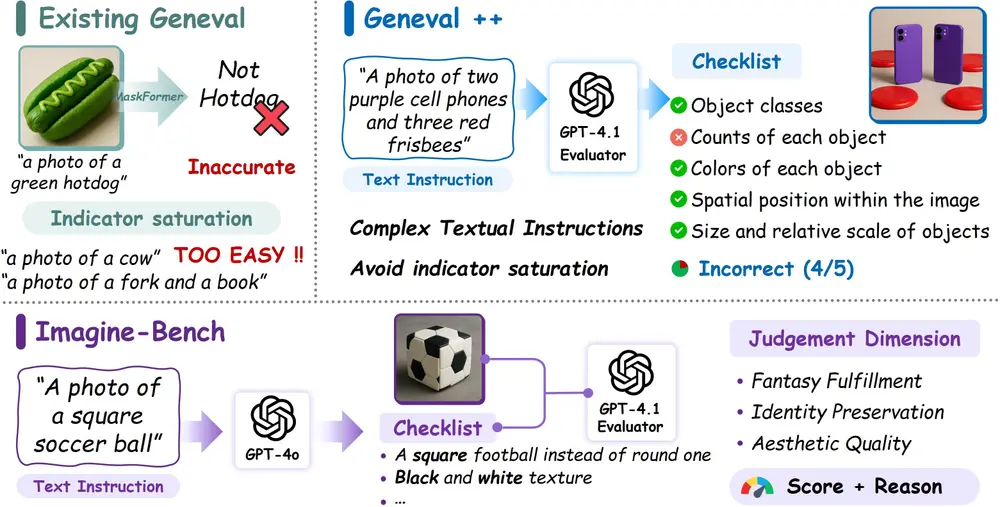
Echo-4o :通过利用 GPT-4o 生成的合成图像数据来提升多模态生成模型的性能上海人工智能实验室、中山大学、香港中文大学和北京大学的研究人员推出 Echo-4o 系统,通过利用 GPT-4o 生成的合成图像数据来提升多模态生成模型(如文本到图像生成、多参考图像生成等任务)的性能...新技术# Echo-4o# GPT-4o# 多模态生成模型7个月前03240
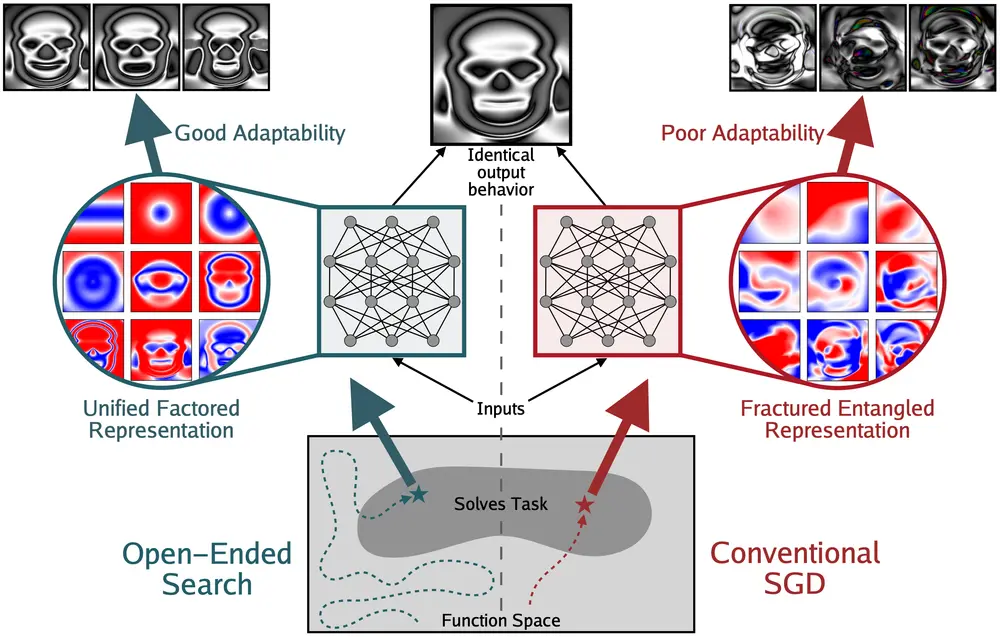
模型变强了,内部表示就更好了吗?MIT等提出“碎片化纠缠表示(FER)”假说当我们看到大模型在各种任务上不断刷新性能纪录时,一个隐含的信念常常浮现:性能提升 = 内部表示更优。这种观点被称为“表示乐观主义”(Representational Optimism)——即认为随着模...新技术# FER# 碎片化纠缠表示7个月前03420
DynamicFace:一种面向图像与视频的高保真人脸交换方法人脸交换(Face Swapping)技术旨在将一个人的身份特征迁移到另一个人的面部图像或视频中,同时保留目标人物的表情、姿态、发型和背景等属性。近年来,随着生成模型的发展,人脸交换已能生成高度逼真的...新技术# DynamicFace# 人脸交换7个月前03880
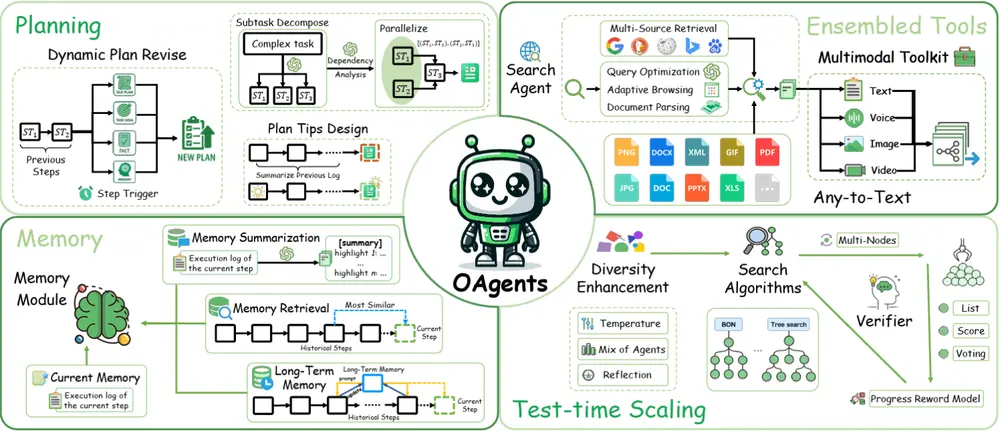
OPPO 发布 OAgents:一个模块化、可复现的基础智能体框架随着“智能体(Agentic AI)”成为 AI 发展的重要方向,各类框架层出不穷。然而,当前研究普遍存在评估标准不一、实现细节不透明、结果难以复现等问题,导致不同系统之间缺乏公平比较的基础。 为应对...新技术# OAgents# OPPO# 智能体框架7个月前01720
字节跳动Seed团队发布WideSearch:首个面向大规模信息收集的智能体评估基准在信息过载的时代,获取“更多”并不等于“更有效”。真正制约效率的,往往不是找不到某个具体答案,而是面对海量目标时的系统性整理能力——比如,为一个行业筛选出上百家公司数据,或从成千上万条招聘信息中精准匹...新技术# WideSearch# 字节跳动# 智能体评估基准7个月前04940
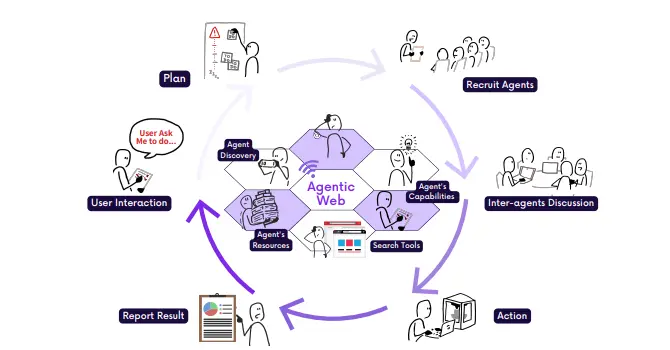
Agentic Web:通过AI智能体(AI Agents)来构建下一代互联网上海交通大学、香港科技大学(广州)、利物浦大学、加州大学伯克利分校、上海创新学院、加州大学戴维斯分校、弗吉尼亚理工大学和伦敦大学学院的研究人员发布Agentic Web(智能体网络),它探讨了如何通过...新技术# Agentic Web7个月前01420
NXN Labs推出新型虚拟试穿框架Voost:通过一个统一的扩散变换器同时实现虚拟试穿(试穿目标服装)和虚拟试脱(从人像中重建原始服装)功能NXN Labs推出新型虚拟试穿框架Voost,通过一个统一的扩散变换器(Diffusion Transformer)同时实现虚拟试穿(试穿目标服装)和虚拟试脱(从人像中重建原始服装)功能。 项目主页...新技术# Voost# 虚拟试穿7个月前03350
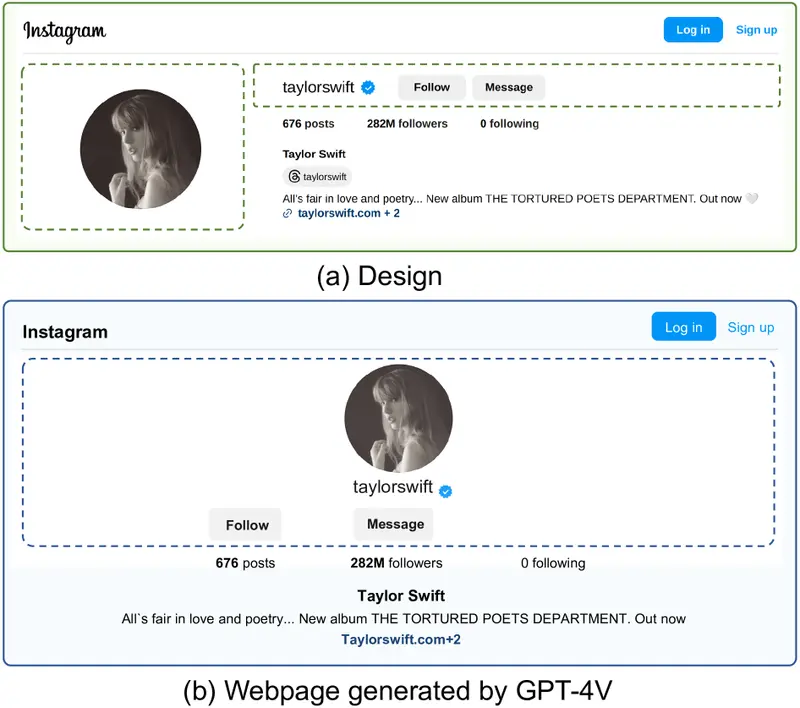
LaTCoder:将网页设计图像自动转换为代码华中科技大学和重庆大学的研究人员提出了一种名为 LaTCoder 的新方法,将网页设计图像自动转换为代码(即设计到代码,design-to-code)。这种方法通过引入“布局即思考”(Layout-a...新技术# LaTCoder7个月前03100
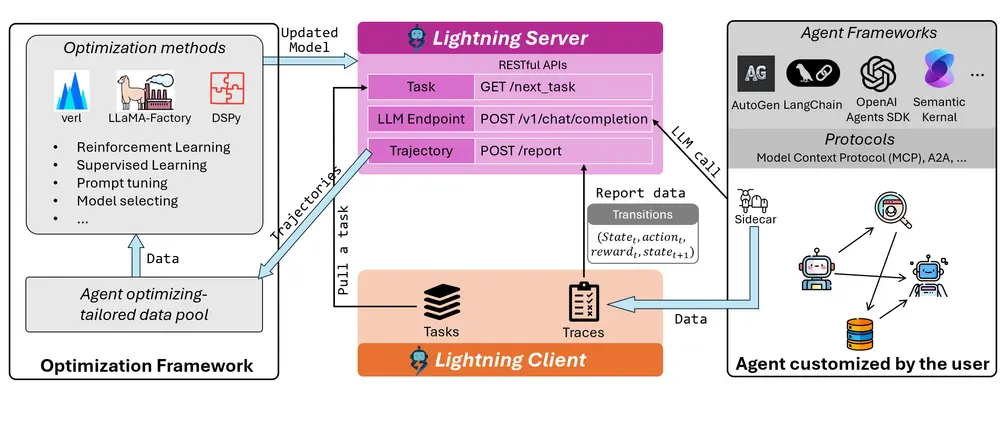
微软推出 Agent Lightning:打通智能体开发与模型优化的“最后一公里”在 AI 智能体(Agent)技术快速发展的当下,开发者已经可以通过 LangChain、AutoGen、OpenAI Agent SDK 等框架,快速构建具备工具调用、多轮对话和任务编排能力的智能系...新技术# Agent Lightning# 微软# 智能体7个月前01400
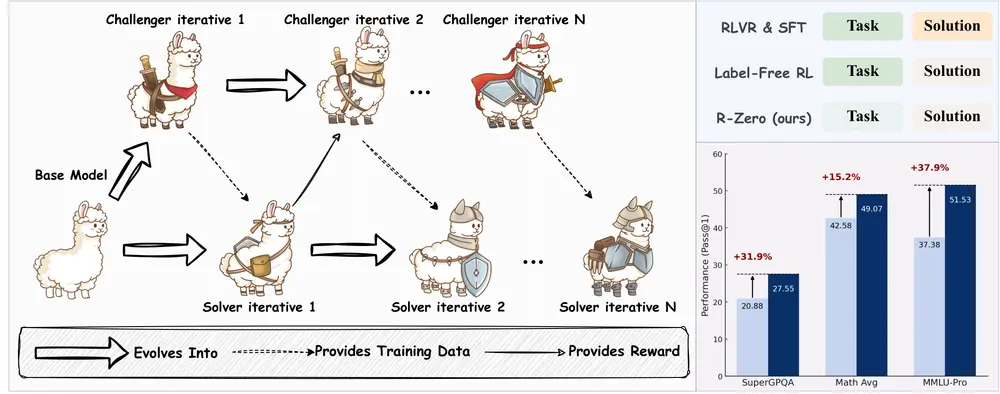
R-Zero:首个完全自进化的推理增强框架,无需数据即可提升大模型能力由腾讯 AI 西雅图实验室、圣路易斯华盛顿大学、马里兰大学帕克分校与德克萨斯大学达拉斯分校联合提出的新框架 R-Zero,正在挑战当前大语言模型训练范式的边界。 项目主页:https://chengs...新技术# R-Zero# 推理增强框架7个月前06870
基于二维高斯分布的图像表示方法Image-GS:通过自适应地分配和优化一组二维高斯分布来重建图像纽约大学、英特尔和AMD的研究人员推出一种基于二维高斯分布的图像表示方法Image-GS,它通过自适应地分配和优化一组二维高斯分布来重建图像。这种方法旨在为图像和纹理提供一种高效、灵活且硬件友好的表示...新技术# Image-GS# 图像表示方法7个月前01960
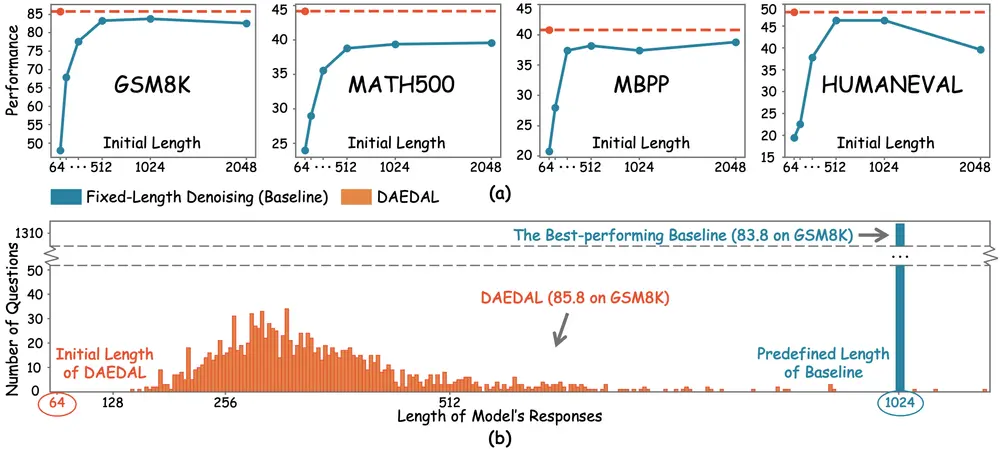
DAEDAL:无需训练的动态长度生成,释放扩散大模型新潜力在大语言模型(LLM)领域,扩散型大语言模型(Diffusion Large Language Models, DLLMs)正凭借其并行生成能力与全局上下文建模优势,成为传统自回归模型(AR)的有力竞...新技术# DAEDAL# 扩散大模型7个月前02890