图像超分辨率技术SeeSR:保持生成的高分辨率图像的语义准确性来自香港理工大学、OPPO、字节跳动的研究人员推出图像超分辨率技术SeeSR,它利用语义提示来增强预训练的文本到图像(T2I)扩散模型在处理现实世界图像超分辨率问题时的性能。这种方法特别关注于在图像质...新技术# SeeSR# 图像超分辨率2年前07160
基于两阶段高斯溅射的3D模型DreamPolisher:基于文本描述生成三维(3D)对象来自牛津大学的研究人员推出DreamPolisher,它是一种基于文本描述生成三维(3D)对象的方法。这是一种基于两阶段高斯溅射的方法,该方法强制各视图之间的几何一致性。首先,通过几何优化对粗略的3D...新技术# 3D模型# DreamPolisher2年前07150
单样本文生图模型的微调方法:解决泛化性和真实性问题来自腾讯的研究人员提出了一种面向对象的单样本文生图模型的微调方法Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with P...新技术# Lora# 微调# 文生图2年前07140
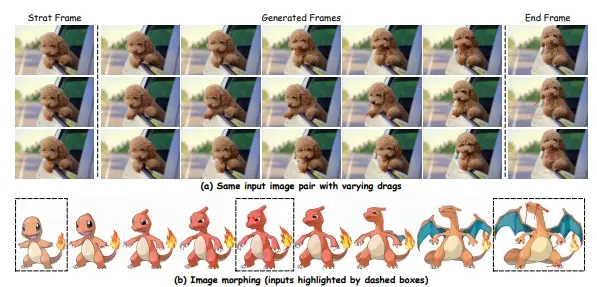
交互式帧插值工具Framer:根据用户的创造力生成两个图像之间平滑过渡的帧帧插值是生成两个图像之间平滑过渡帧的技术,广泛应用于视频处理、动画制作和内容创作等领域。传统的帧插值方法通常依赖于固定的算法,难以实现对局部运动的精细控制。浙江大学和蚂蚁集团的研究人员提出了Frame...新技术# Framer# 帧插值1年前07110
轨迹条件文本到4D生成方法TC4D:根据文本描述和一条轨迹生成动态的三维场景来自多伦多大学、Vector Institute、Snap、香港中文大学、斯坦福大学、香港大学、密歇根大学和 Google DeepMind的研究团队推出轨迹条件文本到4D生成方法TC4D(Traje...新技术# 4D# TC4D# 三维场景2年前07110
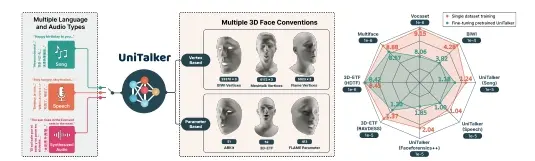
用于3D面部动画的统一模型UniTalker:能够根据输入的音频生成逼真的面部动作商汤科技推出UniTalker,它是一个用于3D面部动画的统一模型,能够根据输入的音频生成逼真的面部动作。这项技术在动画制作、虚拟现实、游戏开发等领域具有广泛的应用前景。UniTalker是一种统一的...新技术# UniTalker2年前07100
运动引导扩散模型Pix2Gif:用于图像到GIF(视频)的生成微软印度研究院和微软雷蒙德研究院的研究人员推出运动引导扩散模型Pix2Gif,该模型可用于图像到GIF(视频)的生成。 项目主页 GitHub Demo 他们采取了与众不同的方法,将任务定位为受文本和...新技术# GIF# Pix2Gif2年前07090
文本到图像合成框架PIXART-δ:0.5秒内生成1024×1024像素的图像来自华为诺亚方舟实验室、大连理工大学、香港大学、香港科技大学的研究人员推出了文本到图像合成框架PIXART-δ,这是去年发布的PIXART-α模型的一个升级版本。PIXART-α以其高效的训练过程和生...新技术# AI绘画# PIXART-α# PIXART-δ2年前07090
T-Stitch:加速预训练扩散模型采样过程来自莫纳什大学、英伟达、威斯康星大学麦迪逊分校、加州理工学院的研究人员推出T-Stitch,它是一种用于加速预训练扩散模型采样过程的方法。 项目主页 GitHub 扩散模型是一类在图像生成领域表现出色...新技术# T-Stitch# 扩散模型# 采样2年前07080
人像视频生成框架V-Express:平衡不同控制信号(如文本、音频、参考图像、姿态、深度图等)的强弱,以便在生成视频中实现更协调和有效的控制南京大学和腾讯人工智能实验室的研究人员推出人像视频生成框架V-Express,它用于生成高质量的人像视频。这项技术特别关注于如何平衡不同控制信号(如文本、音频、参考图像、姿态、深度图等)的强弱,以便在...新技术# V-Express# 人像视频2年前07050
3D重建和生成模型GRM:从稀疏视角的图像中快速重建出3D模型来自斯坦福大学、香港科技大学、上海人工智能实验室、 浙江大学和蚂蚁集团的研究团队推出新型大规模3D重建和生成模型GRM(Gaussian Reconstruction Model),GRM是一种基于t...新技术# 3D模型# GRM2年前07050
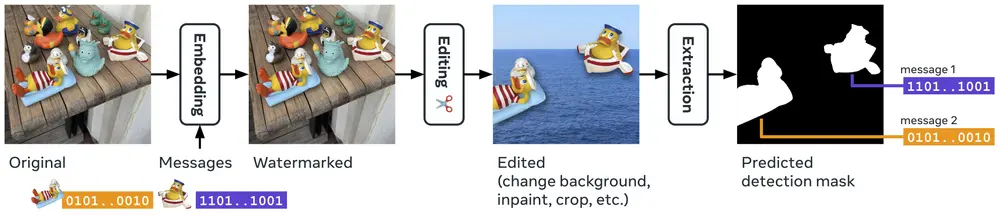
Meta推出局部图像水印的深度学习模型WAM图像水印技术在保护数字内容的版权和完整性方面发挥着重要作用。然而,传统的图像水印方法并未针对处理小面积水印区域进行优化,这限制了其在实际应用中的使用,例如图像的部分可能来自不同来源或已被编辑。Meta...新技术# WAM# 图像水印1年前07040