商汤研究院推出文本嵌入模型Piccolo2商汤研究院推出文本嵌入模型Piccolo2,它在多个任务上的表现超越了其他模型,并在CMTEB基准测试中创下了新的最高标准。文本嵌入是一种将文本转换成数值向量的技术,这些向量能够捕捉单词、短语或整篇文...新技术# Piccolo2# 商汤研究院# 文本嵌入模型2年前07740
新型视频生成模型HPDM:通过分层处理和上下文融合技术,生成高分辨率视频Snap、阿卜杜拉国王科技大学和特伦托大学的研究人员推出新型视频生成模型Hierarchical Patch Diffusion Models(HPDM,分层补丁扩散模型),这个模型专门设计用于高分辨...新技术# HPDM# 分层补丁扩散模型# 视频生成2年前07720
Adobe推出图像生成模型Firefly Image 3:逼真度、造型能力、细节和精确度方面均取得了显著进步Adobe在昨天的Adobe Max大会上正式发布了图像生成模型Firefly Image 3。这款模型在逼真度、造型能力、细节和精确度方面均取得了显著进步,同时提供了更加丰富的多样性,为创意人士带来...早报# Adobe# Firefly Image 32年前07720
无需调整的高分辨率框架HiDiffusion:只需添加一行代码即可提高扩散模型(Stable Diffusion)在生成高分辨率图像方面的能力和效率旷视科技与字节跳动的研究人员推出新型框架HiDiffusion,只需添加一行代码即可提高扩散模型(Stable Diffusion)在生成高分辨率图像方面的能力和效率。现有的扩散模型在生成超出训练时所...新技术# HiDiffusion# Stable Diffusion# 高分辨率框架2年前07700
专注于二次元角色的动画方法MikuDance:将二次元角色根据 Open Pose 姿势生成对应动画武汉大学、阶跃星辰和字节跳动的研究人员推出MikuDance,它是一个基于扩散的动画制作流程,用于为风格化的角色艺术作品添加混合运动动力学,使其动起来。MikuDance的核心在于它能够处理复杂的角色...新技术# MikuDance# 二次元1年前07670
多模态模型Transfusion:能够同时处理离散数据(如文本)和连续数据(如图像)Meta、Waymo和南加州大学的研究人员推出多模态模型Transfusion,它能够同时处理离散数据(如文本)和连续数据(如图像)。Transfusion的核心思想是将语言模型的下一个词预测(nex...新技术# Transfusion# 多模态模型2年前07660
Meta推出新型框架OPT2I:通过优化文本提示(prompt)来提高文生图模型的图像与输入提示的一致性Meta推出新型框架OPT2I,它旨在通过优化文本提示(prompt)来提高文本到图像(T2I)生成模型的图像与输入提示的一致性。尽管现有的T2I模型能够生成高质量和逼真的图像,但它们在确保生成的图像...新技术# OPT2I# 提示词# 文生图模型2年前07650
3D场景生成技术BlockFusion:基于扩散模型的方法来创建和扩展3D场景来自腾讯、东京大学、澳大利亚国立大学、上海交通大学的研究人员推出新型3D场景生成技术BlockFusion,它使用基于扩散模型的方法来创建和扩展3D场景。 论文 BlockFusion的核心思想是将3...新技术# 3D场景生成# BlockFusion2年前07650
新型图像编辑框架3DitScene:通过语言引导的解耦高斯散射来实现对任何场景图像的编辑香港中文大学、斯坦福大学、Snap、加州大学洛杉矶分校和字节跳动的研究人员推出新型图像编辑框架3DitScene,它能够通过语言引导的解耦高斯散射(Language-guided Disentangl...新技术# 3DitScene# 图像编辑框架2年前07630
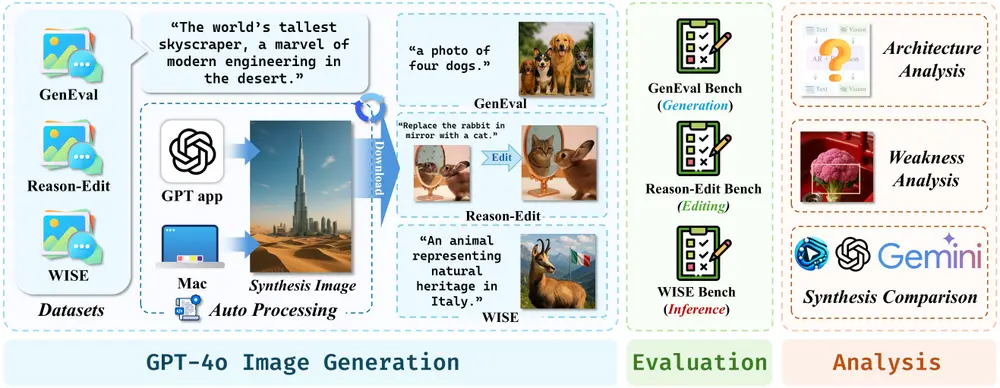
首个针对 GPT-4o 图像生成能力进行定量和定性评估的基准测试GPT-ImgEval北京大学深圳研究生院、中山大学、Rabbitpre AI、上海人工智能实验室、深圳大学和香港科技大学(广州)的研究人员发布首个针对 GPT-4o 图像生成能力进行定量和定性评估的基准测试GPT-Img...新技术# GPT-4o# GPT-ImgEval1年前07620
新型框架PhysAvatar:将物理模拟和逆向渲染技术相结合,创建逼真的3D虚拟人物来自斯坦福大学、卡内基梅隆大学、谷歌和慕尼黑工业大学的研究人员推出新型框架PhysAvatar,它将物理模拟和逆向渲染技术相结合,能够自动从多视角视频数据中估计人体的形状和外观,以及衣物面料的物理参数...新技术# 3D虚拟人物# PhysAvatar2年前07620
无需训练的概率并行解码算法SJD:用于加速自动回归文本到图像的生成模型香港大学、华为诺亚方舟实验室、香港中文大学、清华大学、上海交通大学和无问芯穹的研究人员推出一种无需训练的概率并行解码算法SJD(猜测性雅可比解码),用于加速自动回归文本到图像的生成模型。自动回归模型在...新技术# SJD# 解码算法2年前07610