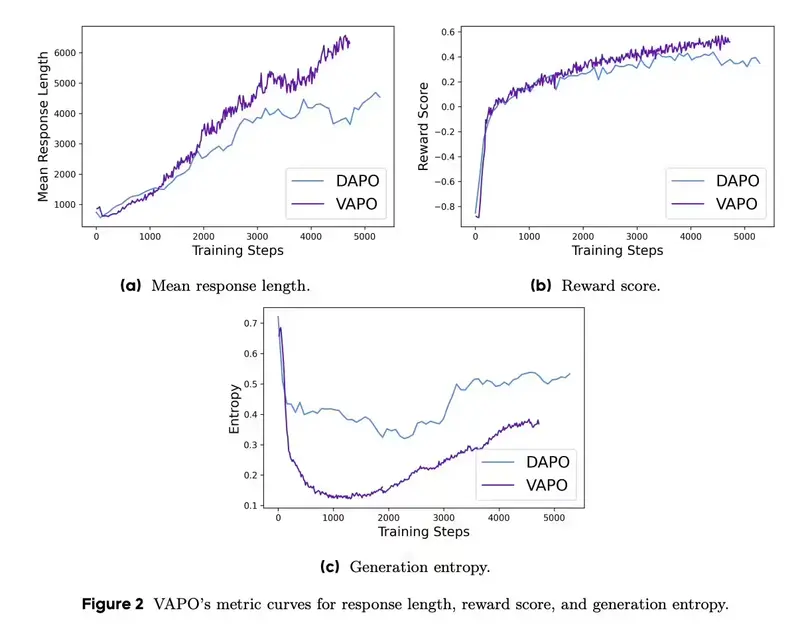
字节跳动推出VAPO框架:让大语言模型在复杂推理任务中更高效字节跳动Seed研究团队发布了一项名为 VAPO 的强化学习训练框架。这一框架专为提升大语言模型(LLM)在复杂、冗长任务中的推理能力而设计,特别是在数学推理和长链推理(Long Chain-of-T...新技术# VAPO# 大语言模型# 字节跳动11个月前05690
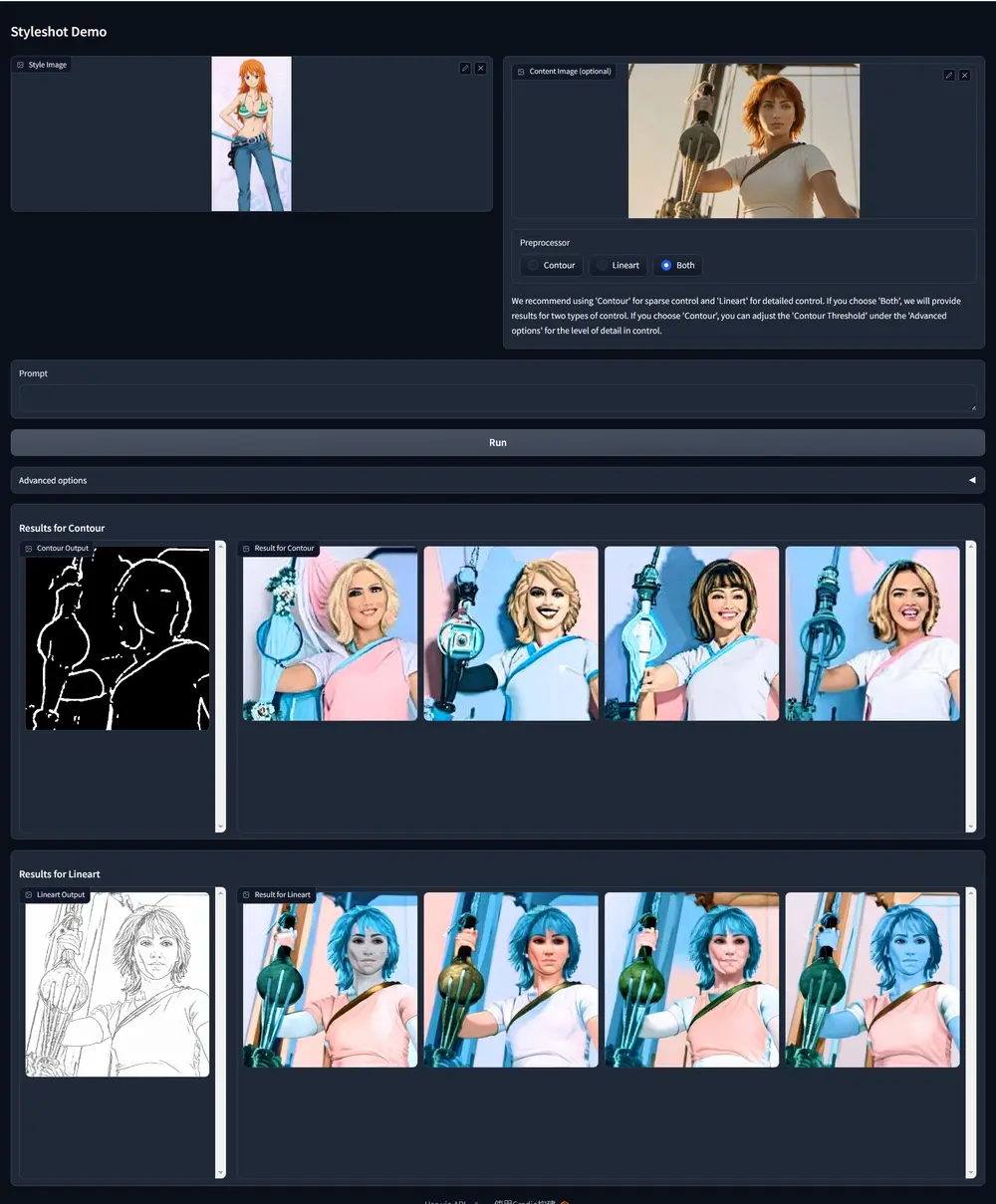
新型图像风格转换方法StyleShot:能够将任何图片转换成我们想要的几乎任何风格同济大学和上海人工智能实验室的研究人员推出新型图像风格转换方法StyleShot,StyleShot能够将任何图片转换成我们想要的几乎任何风格,比如3D、平面、抽象或者精细风格,而且转换过程中不需要在...新技术# StyleShot# 图像风格转换2年前05680
大型文本到图像提示数据集StyleBreeder:包含680万张图片及180万个提示词弗吉尼亚理工大学、苏黎世联邦理工学院、慕尼黑工业大学、谷歌和Artbreeder的研究人员推出大型文本到图像提示数据集StyleBreeder,它通过使用文本到图像的生成模型,探索和推广了艺术风格的多...新技术# StyleBreeder# 文生图提示数据集2年前05670
Scaling (Down) CLIP:从数据、架构和训练策略三个维度对CLIP进行了详细探究来自加州大学圣克鲁斯分校和Google Deepmind的研究人员发布论文探讨如何有效地缩减对比语言-图像预训练(CLIP)模型的规模,以适应计算资源有限的情况。研究团队从数据、架构和训练策略三个维度...新技术# CLIP模型2年前05670
针对图生图模型的machine unlearning(机器遗忘)框架来自美国德克萨斯大学奥斯汀分校和摩根大通全球技术应用研究中心的研究人员推出了一种针对图生图模型的machine unlearning(机器遗忘)框架,能够在不损害模型性能的前提下,有效地从模型中移除特...新技术# Machine Unlearning# 机器遗忘2年前05670
谷歌发布“多步一致性模型”(Multistep Consistency Models)谷歌发布新型生成模型“多步一致性模型”(Multistep Consistency Models),它在图像、视频和音频生成领域具有潜在的应用价值。这个模型是介于传统的“一致性模型”(Consiste...新技术# 多步一致性模型# 谷歌2年前05660
基于定制化扩散模型权重的子空间weights2weights(w2w):能够支持从单一图像中提取视觉身份,编辑模型中编码的身份,以及采样新模型来编码多样化的人物实例加州大学伯克利分校、Snap和斯坦福大学的研究人员推出weights2weights(w2w),这是一个基于定制化扩散模型权重的子空间,能够支持从单一图像中提取视觉身份,编辑模型中编码的身份,以及采样...新技术# w2w# weights2weights# 子空间2年前05650
新型3D生成模型V3D:利用视频扩散模型的能力来创建高质量的三维对象和场景来自清华和生数科技的研究推出新型3D生成模型V3D,它利用视频扩散模型的能力来创建高质量的三维对象和场景。V3D的核心思想是将连续的多视角图像视为视频,从而利用预训练的视频扩散模型来生成围绕物体的36...新技术# 3D生成模型# V3D2年前05650
JINA AI推出新型多任务对比训练方法及其模型JINA CLIP:解决现有CLIP模型在文本检索任务中性能不佳的问题JINA AI推出新型多任务对比训练方法及其模型JINA CLIP,旨在解决现有CLIP(Contrastive Language-Image Pretraining,对比语言-图像预训练)模型在文本...新技术# JINA CLIP# 对比语言-图像预训练模型2年前05640
新型视频重建模型Vidu4D:能够从单个生成的视频创建高保真的4D重建清华大学、生数科技和同济大学的研究人员推出新型视频重建模型Vidu4D,它能够从单个生成的视频创建高保真的4D重建(即连续的3D表示)。这项技术的核心是处理非刚性物体的动态变化和视频帧的失真问题,这对...新技术# Vidu4D# 视频重建模型2年前05640
北大团队推出多模态混合专家模型MoE-LLaVA来自北大的研究人员推出多模态的混合专家模型MoE-LLaVA,旨在通过一种新颖的训练策略,有效地提高模型在处理视觉和语言任务时的性能,同时保持计算成本的稳定。 GitHub Demo 论文 此模型只有...新技术# MoE-LLaVA# 北大# 多模态混合专家模型2年前05640
CleanDIFT:从大规模预训练的扩散模型中提取无噪声、与时间步无关的通用特征表示慕尼黑大学的研究人员推出一种名为CleanDIFT的新方法,用于从大规模预训练的扩散模型中提取无噪声、与时间步无关的通用特征表示。这种方法特别针对的是,以往在使用扩散模型提取特征时需要向图像添加噪声...新技术# CleanDIFT1年前05630