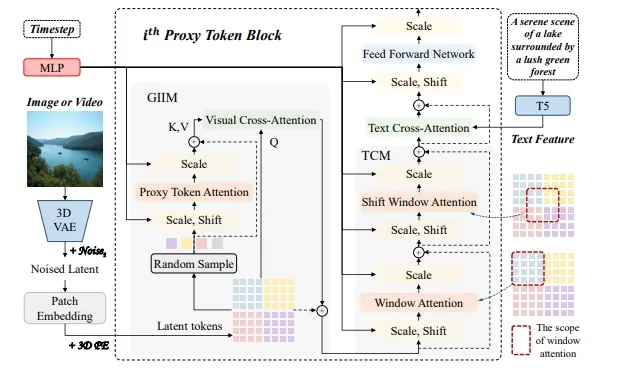
新型AI模型PT-DiT:针对文本到任意任务(如文本到图像、文本到视频等)的高效能扩散变换器中山大学 & 360人工智能研究院的研究人员推出一种新的人工智能模型PT-DiT,它是一种针对文本到任意任务(如文本到图像、文本到视频等)的高效能扩散变换器。这个模型特别关注于提高计算效率,减...新技术# PT-DiT# Qihoo-T2X2年前06150
子对象级图像标记化:用于计算机视觉模型的图像处理来自香港科技大学与小冰AI的研究人员推出名为“子对象级图像标记化”(subobject-level image tokenization)的新方法,这是一种用于计算机视觉模型的图像处理技术。这种方法受...新技术# 子对象级图像标记化2年前06150
diffusion-e2e-ft:通过微调图像条件扩散模型来简化和提高单目深度估计的效率亚琛工业大学和埃因霍温理工大学的研究人员推出diffusion-e2e-ft,通过微调图像条件扩散模型来简化和提高单目深度估计的效率。单目深度估计是指仅使用一张图片来预测场景中每个像素的深度信息。这项...新技术# diffusion-e2e-ft# 单目深度估计2年前06130
3D场景编辑方法ReplaceAnything3D(RAM3D):通过文本提示在3D场景中替换特定的物体来自Meta、伦敦大学的研究人员推出一种基于文本引导的3D场景编辑方法ReplaceAnything3D(RAM3D),它允许用户通过文本提示在3D场景中替换特定的物体。这种方法结合了预训练的文本引导...新技术# 3D场景编辑# RAM3D# ReplaceAnything3D2年前06130
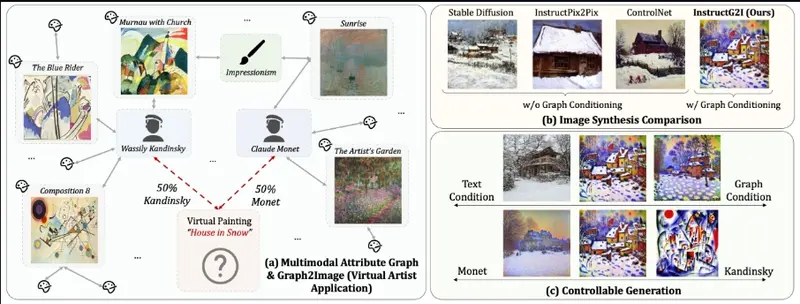
图上下文感知扩散模型InstructG2I:根据多模态属性图(MMAGs)生成图像多模态属性图(MMAGs)作为一种强大的数据结构,能够以图的形式表示实体之间的关系,节点中包含图像和文本信息。尽管 MMAGs 在图像生成中具有多功能性,但它们受到的关注相对较少。这是因为 MMAGs...新技术# InstructG2I# 多模态属性图1年前06120
新型图像到视频扩散模型TRIP:专注于将静态图像转换为动态视频来自中国科学技术大学和HiDream.ai的研究人员推出新型图像到视频扩散模型TRIP(Temporal Residual Learning with Image noise Prior),它专注于将...新技术# TRIP# 图生视频2年前06120
AI音乐模型Stable Audio:结合文本提示和时间控制长音频生成Stability AI发布AI音乐模型Stable Audio,它专注于从文本提示生成高质量、可变长度的立体声音乐和音效。这个模型特别适用于需要快速生成长形式音频内容的场景,如音乐制作、游戏音效设计...新技术# AI音乐# Stability AI# Stable Audio2年前06120
字节跳动推出新颖视频合成方法Boximator:可控制画面范围及运动方向字节跳动发布了一种新颖视频合成方法Boximator,主要用于生成具有丰富和精细运动控制的高质量视频。Boximator引入了两种约束类型:硬边框(hard box)和软边框(soft box),允许...新技术# Boximator# 字节跳动# 视频合成2年前06120
混合数据专家MoDE:通过聚类方法来提升对比语言-图像预训练(CLIP)的性能来自Meta、哥伦比亚大学、纽约大学和华盛顿大学的研究人员推出机器学习系统MoDE(Mixture of Data Experts,混合数据专家),它通过聚类方法来提升对比语言-图像预训练(CLIP...新技术# CLIP# MoDE# 混合数据专家2年前06110
文本编码器Glyph-ByT5:为提高视觉文本渲染的准确性而设计来自微软亚洲研究院、清华大学、北京大学和澳大利亚国立大学的研究团队推出文本编码器Glyph-ByT5,它是为了提高视觉文本渲染的准确性而设计的。Glyph-ByT5通过微调一个字符感知的ByT5编码器...新技术# Glyph-ByT5# 文本编码器2年前06100
TTT-Video:通过引入 Test-Time Training(TTT)层,成功让DiT 模型能够从文本故事板生成长达一分钟的视频英伟达联合斯坦福大学、加州大学圣地亚哥分校、加州大学伯克利分校和德克萨斯大学奥斯汀分校的研究人员,通过引入 Test-Time Training(TTT)层,成功让预训练的 DiT 模型能够从文本故事...新技术# CogVideoX-5B# DiT 模型# TTT-Video11个月前06080
条件对比对齐CCA:提升自回归(AR)视觉生成模型的样本质量无分类器引导(CFG)是提高视觉生成模型样本质量的关键技术。然而,在自回归(AR)多模态生成中,CFG 在语言和视觉内容之间引入了设计不一致性,这与统一不同模态的视觉 AR 设计理念相矛盾。受语言模型...新技术# CCA# 条件对比对齐# 视觉生成模型1年前06080