个性化图像生成新方法ViPer: 通过个体偏好学习实现生成模型的视觉个性化瑞士联邦理工学院的研究人员推出一种个性化生成模型输出的方法ViPer,它可以让生成模型(比如用来生成图片的AI)根据个人的喜好来定制生成的内容。这是通过一次性捕捉用户的总体偏好,并在无需详细工程化提示...新技术# ViPer# 个性化图像生成2年前05890
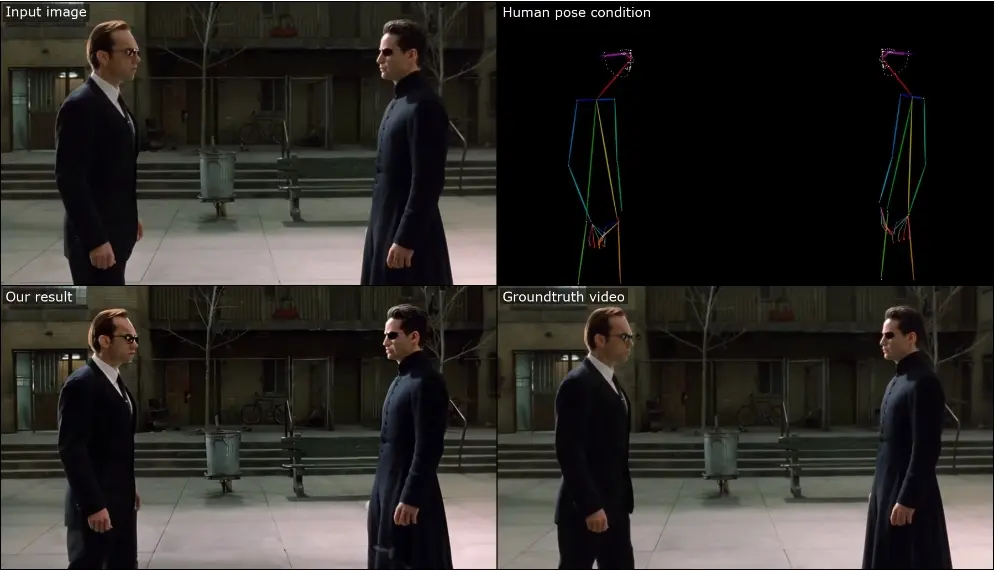
专为人体图像动画设计的大规模高质量数据集HumanVid:结合了精心挑选的真实世界数据和合成数据香港中文大学和上海人工智能实验室的研究人员推出HumanVid,它旨在揭开用于生成逼真人物视频动画的训练数据的神秘面纱。HumanVid是首个为人物图像动画量身定制的大规模、高质量的数据集,它结合了精...新技术# HumanVid2年前09300
文生图风格化工具Artist:无需训练即可实现美学控制的文本驱动风格化香港理工大学的研究人员推出一种无需训练即可实现美学控制的文本驱动风格化方法Artist。简而言之,Artist能够根据文本描述,将一张静态图片转换成具有特定艺术风格的图像,同时保持图片内容的完整性和细...新技术# Artist# 风格化2年前08300
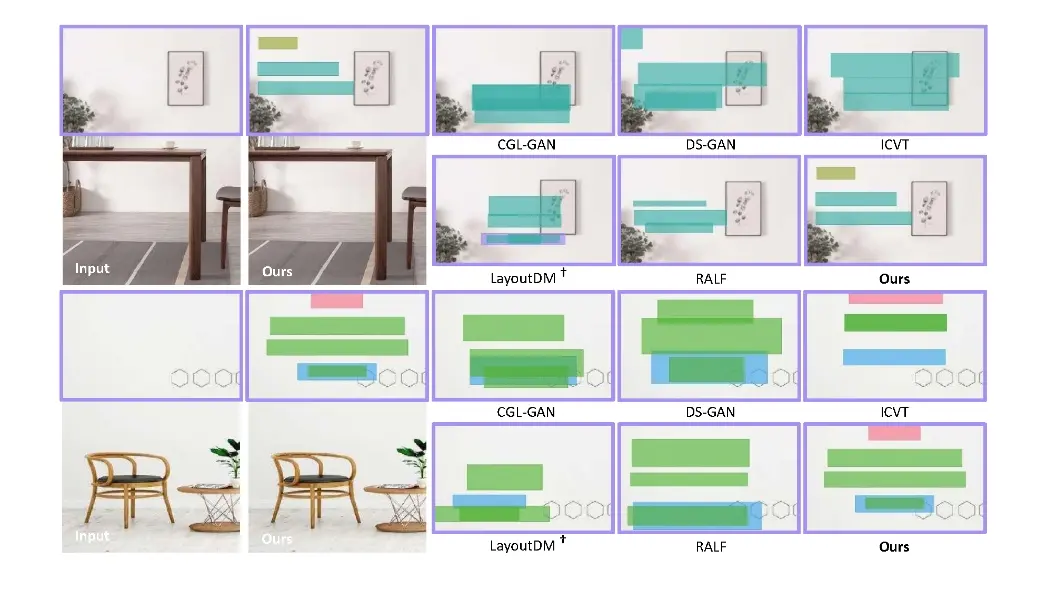
视觉布局CGB-DM:基于Transformer的扩散模型的内容与图形平衡布局生成方法清华大学的研究人员推出基于Transformer的扩散模型的内容与图形平衡布局生成方法CGB-DM,简单来说,CGB-DM是一个智能设计系统,它可以根据文本描述生成既美观又和谐的视觉布局。这就像是给一...新技术# CGB-DM# 视觉布局2年前08760
高度一致且可控制运动的图像动画生成方法Cinemo:将一张静态图片转换成一段视频,并且在转换过程中保持图片原有的细节信息莫纳什大学、上海人工智能实验室和南京邮电大学的研究人员推出Cinemo,它是一种用于图像动画化(也称为图像到视频生成,I2V)的新型方法。简单来说,Cinemo能够将一张静态图片转换成一段视频,并且在...新技术# Cinemo# 图像动画2年前06220
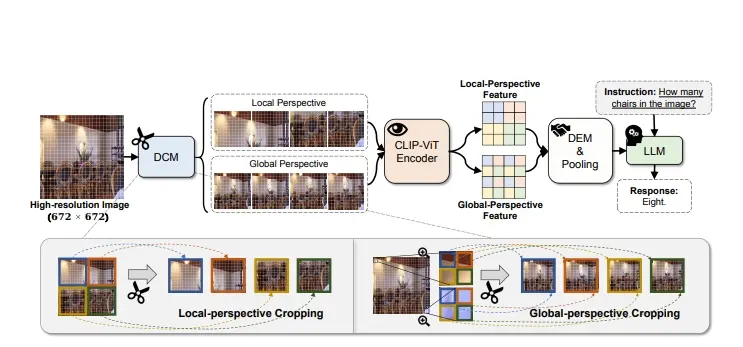
新型多模态大语言模型INF-LLaVA:专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力厦门大学的研究人员推出新型多模态大语言模型INF-LLaVA,它专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力。在人工智能领域,处理高分辨率图像一直是一个挑战,因为这些图像包含的细...新技术# INF-LLaVA# 多模态大语言模型2年前06360
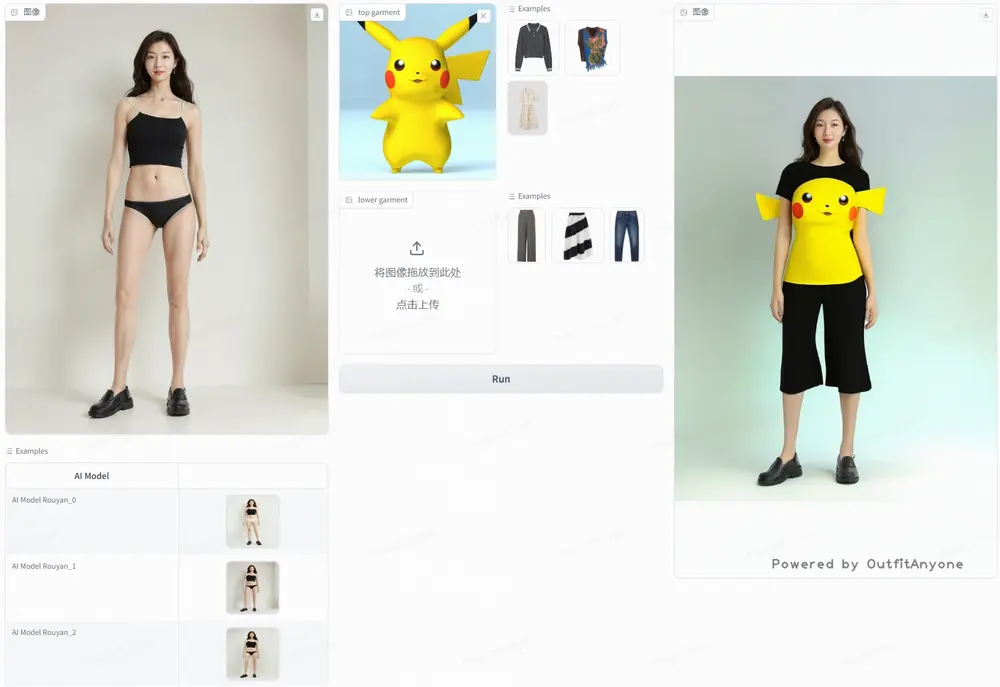
基于扩散模型的2D虚拟试穿框架OutfitAnyone:通过上传自己的照片和想要试穿的衣服图片,就能在线看到衣服穿在自己身上的样子阿里巴巴和中国科学技术大学的研究人员推出新的虚拟试穿技术OutfitAnyone,它是一个基于扩散模型的2D虚拟试穿框架。Outfit Anyone 通过利用双流条件扩散模型解决了这些局限性,使其能够...新技术# OutfitAnyone# 虚拟试穿2年前05110
新型视频生成框架MovieDreamer:专门用于制作长篇视频内容,比如电影浙江大学和阿里巴巴的研究人员推出新型视频生成框架MovieDreamer,专门用于制作长篇视频内容,比如电影。与传统的短时视频生成技术不同,MovieDreamer能够处理复杂的叙事结构和情节发展,同...新技术# MovieDreamer# 视频生成框架2年前09560
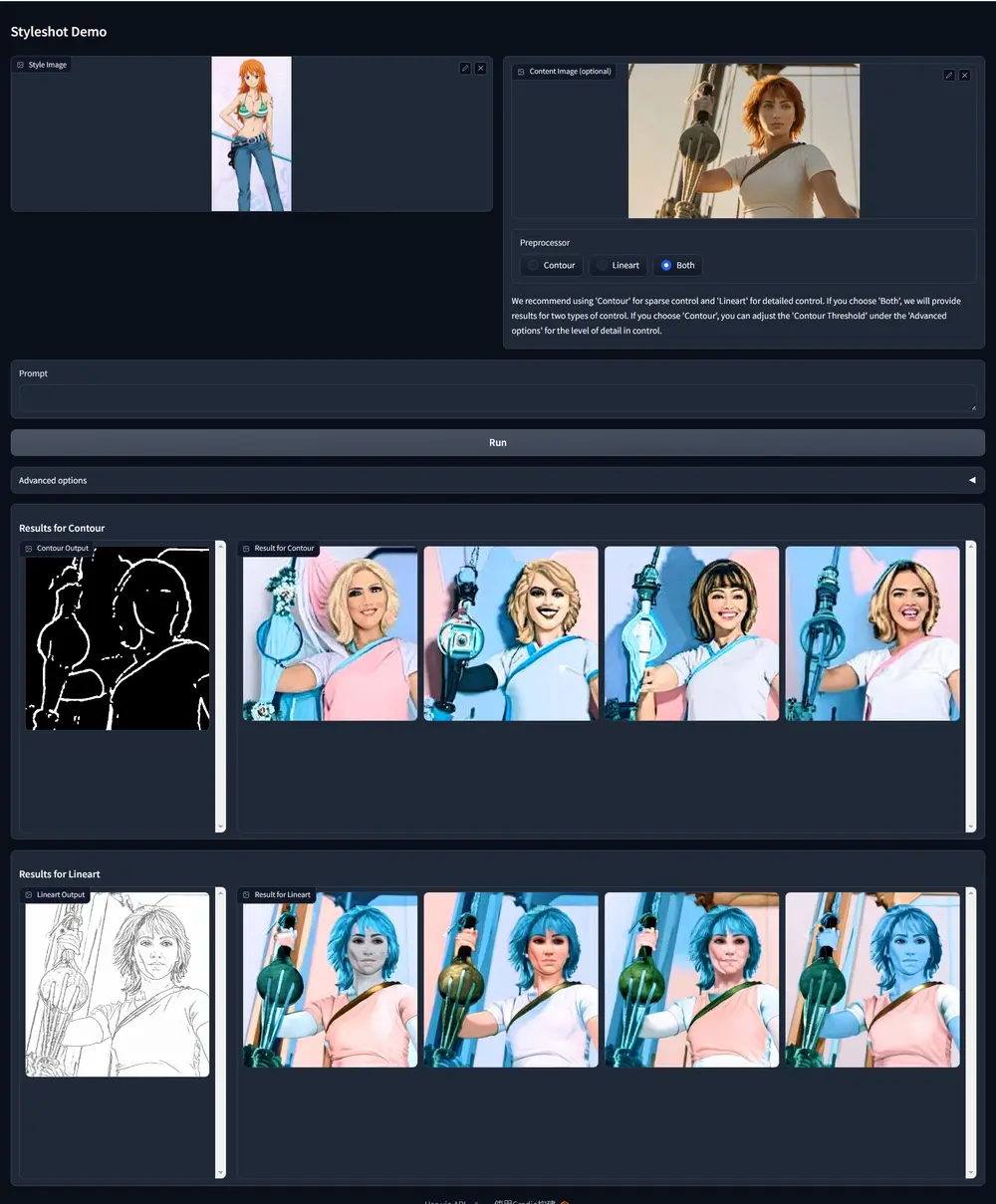
新型图像风格转换方法StyleShot:能够将任何图片转换成我们想要的几乎任何风格同济大学和上海人工智能实验室的研究人员推出新型图像风格转换方法StyleShot,StyleShot能够将任何图片转换成我们想要的几乎任何风格,比如3D、平面、抽象或者精细风格,而且转换过程中不需要在...新技术# StyleShot# 图像风格转换2年前05680
影眸科技推出新型大型3D生成模型CLAY:帮助人们将脑海中的创意轻松转化为精细的三维数字结构上海科技大学、影眸科技和华中科技大学的研究人员推出新型大型3D生成模型CLAY,它的主要任务是帮助人们将脑海中的创意轻松转化为精细的三维数字结构。就像孩子们用黏土塑造出各种形状的物体一样,CLAY能够...新技术# 3D生成模型# CLAY# 影眸科技2年前01,0950
虚拟试衣系统IMAGDressing-v1:帮助用户在线上购物时,更真实地预览服装在不同人身上的效果南京理工大学、华为、 腾讯人工智能实验室和南京大学的研究人员推出可定制的虚拟试衣系统IMAGDressing-v1,这个系统可以帮助用户在线上购物时,更真实地预览服装在不同人身上的效果。IMAGDre...新技术# IMAGDressing-v1# 虚拟穿搭# 虚拟试衣2年前08580
参照音频-视觉分割RefAVS:依据融合了多模态提示(包括音频和视觉描述)的自然语言表达,对视觉场景中的目标物进行分割中国人民大学、北京邮电大学和上海人工智能实验室的研究人员推出RefAVS(参照音频-视觉分割),依据融合了多模态提示(包括音频和视觉描述)的自然语言表达,对视觉场景中的目标物进行分割。研究团队还创建了...新技术# RefAVS# 参照音频-视觉分割2年前06430