多服装虚拟试穿技术AnyDressing:能够根据任何组合的服装和个性化文本提示来定制角色形象字节跳动和清华大学的研究人员提出了一种名为AnyDressing的新方法,专注于解决多服装虚拟试衣任务中的挑战,这项技术特别适用于需要在多种场景和服装组合中保持服装细节的同时,还要忠实于文本提示的应用...新技术# AnyDressing# 虚拟试穿1年前03260
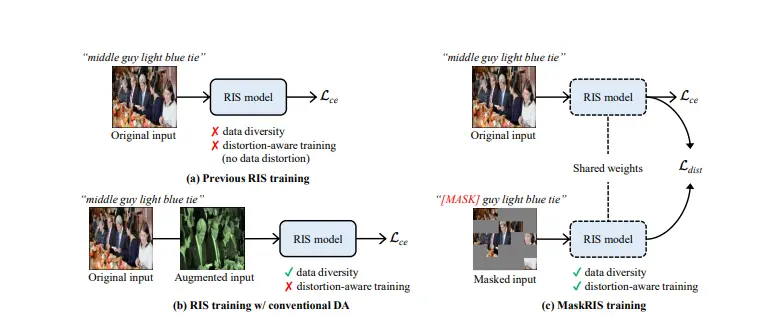
数据增强方法MaskRIS:用于改进指代表像分割任务的性能延世大学、NAVER AI LAB和韩国科学技术研究院的研究人员推出一种新的数据增强方法,名为MaskRIS(Masked Referring Image Segmentation),它用于改进指代表...新技术# MaskRIS1年前03470
Motion Prompting框架:通过动轨迹控制视频生成Google DeepMind、密歇根大学和布朗大学的研究人员推出一个名为“Motion Prompting”的框架,它用于控制视频生成中的动作轨迹。该框架通过使用运动轨迹作为条件信号,来生成具有特定...新技术# Motion Prompting# 运动轨迹控1年前03210
新型框架OmniCreator:能够进行自我监督的统一生成和编辑,涵盖图像和视频Everlyn AI、香港科技大学、佛罗里达大学和密歇根州立大学的研究人员推出新型框架OmniCreator,它能够进行自我监督的统一生成和编辑,涵盖图像和视频。OmniCreator通过利用原始的文...新技术# OmniCreator1年前02580
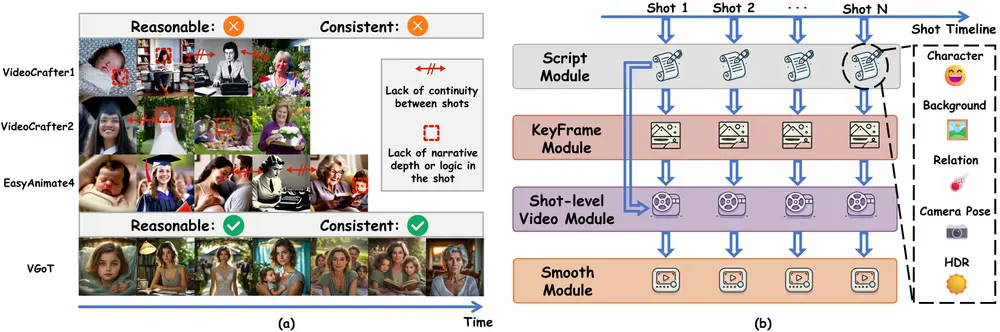
新型多镜头视频生成框架VGoT:专门针对多镜头视频生成任务设计香港科技大学、北京大学、香港大学、新加坡国立大学、中佛罗里达大学和Everlyn Al的研究人员推出新型多镜头视频生成框架VGoT,旨在解决从简短的用户输入脚本生成多镜头、电影风格视频的挑战,通过一个...新技术# VGoT# 多镜头视频1年前02910
新型框架ZipAR:用于加速自回归(AR)视觉生成模型的图像生成过程浙江大学、上海人工智能实验室和阿德莱德大学的研究人员推出新型框架ZipAR,它用于加速自回归(Auto-Regressive,AR)视觉生成模型的图像生成过程。ZipAR的核心思想是利用图像的空间局部...新技术# ZipAR# 自回归视觉生成模型1年前02800
字节推出新型视觉自回归(VAR)模型Infinity:根据语言指令生成高分辨率、逼真的图像字节跳动的研究团队提出了一种名为Infinity的新方法,该方法在位级标记预测框架下重新定义了视觉自回归(VAR)模型,能够根据语言指令生成高分辨率、逼真的图像。Infinity通过引入无限词汇标记器...新技术# Infinity# 视觉自回归模型1年前02770
高质量、人工奖励数据集HumanEdit:专为指令引导的图像编辑而设计天工AI、新加坡国立大学、北京大学和南洋理工大学的研究人员推出高质量、人工奖励数据集HumanEdit,专为指令引导的图像编辑而设计。该数据集通过开放式语言指令实现精确和多样化的图像操作,旨在解决现有...新技术# HumanEdit1年前03520
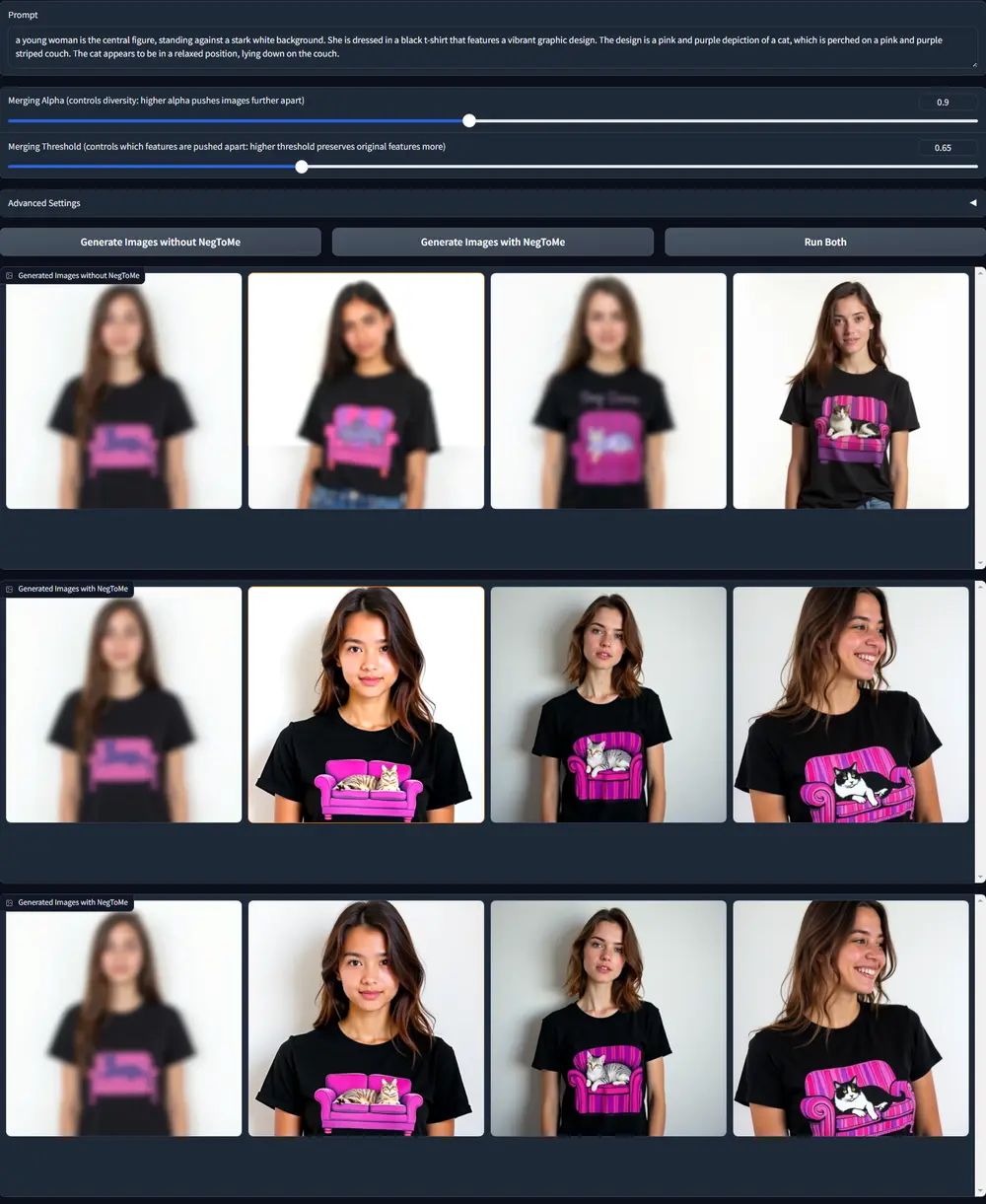
基于视觉特征的对抗性引导方法NegToMe:利用参考图像或其他批次图像的视觉特征,而非仅依赖文本提示,来更有效地排除不希望的视觉元素华盛顿大学、澳大利亚国立大学和艾伦人工智能研究所的研究人员提出了一种新的对抗性引导方法——负标记合并(Negative Token Merging, NegToMe)。该方法旨在通过直接利用参考图像或...新技术# NegToMe# 负标记合并1年前02870
实时交互式3D场景生成的创新框架WonderWorld:能够以低延迟的方式指定场景内容和布局,并实时查看创建的场景MIT和斯坦福的研究人员联合推出了WonderWorld,这是一个用于交互式3D场景生成的创新框架。它使用户能够以低延迟的方式指定场景内容和布局,并实时查看创建的场景。WonderWorld的主要目标...新技术# 3D场景# WonderWorld1年前02560
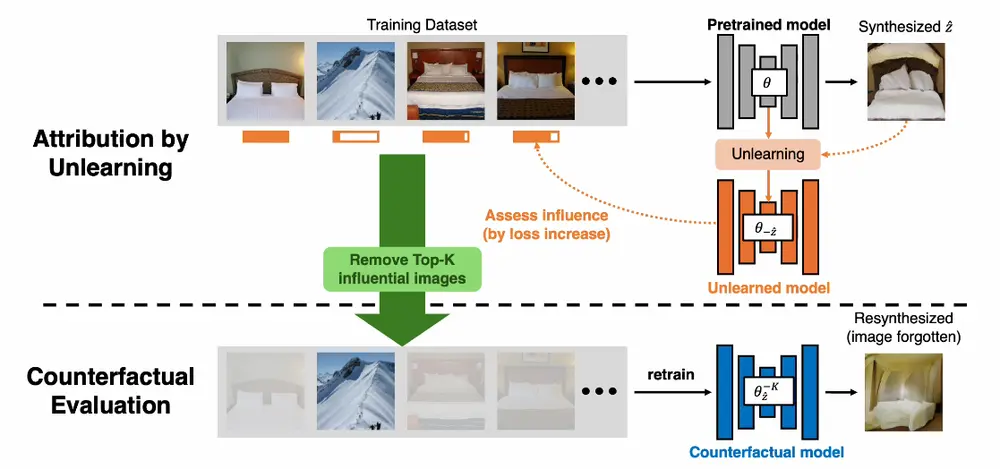
文本到图像模型的数据归因:识别在生成新图像过程中最具影响力的训练图像卡内基梅隆大学、Adobe 研究和加州大学伯克利分校的研究人员发布论文,论文的主题是关于文本到图像模型的数据归因(Data Attribution for Text-to-Image Models...新技术# 文生图模型1年前03130
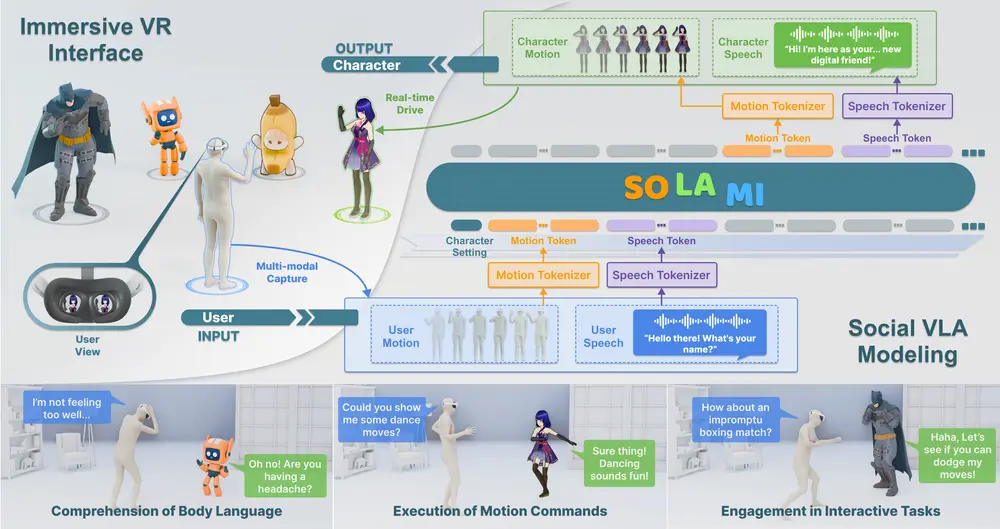
SOLAMI:为3D自主角色提供社交智能,使其能够感知、理解和与人类进行交互。人类是社会性动物,赋予3D自主角色类似的社会智能,使其能够感知、理解和与人类互动,是一个开放且基础的问题。商汤科技研究院和南洋理工大学的研究人员提出了SOLAMI,这是第一个端到端的社交视觉-语言-动...新技术# SOLAMI1年前02710