上周,Meta正式推出了其大语言模型(LLM)的最新版本——Llama 4系列,包括Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth。这三款模型是Meta先进多模态AI系统的重要组成部分,旨在满足不同场景下的应用需求。
Llama 4系列的核心特点
- Llama 4 Scout:专为在单个Nvidia H100 GPU上运行而设计,提供1000万个令牌的上下文窗口,适合资源受限但需要高效处理的场景。
- Llama 4 Maverick:比Scout更为强大,据称在编码和推理任务上与OpenAI的GPT-4o和DeepSeek-V3性能相当,同时使用的活跃参数更少,兼顾了性能与效率。
- Llama 4 Behemoth:作为系列中最大的模型,拥有2880亿个活跃参数,总计2万亿个参数。Meta声称,Behemoth在STEM基准测试中表现优异,超过了GPT-4.5和Claude Sonnet 3.7等竞争对手的模型。
争议的起源
然而,就在Llama 4系列发布后不久,网络上出现了一些关于Meta在基准测试中作弊的传言。这些传言声称,Meta在测试集上训练了Maverick和Llama 4,以提升其在基准测试中的排名。据称,这一说法源自一位匿名的Meta内部人士在一家中文网站上的发帖。该人士在帖子中提到,经过反复训练,内部模型的性能仍未达到开源SOTA(State of the Art)水平,甚至远远落后。公司领导层建议在后训练过程中混入各种基准测试集,以生成一个在多个指标上“看起来还行”的结果。如果到4月底的设定截止日期仍未达标,他们可能会停止进一步投资。
此外,该匿名人士还表示,由于无法接受这种做法,他已提交辞职请求,并明确要求自己的名字不被列入Llama 4的技术报告中。他还提到,Meta的AI副总裁也因同样原因辞职。这一传言迅速在X(Twitter)和Reddit上传播开来,引发了大量讨论。
Meta的回应
针对这些指控,Meta生成式AI副总裁Ahmad Al-Dahle迅速做出回应。他坚决否认了这些指控,称其“完全不是真的”,并表示Meta“绝不会这样做”。Al-Dahle强调,Meta一直致力于推动AI技术的发展,并且严格遵循行业标准和道德规范。
质疑的声音
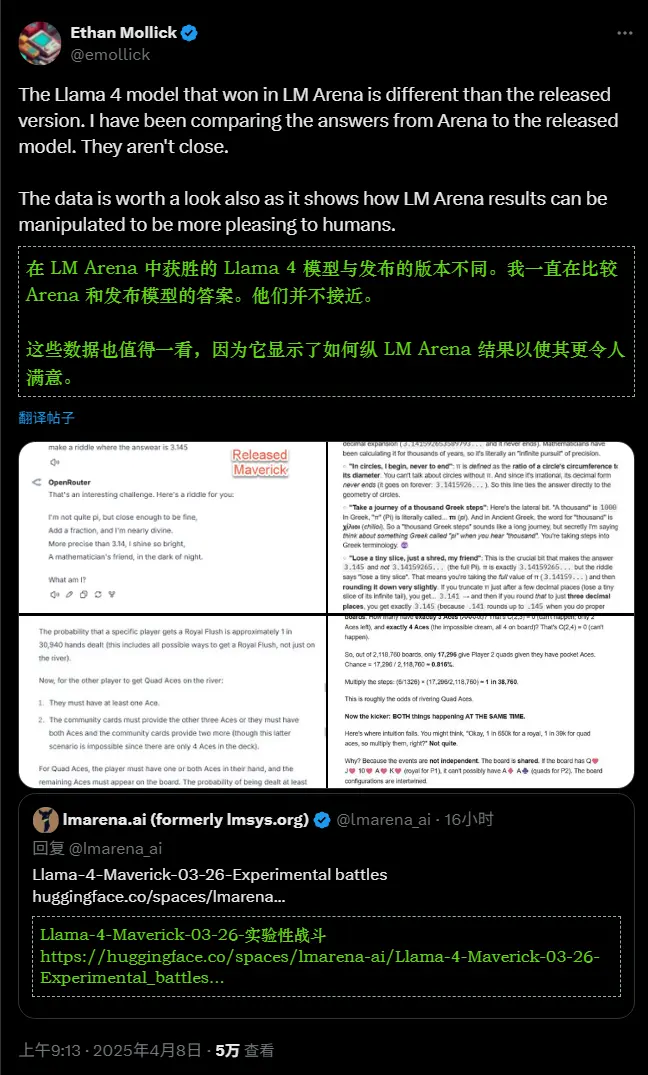
尽管Meta的回应态度坚决,但外界的质疑并未完全消除。一方面,X上有多篇报告指出,开发者可用的Maverick公开版本与Meta在LMArena上展示的版本行为不同。此外,Meta自己也承认,LMArena上托管的Maverick是一个“实验性聊天版本”,其ELO分数为1417,这一版本的表现与公开版本存在差异。
Meta的进一步解释
Al-Dahle对不同服务报告的“质量参差不齐”现象进行了解释。他表示,由于这些模型一准备好就立即发布,所有公共实现需要几天时间才能“调整到位”。他还强调,Meta在模型开发过程中始终注重透明度,并将继续与社区保持沟通,以确保用户能够获得准确的信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











