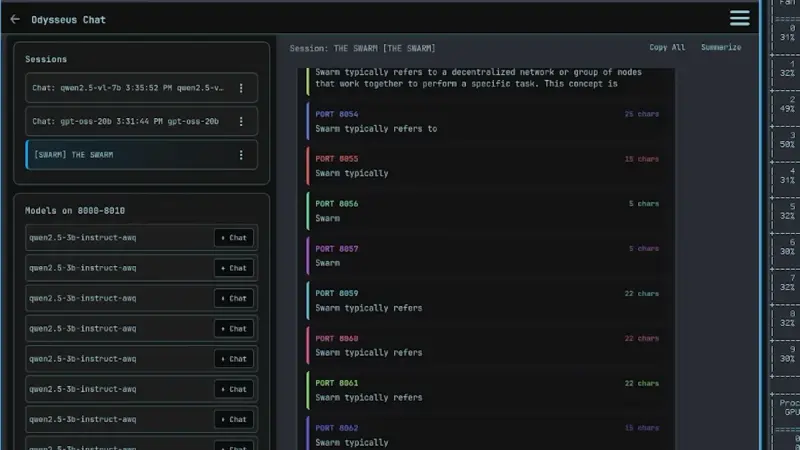
PewDiePie 自建 10 卡 GPU 阵列,全力投入自托管 AI 与模型训练昔日 YouTube 顶流 PewDiePie(Felix Kjellberg)正悄然转型为 AI 实践者。在最新视频中,他展示了其自建的“迷你数据中心”——一台搭载 2×RTX 4000 Ada ...早报# PewDiePie4个月前0160