Gemma模型生成虚假信息,谷歌紧急下架谷歌已从其 AI Studio 平台下架开源模型 Gemma,起因是该模型在回答用户提问时,编造了针对美国参议员玛莎·布莱克本(Marsha Blackburn)的严重虚假刑事指控。 事件源于布莱克本...早报# Gemma4个月前0470
集英社严正警告 OpenAI:Sora 2 若侵权,将采取法律行动日本最大漫画出版社之一 集英社(Shueisha)近日就 OpenAI 新一代视频生成模型 Sora 2 发表强硬声明,明确表示:若确认其生成内容侵犯旗下作品的著作权,将“采取适当且严正的应对措施...早报# OpenAI# Sora 2# 集英社4个月前01410
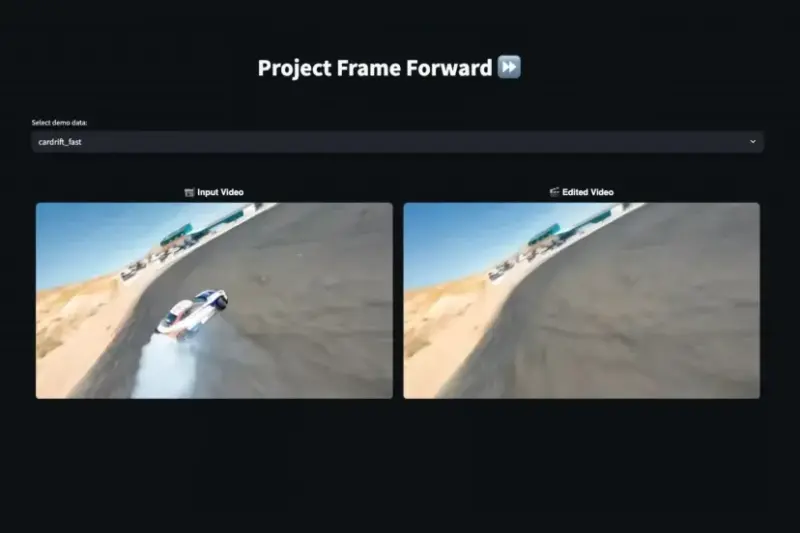
Adobe Max 展示三大 AI 视频编辑实验:一帧改全片、光影重绘、语音可编辑在近期 Adobe Max 大会上,Adobe 展示了一系列名为 “Sneaks” 的实验性 AI 工具,探索未来创意工作的可能性。这些原型虽尚未正式上线,但其中多项技术已展现出极高的实用潜力——部分...早报# Adobe MAX4个月前0350
英伟达拟投资至多 10 亿美元,参与 Poolside 20 亿美元融资据彭博社报道,英伟达计划在 AI 初创公司 Poolside 的最新一轮融资中投资 5 亿至 10 亿美元。此轮融资目标为 20 亿美元,投前估值达 120 亿美元,较其 2023 年约 30 亿美元...硬件# Poolside# 英伟达5个月前0270
英特尔洽谈收购 AI 芯片公司 SambaNova,估值或低于 50 亿美元据知情人士透露,英特尔正与 AI 芯片初创公司 SambaNova Systems 就潜在收购进行初步谈判。目前双方仍在评估条款,交易尚未确定,且不排除其他买家介入的可能。 若交易达成,SambaNo...硬件# SambaNova# 英特尔# 陈立武5个月前0220
OpenAI 开始销售 Sora 额外生成额度,未来或减少免费配额OpenAI 已通过苹果 App Store 向用户提供 Sora 视频生成工具的额外积分购买选项:用户可支付 4 美元 购买 10 次额外视频生成额度。 目前,Sora 对所有用户每日提供 30 次...早报# OpenAI# Sora5个月前0690
三星与英伟达共建 AI 赋能半导体工厂,部署 5 万 GPU 优化制造全流程三星电子宣布与英伟达合作,建设一座AI 深度集成的半导体制造工厂(非传统 AI 数据中心),将AI嵌入芯片设计、制造、设备运维与质量控制的全链条。 该工厂将部署超过 50,000 台英伟达最新 GPU...硬件# 三星# 英伟达5个月前0270
Getty Images 与 Perplexity 达成多年图像许可协议Getty Images 与 AI 搜索平台 Perplexity 宣布达成多年期许可协议。根据协议,Perplexity 将通过 Getty 的 API 在其 AI 驱动的搜索结果中直接调用并展示 ...早报# Getty Images# Perplexity5个月前0230
Perplexity 推出自然语言专利检索工具,支持语义扩展与摘要生成Perplexity 近日上线一项新功能:AI 驱动的专利研究智能体,允许用户通过自然语言查询专利,无需依赖传统关键词组合。 传统专利检索依赖精确术语,容易遗漏语义相近但用词不同的技术方案。Perpl...早报# Perplexity# 专利检索5个月前0330
IPO 传闻背后:OpenAI 估值或超万亿美元,但亏损持续扩大据路透社报道,OpenAI 正在为首次公开募股(IPO)做准备,最早可能于 2026 年下半年提交申请,目标上市时间为 2027 年。公司 CEO Sam Altman 表示,IPO 是“最可能的路径...早报# OpenAI5个月前0220
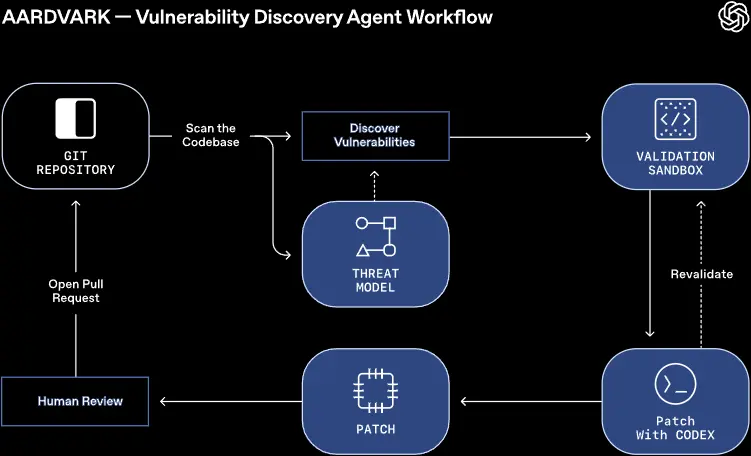
OpenAI发布智能安全研究助手Aardvark:基于 GPT-5 的自动漏洞发现与修复工具OpenAI 于 10 月 30 日发布 Aardvark——一款基于 GPT-5 的 AI 安全研究助手,目前开放私有测试版。该工具旨在帮助开发与安全团队自动发现、验证并修复代码中的安全漏洞。 核心...早报# Aardvark# OpenAI# 安全研究助手5个月前0190
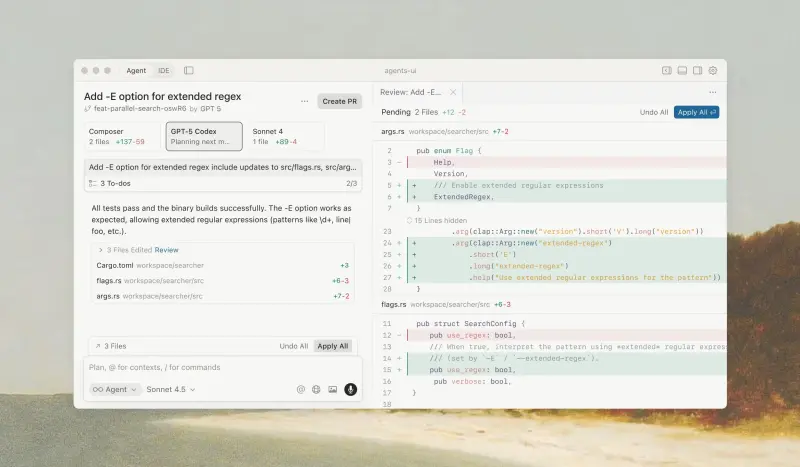
Cursor 2.0 发布:推出自研模型 Composer 与多智能体协作界面AI编程编辑器 Cursor 正式发布 2.0 版本,核心更新包括自研智能体模型 Composer 与以多智能体为中心的新用户界面,旨在提升大型项目中的协作效率与开发响应速度。 Composer:面向...早报# Composer# Cursor 2.05个月前0290