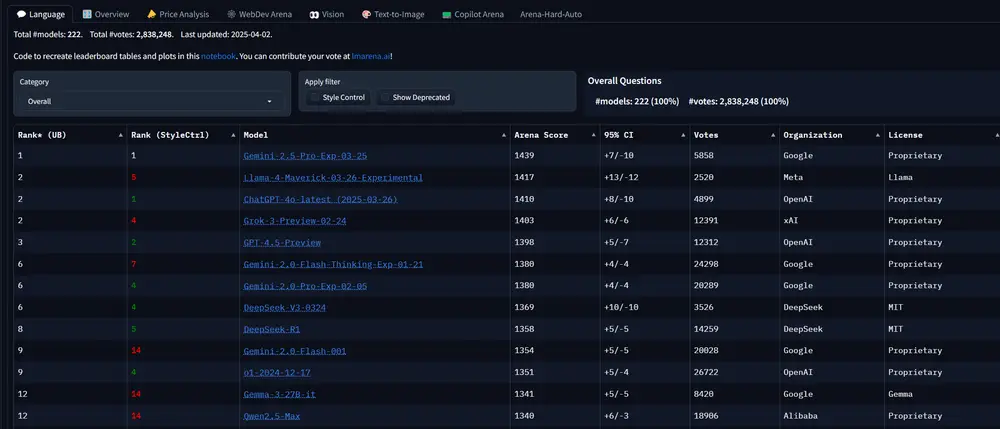
Meta原版Llama-4-Maverick模型在基准测试中大翻车本周,Meta因使用未经发布的实验版Llama 4 Maverick模型在众包基准测试平台LM Arena上获得高分而引发争议。这一事件不仅促使LM Arena的维护者公开道歉并调整政策,还让未经修改...早报# Llama 4 Maverick# Meta12个月前02530
Meta回应Llama 4基准作弊指控,但质疑的声音依旧存在上周,Meta正式推出了其大语言模型(LLM)的最新版本——Llama 4系列,包括Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth。这三款模型是Meta...早报# Llama 4# LMArena# Meta12个月前02960
Meta新旗舰 AI 模型 Llama 4 Maverick 测试成绩遭质疑,被指测试版与开源版并不一致Meta上周六发布了其新的旗舰AI模型之一——Llama 4 Maverick。在备受瞩目的LM Arena测试中,Maverick取得了第二名的成绩。这一测试由人类评分者对模型输出进行比较,并选择他...早报# Llama 4 Maverick# Meta12个月前02310
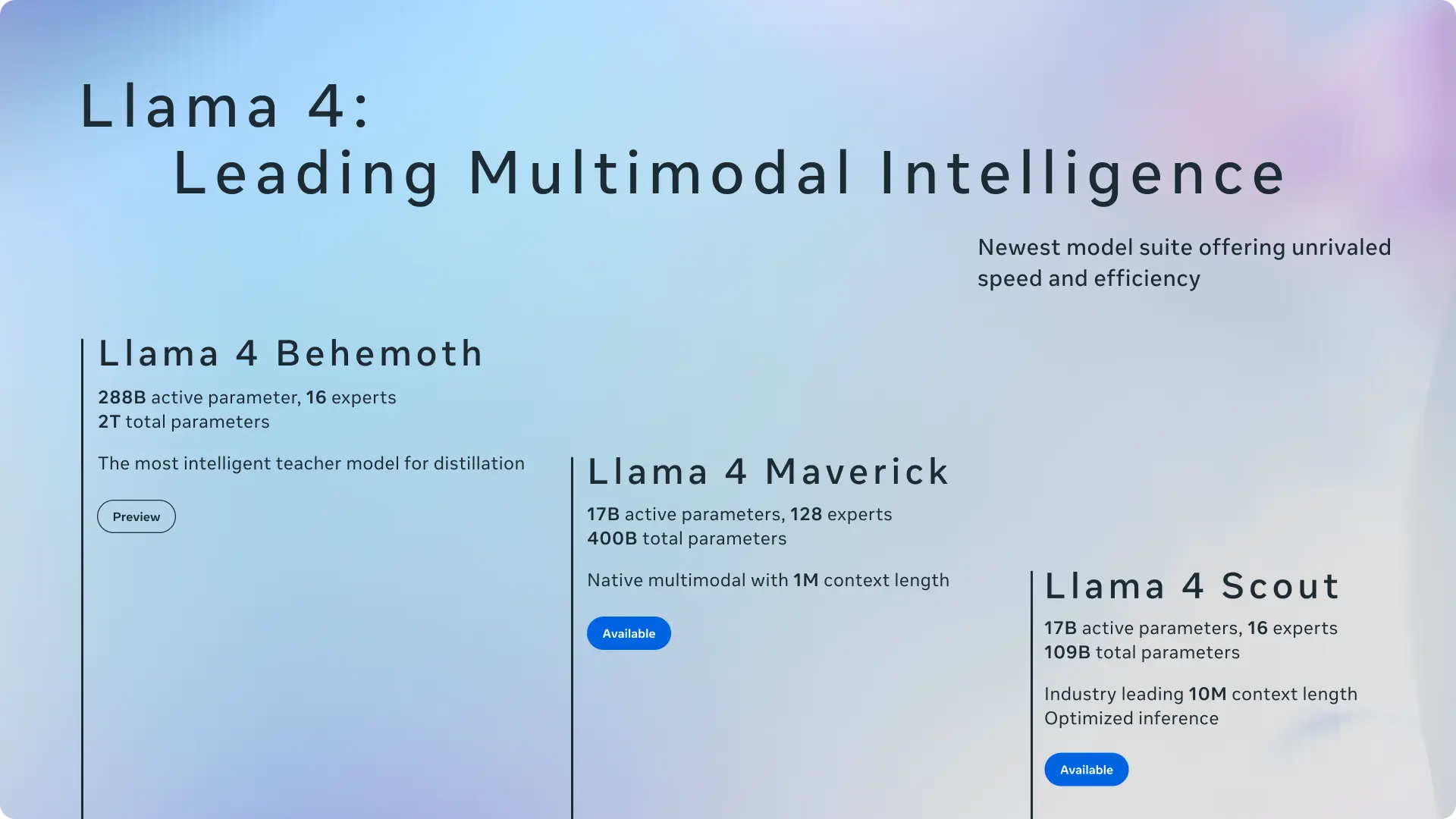
Meta发布Llama 4系列多模态模型:首次采用MoE架构,最高1000万上下文长度2025年4月6日星期日,Meta正式推出了其最新的AI模型系列——Llama 4。这款新模型不仅支持网络版Meta AI助手,还为WhatsApp、Messenger和Instagram等平台提供了...大语言模型# Llama 4# Meta# MoE架构1年前05890
Meta大语言模型Llama 4 将于本月发布,但数学处理及推理能力尚待改进据 The Information 报道,Meta 的下一代大语言模型 Llama 4 正在紧锣密鼓地开发中,但根据内部基准测试的结果来看,其表现并不尽如人意。尤其是在数学处理能力和推理能力方面,Ll...早报# Llama 4# Meta1年前02310
韩国初创公司FuriosaAI拒绝Meta收购要约,坚持自主发展AI芯片据报道,韩国初创公司FuriosaAI拒绝了Meta提出的8亿美元收购要约,选择继续专注于自主开发和生产其AI芯片。这一决定背后,是双方在收购后的商业策略和组织结构上存在分歧。 谈判破裂背后的原因 M...早报# AI芯片# FuriosaAI# Meta1年前02330
路透社报道,Meta 首款 RISC-V AI 训练芯片启动测试,推动硬件独立性摆脱对英伟达的依赖据路透社报道,Meta 正在测试其首款基于 RISC-V 架构的内部设计 AI 训练芯片,这可能是业界首款 RISC-V AI 训练加速器。这一举措标志着 Meta 在降低对英伟达 GPU 依赖的道路...早报# AI芯片# Meta# RISC-V1年前02660
美国联邦法官允许对 Meta 的 AI 版权诉讼继续推进近日,美国联邦法官 Vince Chhabria 做出裁决,允许针对 Meta 的 AI 相关版权诉讼继续推进,尽管他驳回了诉讼的一部分。这一案件名为“Kadrey 诉 Meta”,由包括 Richa...早报# Meta# 版权1年前02170
Meta 的 Llama 4 模型可能升级语音功能根据《金融时报》的报道,Meta 计划在即将发布的 Llama 4 AI 模型中引入显著改进的语音功能。作为 Llama 系列模型的新旗舰产品,Llama 4 预计将在“几周内”发布,并特别强调了对用...早报# Llama 4# Meta# 语音1年前03050
Meta 计划推出独立 AI 聊天机器人应用程序,全面进军 AI 领域据报道,Meta 正计划推出一款独立的 AI 助手应用程序——Meta AI,以在日益激烈的 AI 市场中与 OpenAI 的 ChatGPT、Google 的 Gemini 和 Microsoft ...早报# AI 聊天机器人# LlamaCon# Meta1年前02610
Meta 首届 LlamaCon AI 大会即将来袭,Llama 4 或成焦点Meta 正式宣布将于 4 月 29 日举办首届 LlamaCon 开发者大会,专注于生成式 AI 与 Llama 模型的最新进展。与此同时,Meta 的年度 Connect 大会则定于 9 月 17...早报# Llama 4# LlamaCon# Meta1年前03150
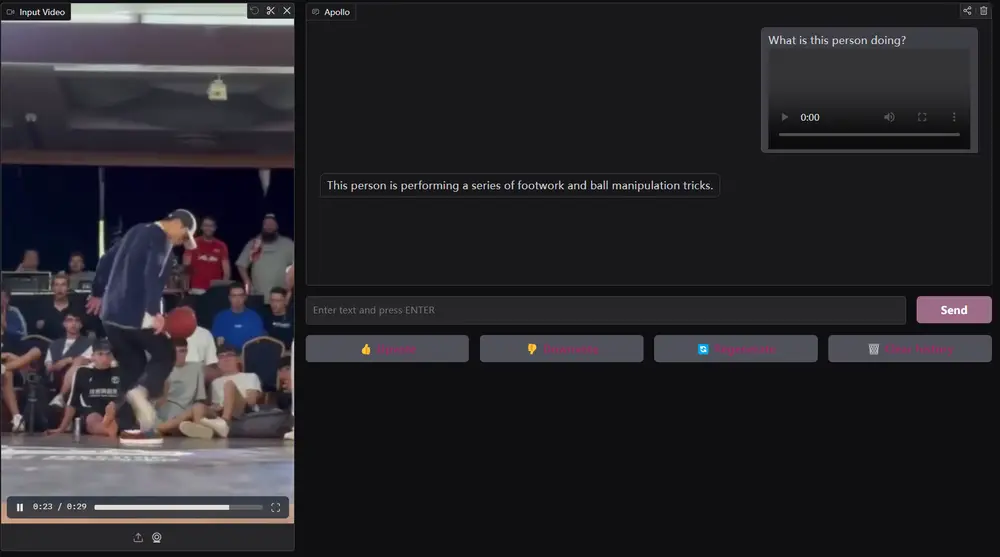
Meta推出多模态模型Apollo:擅长处理长视频,能够在长达一小时的视频中保持高效的理解能力尽管视频感知能力已经迅速集成到大型多模态模型(LMMs)中,但其驱动视频理解的基本机制仍未被充分理解。这导致了许多设计决策缺乏适当的理由或分析,尤其是在训练和评估这些模型时,高昂的计算成本和有限的开放...多模态模型# Apollo# Meta# 多模态模型1年前03100