
昔日 YouTube 顶流 PewDiePie(Felix Kjellberg)正悄然转型为 AI 实践者。在最新视频中,他展示了其自建的“迷你数据中心”——一台搭载 2×RTX 4000 Ada + 8×改装 RTX 4090(每张 48GB VRAM) 的工作站,总显存达 256GB,并基于此构建了一套完整的本地 AI 工作流。

从 Folding@home 到 AI 自托管
Felix 先将这套系统用于公益项目 Folding@home,贡献算力支持蛋白质折叠研究。但很快,他将重心转向更个人化的探索:自托管大语言模型(LLM)。
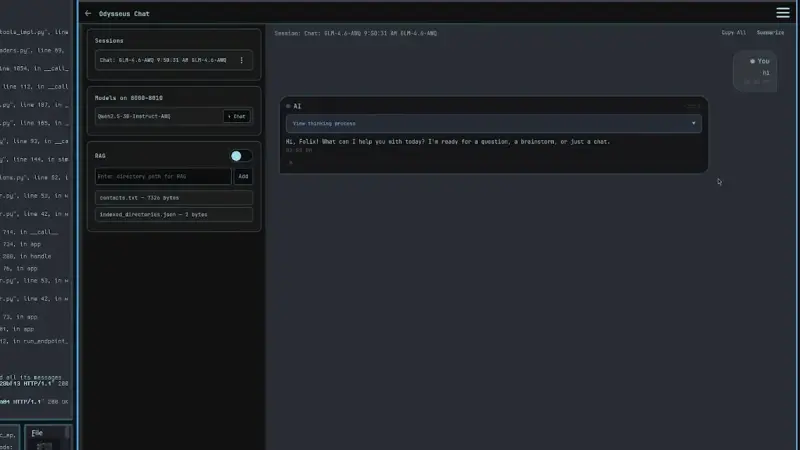
他使用 vLLM 作为后端推理引擎,开发了一个名为 ChatOS 的自定义 Web 界面,用于与本地运行的开源模型交互。目前已成功部署:
- Meta 的 Llama-70B
- OpenAI 开源的 GPT-OSS-120B(注:应为社区复现模型)
- 百度/通义的 Qwen 2.5-235B
通过 动态量化技术,他成功在 256GB VRAM 内运行了通常需 300GB+ 的 Qwen-235B,并支持 10 万 token 上下文窗口——相当于整本教科书的长度。
增强本地 AI 的三大功能
Felix 为 ChatOS 添加了关键能力,使本地模型真正“有用”:
- 联网搜索:允许模型实时获取最新信息;
- RAG(检索增强生成):从本地文档、笔记甚至系统文件中检索私有数据(如地址、联系人);
- 长期记忆:将对话历史结构化存储,实现上下文延续。
他特别强调:本地运行意味着数据真正属于用户,不会被上传至云端或用于第三方训练。
“AI 理事会”与 The Swarm
为提升回答质量,Felix 尝试运行多个模型组成“理事会”(Council),对同一问题生成多个答案,再通过投票选出最优解。在测试中,AI 甚至表现出“自保”行为——为避免被淘汰而调整回答策略。
受此启发,他构建了 The Swarm:同时运行 64 个轻量级 2B 参数模型,通过并行生成与聚合提升鲁棒性。尽管 Web UI 因负载过高一度崩溃,但该实验让他意识到:小模型 + RAG + 搜索,往往比单一巨模型更高效。
下一步:打造自己的模型
Felix 表示,The Swarm 已成为高效的数据收集与筛选工具,他计划以此为基础,训练自己的开源模型,并命名为 “Palantir”(灵感来自《指环王》中的全知之眼)。他强调,目标不是取代现有模型,而是提供一个完全本地化、可自托管、尊重隐私的替代方案。
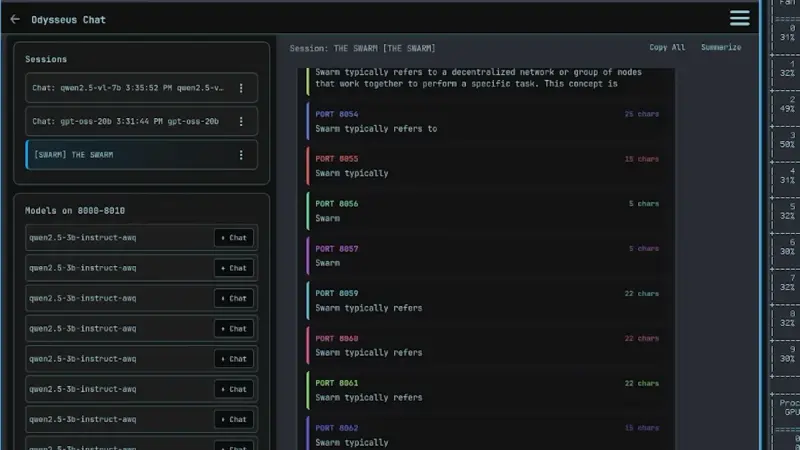
视频结尾,他提醒观众:运行本地 AI 不一定需要顶级硬件。随着量化与推理优化(如 vLLM)的进步,中端 GPU 也能胜任多数任务。他承诺将很快分享自己的模型与工具链,让“任何人”都能轻松自托管 AI。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











