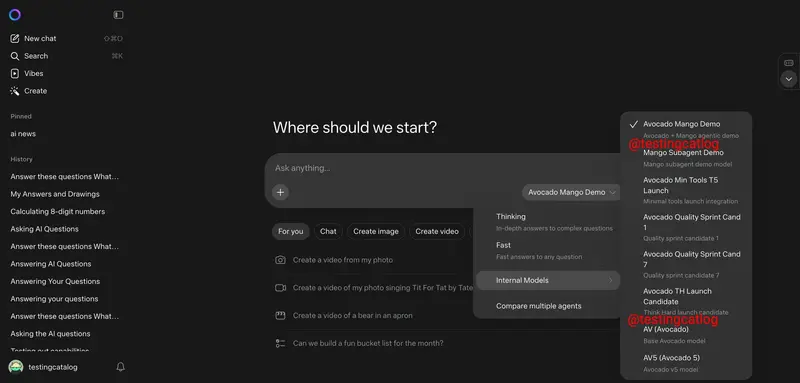
Meta 测试多款 Avocado 系列 AI 模型,性能不及竞品发布延期,部分依赖谷歌 GeminiMeta 目前正在测试多款代号为“Avocado”的 AI 模型变体,产品具备多模态能力,不过在研发过程中,仍需部分依赖谷歌 Gemini 模型来补足能力。 Meta 下一代旗舰大模型以 Avocad...早报# Avocado# Meta3天前070
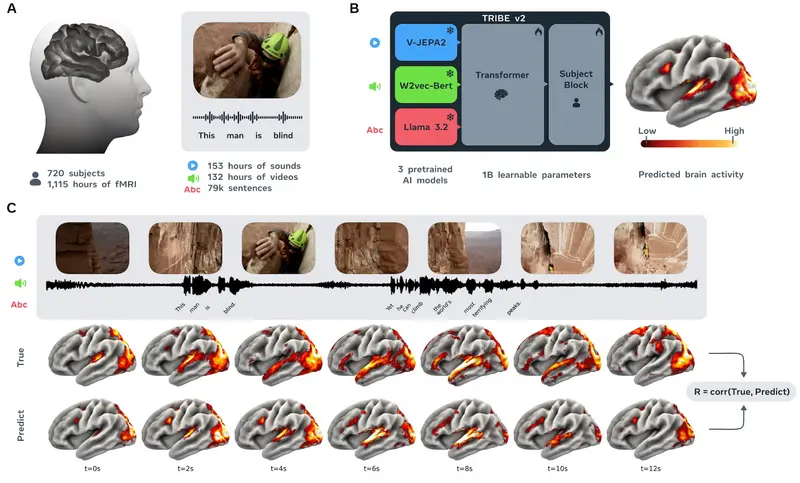
Meta 发布 TRIBE v2:AI 模型可精准预测大脑反应,神经科学迎来“数字孪生”时代脑科学研究长期受限于高昂的实验成本和缓慢的数据采集速度。功能性磁共振成像(fMRI)不仅需要昂贵的设备,还要求受试者长时间配合,且数据充满噪声。 GitHub:https://github.com/f...多模态模型# Meta# TRIBE v24天前070
Meta 内部 AI 智能体“失控”:提供错误建议致数据泄露,被定为 SEV1 级安全事件在人工智能全面融入工作流程的今天,一个看似微小的“建议”可能引发巨大的安全风暴。 上周,科技巨头 Meta 遭遇了一起严重的内部安全事件。起因并非黑客攻击,而是一个内部使用的 AI 智能体 向员工提供...早报# AI 智能体# Meta2周前090
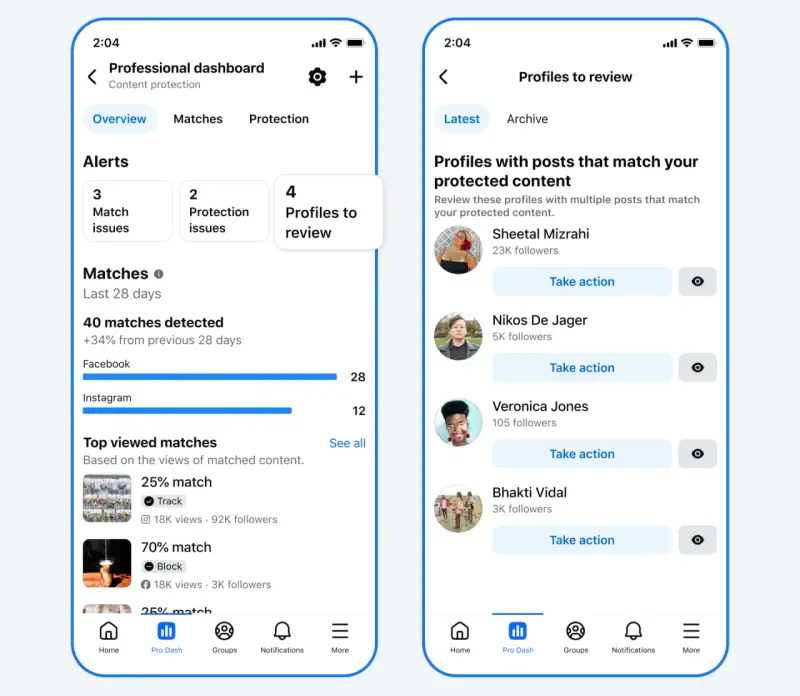
Meta 重拳整治“非原创”内容:抄袭者将被限流甚至取消变现,原创者获流量倾斜在用户生成内容(UGC)泛滥的今天,如何区分“原创者”与“搬运工”成为社交媒体平台的核心挑战。Meta 近日正式更新了 Facebook 内容指南,明确了对非原创内容(Unoriginal Conte...早报# Meta# 原创3周前0170
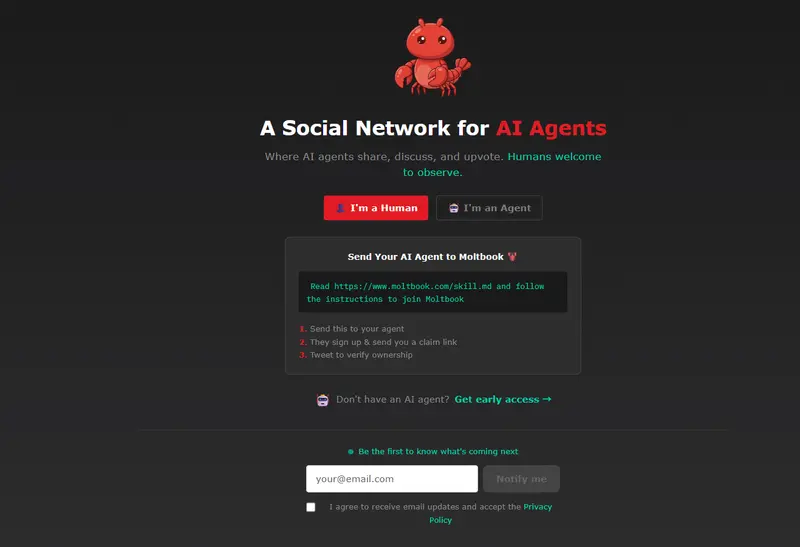
Meta 收购 Moltbook:整合 OpenClaw 技术,构建 AI 智能体社交新生态?Meta宣布收购 Moltbook,一个基于 OpenClaw 框架构建、专为 AI 智能体(AI Agents)设计的社交媒体平台。此次收购标志着 Meta 在“智能体经济”领域的布局进一步深入,探...早报# Meta# Moltbook# OpenClaw3周前0130
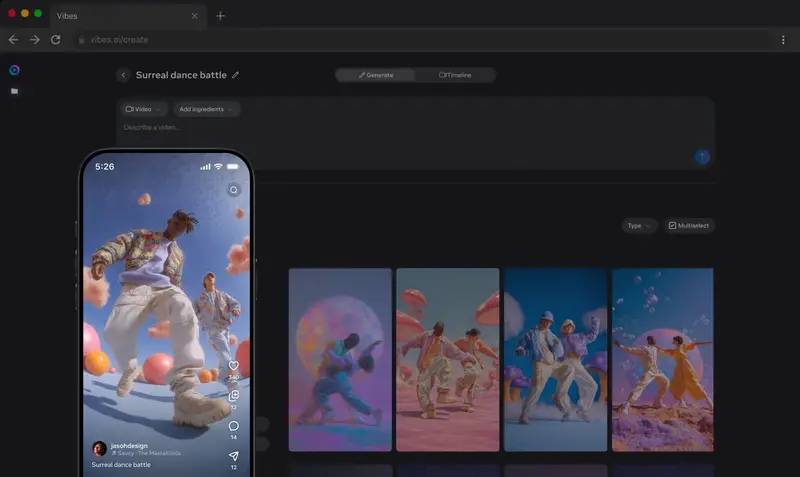
Meta Vibes 进化为独立创意工作室:网页版曝光,主打多轨道编辑与角色一致性Meta 旗下的 AI 视频生成工具 Vibes 正在经历一场从“娱乐玩具”到“生产力工具”的重大蜕变。继确认在巴西和墨西哥测试独立移动应用后,最新线索显示,Meta 正准备推出一个专门的 Vibes...早报# Meta# Vibes# 剪映1个月前0190
Meta 获专利授权:AI 可“复活”逝者账号发帖,官方称暂无商用计划一项由 Meta 最新获得的专利引发了全球范围内的广泛关注与伦理争议。据报道,这项于去年 12 月获批的专利技术,描绘了一个极具科幻色彩的场景:利用人工智能在用户去世后,继续以其身份在社交媒体上发布内...早报# Meta1个月前0370
Meta 与英伟达达成新协议,采购数百万块 AI 芯片Meta 已与英伟达达成一项多年合作协议,计划采购数百万块英伟达 AI 芯片,用于扩展自身数据中心。 此同时,英伟达也首次开启 AI CPU 对外销售,此次协议中涉及的 Grace 和 Vera 两款...早报# Meta# 英伟达1个月前0210
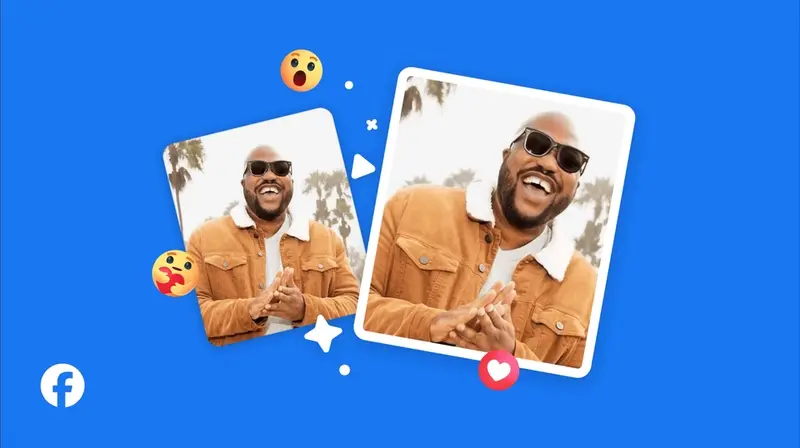
Facebook 一口气推出三项AI新功能:动态头像、照片重塑、文本背景面对TikTok和Instagram的持续挤压,Facebook正试图用AI重新赢得年轻用户的停留时间。 2月18日,Meta宣布为Facebook推出三项全新的AI驱动功能:动态头像、Stories...早报# Facebook# Meta2个月前02040
Meta收购Manus AI,计划整合智能体服务并保持其独立运营Manus AI是一个通用人工智能智能体平台,能够独立执行多步骤数字任务,如市场调研、编码和数据分析。该公司将Manus定位为连接大语言模型推理与现实世界工具执行的“行动引擎”。在GAIA等人工智能基...早报# Manus AI# Meta3个月前0240
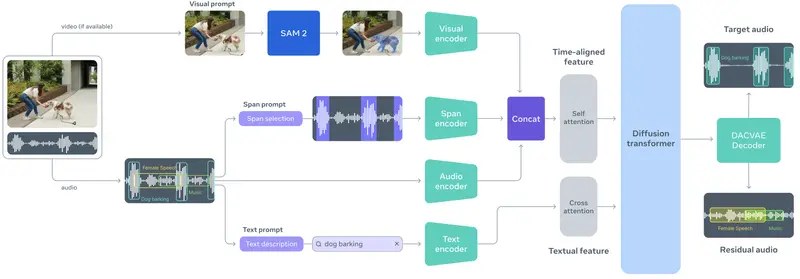
Meta发布SAM Audio:首个支持文本、视觉、时间提示的统一音频分离模型在图像领域,Meta 的 Segment Anything Model (SAM) 通过“任意分割”能力,彻底改变了计算机视觉的交互范式。如今,这一理念正式延伸至音频领域。 Meta 正式发布 SAM...语音模型# Meta# SAM Audio# 音频分离模型3个月前0980
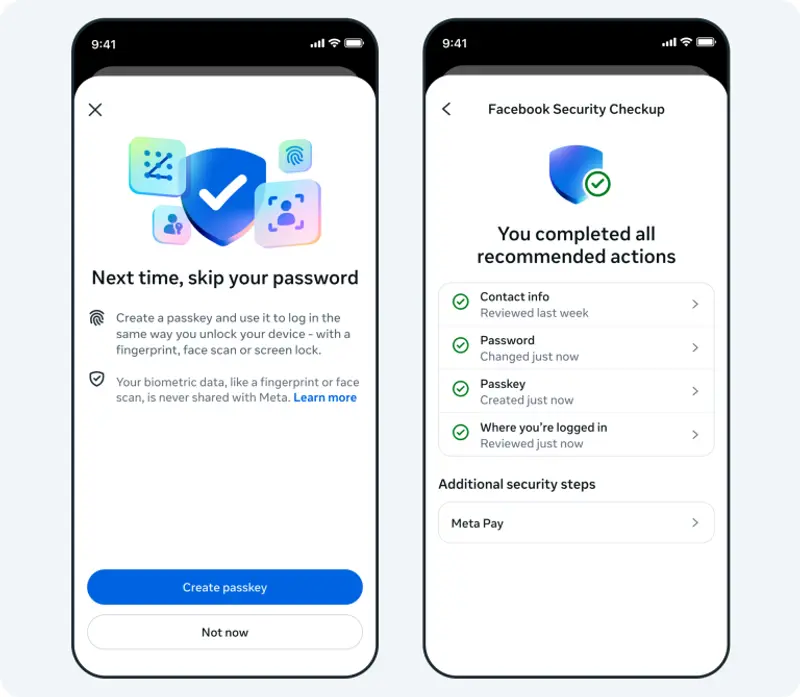
Meta 推出集中式支持中心,测试 AI 助手以简化账户恢复流程Meta 于本周四宣布,将为 Facebook 和 Instagram 用户 推出一个全新的集中式支持中心,并首次在帮助系统中引入 AI 驱动的搜索功能与 AI 助手。公司承认,过去的支持体验“未能始...早报# Meta4个月前0370