在 AI 初创公司密集融资的背景下,一家由斯坦福大学教授 Stefano Ermon 领衔的新锐企业 Inception 宣布完成 5000 万美元种子轮融资,由 Menlo Ventures 领投,吴恩达(Andrew Ng)与安德烈·卡帕西(Andrej Karpathy)参与天使投资。
这家初创公司的目标很明确:将已在图像生成领域大放异彩的扩散模型(Diffusion Models),引入文本与代码生成领域,挑战当前主流的自回归架构。
技术路径的另类选择
当前绝大多数大语言模型(如 GPT-5、Gemini)采用自回归方式生成文本——逐个预测下一个词元,像“打字机”一样顺序输出。这种方式虽然成熟,但在处理长上下文或大规模代码重构时,面临高延迟与高计算成本的问题。
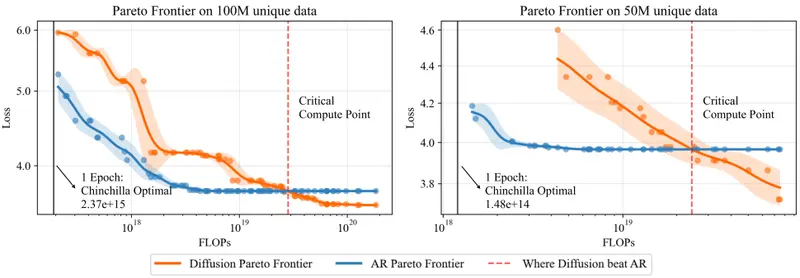
而 Inception 选择的是另一条技术路线:基于扩散的生成机制。
其原理类似于 Stable Diffusion 和 Sora 的工作方式:
- 模型首先生成一个“噪声化”的初始响应
- 然后通过多轮迭代去噪,逐步优化输出结构
- 最终得到符合语义和语法的高质量结果
这一过程天然支持并行计算,可在 GPU 上高效展开,显著降低端到端响应时间。
核心优势:速度与效率
根据 Inception 团队披露的信息,其新一代 Mercury 模型在基准测试中实现了每秒处理 超过 1000 个 token 的性能,远超当前主流自回归模型的吞吐极限。
关键优势包括:
- 更低延迟:并行去噪机制减少序列依赖,提升响应速度
- 更优硬件利用率:更适合现代 GPU 架构,降低单位推理成本
- 更强长程建模能力:适合处理大型代码库的重构、迁移与审查任务
目前,Mercury 模型已集成至 ProxyAI、Buildglare、Kilo Code 等开发工具链中,服务于实际编码场景。
为什么现在是扩散模型的机会?
尽管扩散模型在图像领域已成主流,但在文本生成方面长期被视为“潜力股”。然而,随着对推理效率和能耗控制的要求提高,其优势正被重新评估。
Stefano Ermon 指出:“这是一个完全不同的技术范式,仍有巨大创新空间。” 尤其是在软件工程这类需要高精度、低延迟、大规模上下文理解的领域,扩散模型可能成为下一代代码智能的核心引擎。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











