Meta上周六发布了其新的旗舰AI模型之一——Llama 4 Maverick。在备受瞩目的LM Arena测试中,Maverick取得了第二名的成绩。这一测试由人类评分者对模型输出进行比较,并选择他们更偏好的结果。然而,事情似乎并不像表面上看起来那么简单。
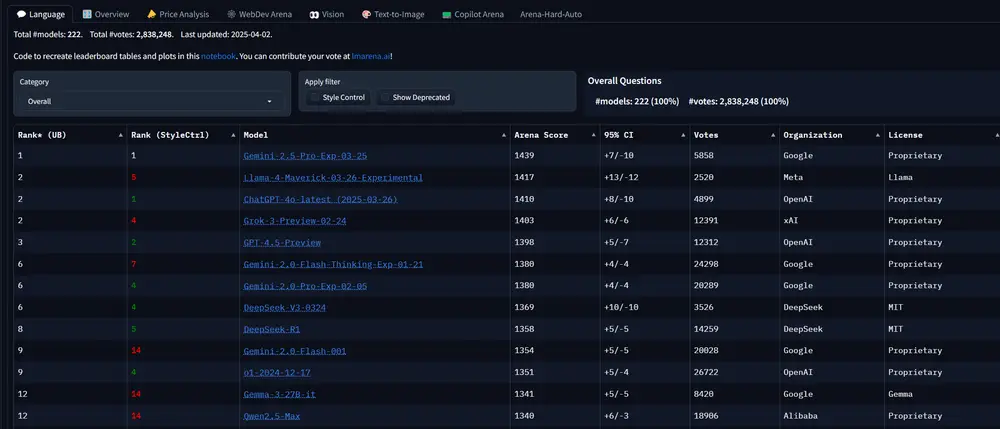
据几位AI研究人员在X平台上指出,Meta部署到LM Arena的Maverick版本与广泛提供给开发者的版本并不一致。Meta在其公告中提到,LM Arena上的Maverick是一个“实验聊天版本”。而官方Llama网站上的一张图表更是披露,Meta在LM Arena测试中使用的是“为对话优化过的Llama 4 Maverick”。
这种版本差异引发了诸多疑问。正如我们之前所讨论的,LM Arena从来都不是衡量AI模型性能的最可靠标准。然而,AI公司通常不会公开承认为了在LM Arena上获得更好分数而对模型进行定制或微调。这种做法虽然在技术上无可厚非,但从实际应用的角度来看,却可能带来一系列问题。
当一个模型被调整至某个基准测试的最优状态,并保留该版本,随后再发布该模型的“普通”变体时,开发者将难以准确预测模型在特定场景中的表现。这不仅增加了开发者的使用成本,还可能具有误导性。理想情况下,尽管基准测试存在诸多不足,但它至少应该能够提供单一模型在各种任务中的优势和劣势的快照。
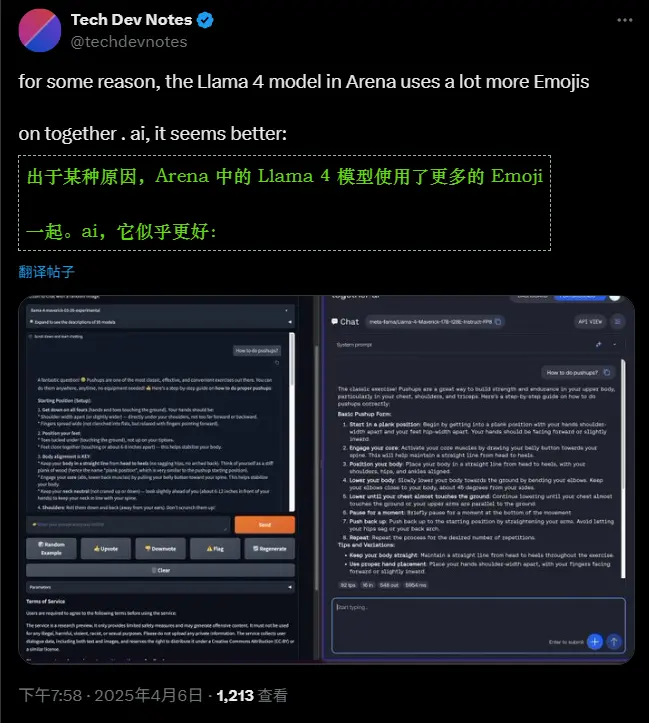
事实上,X平台上的研究人员已经观察到公开可下载的Maverick与LM Arena上托管的模型在行为上存在显著差异。例如,LM Arena版本的Maverick似乎更倾向于使用大量表情符号,并且给出的回答往往非常冗长。这种差异可能会让开发者在实际应用中感到困惑,因为他们无法确定自己所使用的模型是否与测试版本一致,以及这种不一致性会对最终结果产生何种影响。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...