微调模型TCD:提高图像生成的速度和质量来自华南理工、南洋理工、北理工和悉尼大学的研究人员推出TCD(Trajectory Consistency Distillation),这是一种用于加速文生图模型图像生成的微调模型。TCD的目标是提高...新技术# TCD# 微调模型2年前08210
Claude Code:智能编码最佳实践指南Anthropic于2月25日发布了 Claude Code,这是一个用于智能体编程(agentic coding)的命令行工具。作为研究项目开发,Claude Code 为 Anthropic 的工...教程# Claude Code# 智能编码12个月前08200
用于视频合成的交互式工具Image Conductor:让用户对视频内容中的相机运动和对象移动进行精细且准确的控制北京大学、腾讯PCG ARC实验室、南洋理工大学、 清华大学、澳门大学和深圳先进技术研究院的研究人员推出Image Conductor,它是一种用于视频合成的交互式工具,能够让用户对视频内容中的相机运...新技术# Image Conductor# 视频合成2年前08180
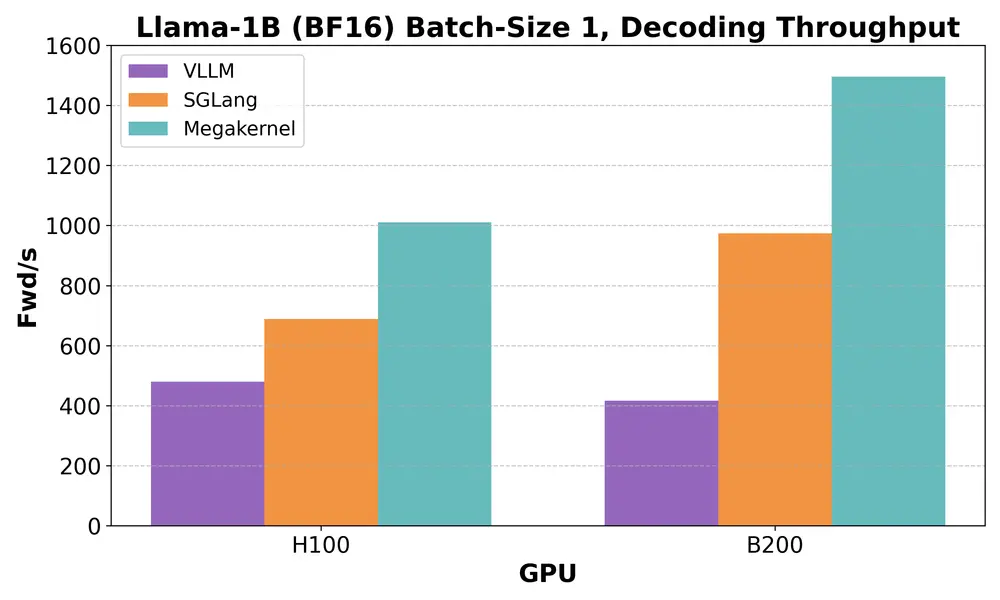
用“Megakernel”打破LLM推理瓶颈:斯坦福Hazy Research实现Llama-1B史上最低延迟在一些对响应速度极为敏感的应用场景中,例如对话式 AI 或人机协同的工作流系统,语言模型的推理延迟不仅影响效率,更直接影响用户体验。 以 Llama-3.2-1B 这类小型开源模型为例,在单序列生成任...新技术# Llama-1B# Megakernel10个月前08160
图像编辑技术ObjectDrop:专注于实现照片级别的物体移除和插入来自谷歌和耶路撒冷希伯来大学的研究团队推出图像编辑技术ObjectDrop,专注于实现照片级别的物体移除和插入。这项技术的目标是在不违反物理规律(例如遮挡、阴影和反射)的前提下,对图像进行编辑,使得编...百科# ObjectDrop# 图像编辑2年前08160
新型3D生成算法MicroDreamer:能够在大约20秒内生成高质量的3D模型,而无需任何3D数据来自中国人民大学、清华大学和快手的研究人员推出新型3D生成算法MicroDreamer,它能够在大约20秒内生成高质量的3D模型,而无需任何3D数据。这项技术基于一种称为“基于分数的迭代重建”(Sco...新技术# 3D生成算法# MicroDreamer2年前08130
多概念定制技术MultiBooth:根据用户的文本描述生成包含多个特定元素的图像清华大学和Meta的研究人员推出新颖且高效的多概念定制技术MultiBooth,此技术用于从文本生成图像时实现多概念定制。简单来说,MultiBooth能够根据用户的文本描述生成包含多个特定元素的图像...新技术# MultiBooth# 多概念定制技术2年前08120
Stable Diffusion绘画中常用的LoRA模型是什么?在使用Stable Diffusion进行AI绘画的时候,最常用的除了大模型应该就是LoRA模型,你知道LoRA是是什么吗?你知道LoRA技术其实最初是由微软技术人员为了解决大语言模型微调而开发的吗...科普# Civitai# LiblibAI# Lora2年前08120
深度模型DepthFM:从单张图像中快速估算深度信息来自慕尼黑大学的研究团队推出深度模型DepthFM,它是一个用于从单目(单个摄像头)图像中快速估算深度信息的系统。简单来说,DepthFM能够通过一张照片,推断出物体与摄像头之间的距离,这对于三维场景...新技术# DepthFM# 深度模型2年前08110
ToDo:为了提高高分辨率图像生成的效率而设计来自Leonardo AI的研究人员推出ToDo(Token Downsampling),它是为了提高高分辨率图像生成的效率而设计的。这种方法主要是为了解决图像扩散模型在处理大图像时面临的时间和内存限...新技术# ToDo# 扩散模型2年前08110
针对姿势引导的人像图像动画技术TCAN:让图片中的人物根据某个动作序列(比如一个视频)来做出相应的动作韩国科学技术院和Naver的研究人员推出一种针对姿势引导的人像图像动画技术TCAN,该技术能有效抵抗姿态估计错误,并在时间维度上保持连贯。这是一个关于如何让静态图片中的人体动作起来的研究,具体来说,就...新技术# TCAN# 人像图像动画2年前08090
弱监督方法CatLIP:用于在互联网规模的图像-文本数据上预训练视觉模型苹果推出新颖的弱监督方法CatLIP(Categorical Loss for Image-text Pre-training),旨在提高图像和文本数据集上的视觉模型预训练效率,同时保持与现有的对比学...新技术# CatLIP# CLIP# 弱监督2年前08090