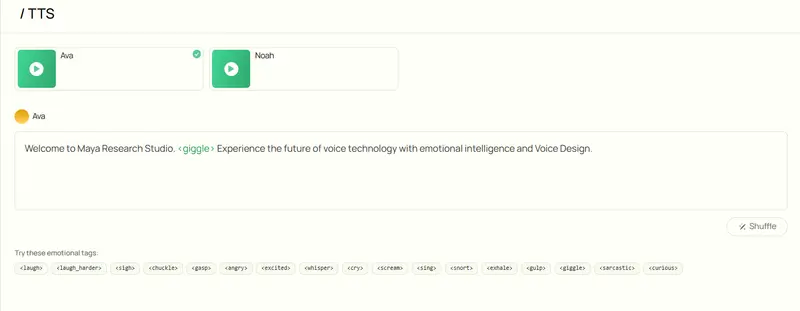
Maya1:开源 3B 语音模型,支持自然语言控制与情感标签的文本到语音生成Maya Research 近期发布了一款突破性的开源文本到语音(TTS)模型——Maya1。这款仅3B参数的模型,不仅能将文本与自然语言描述转化为富有情感的24kHz高质量语音,还支持单GPU实时运...语音模型# Maya1# 语音模型5个月前0780
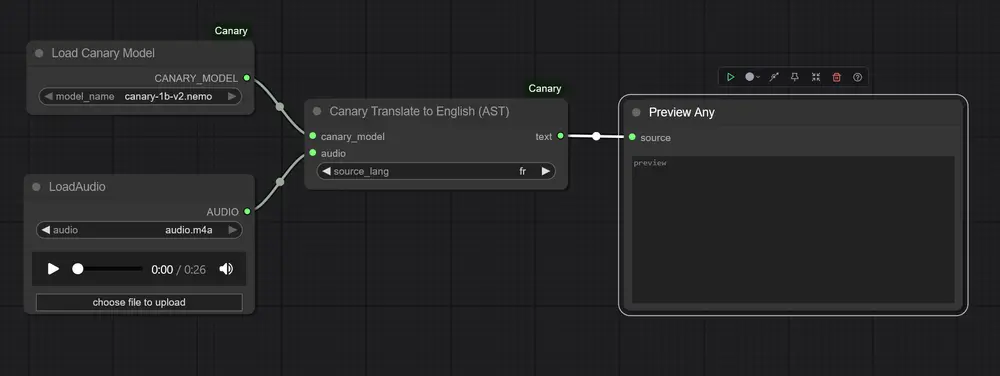
Canary-ComfyUI:在 ComfyUI 中集成英伟达Canary模型的语音识别与翻译能力英伟达推出的 Canary 是一款先进的端到端语音处理模型,支持自动语音识别(ASR)和语音翻译(AST),具备多语言识别、标点恢复和大小写规范化能力。通过社区开发的自定义节点 Canary-Comf...插件# Canary-ComfyUI# 语音模型7个月前01110
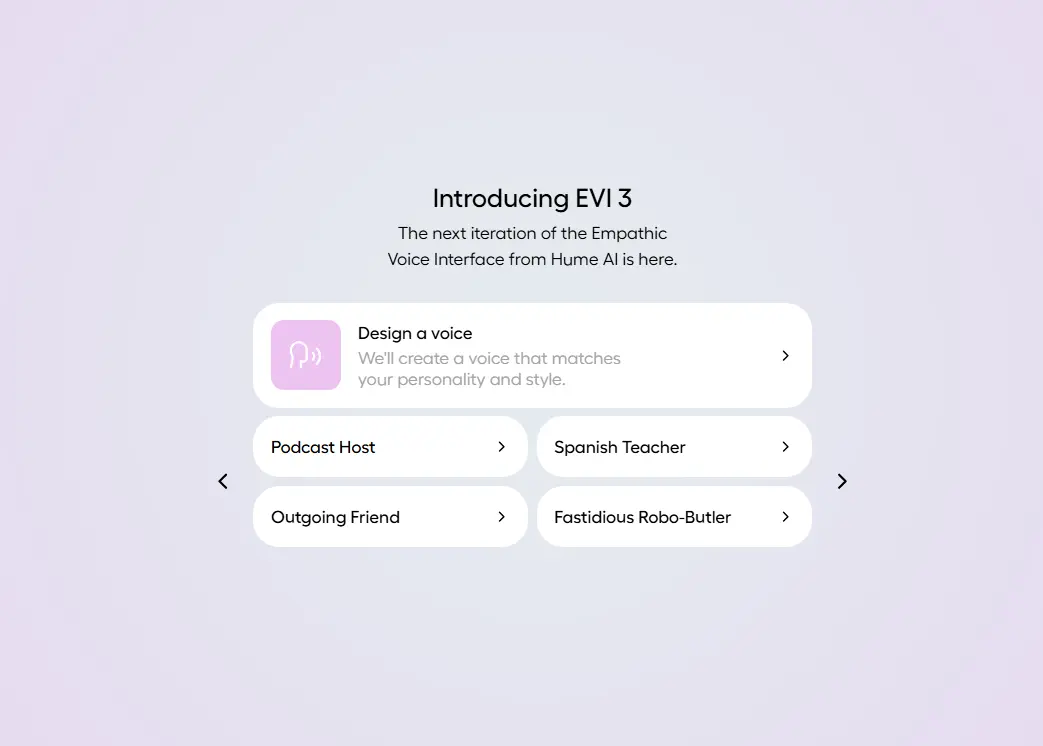
Hume 推出新一代情感语音模型 EVI 3,让 AI 更懂你的情绪总部位于纽约的情感语音AI初创公司 Hume 正式发布了其最新一代情感语音交互模型 —— EVI 3(Empathic Voice Interface)。它不仅听起来更自然、更有“人味”,还能感知用户...早报# EVI 3# Hume# 语音模型10个月前02020
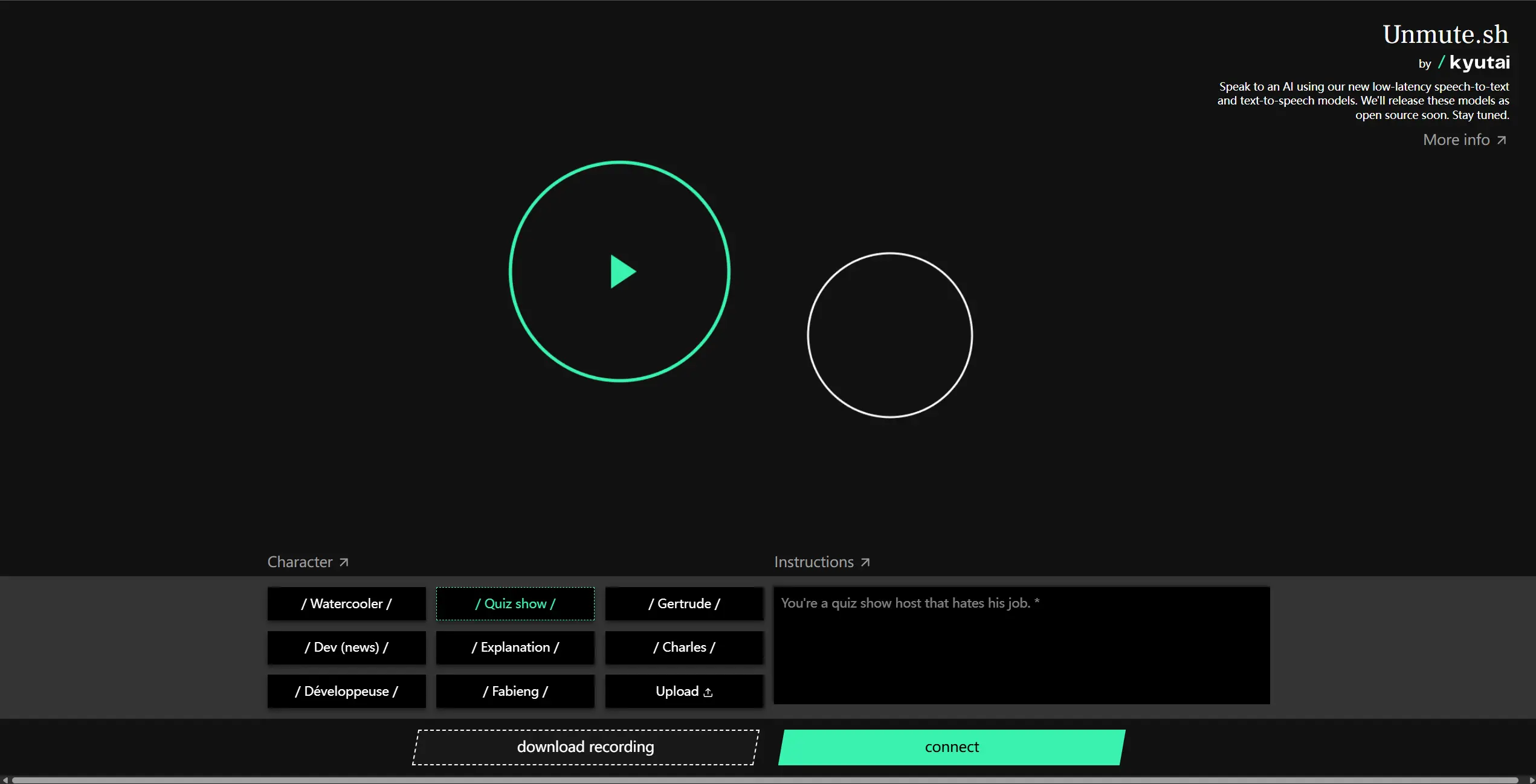
Kyutai 推出全新语音系统Unmute,让任何大模型都能“说话”Kyutai 近日发布了一款名为 Unmute 的全新语音 AI 系统。与以往语音模型不同,Unmute 并不试图替代现有的语言模型,而是作为一个高度模块化的“插件”,可以无缝接入任意文本大语言模型...语音模型# Kyutai# Unmute# 语音模型10个月前01640
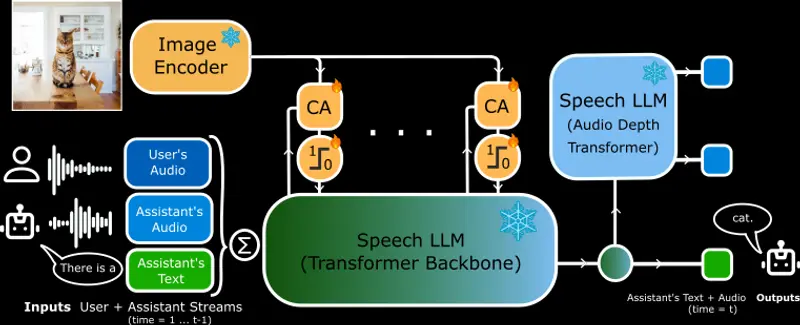
多模态语音交互的端到端大型语音模型 VITA-Audio腾讯优图实验室、南京大学和厦门大学的研究人员推出用于高效多模态语音交互的端到端大型语音模型 VITA-Audio,VITA-Audio 的目标是通过快速生成音频和文本令牌,显著降低流式语音交互中的延迟...语音模型# VITA-Audio# 语音模型11个月前02390
亚马逊发布全新AI语音模型Nova Sonic:能够原生处理语音并生成自然流畅的语音周二,亚马逊推出了一款全新的生成式AI语音模型——Nova Sonic。这款模型能够原生处理语音并生成自然流畅的语音,标志着亚马逊在AI语音技术上的重大突破。 地址:https://aws.amazo...早报# Nova Sonic# 亚马逊# 语音模型12个月前01900
Kyutai发布首个开源实时语音模型MoshiVis,开启视觉与语音交互新时代在AI领域,将实时语音交互与视觉内容相结合一直是一个极具挑战性的课题。传统系统通常依赖于多个独立组件来实现语音活动检测、语音识别、文本对话和文本转语音合成,这种分段式的方法不仅容易引入延迟,还难以捕捉...语音模型# MoshiVis# 语音模型1年前02080
谷歌将高清语音模型Chirp 3引入Vertex AI平台,并计划从下周开始正式推出在生成式AI领域,文本和图像生成一直是关注焦点。然而,随着技术的快速发展,语音AI正迅速崛起,成为下一波浪潮。谷歌在这一领域的最新进展是将高清语音模型Chirp 3集成到其Vertex AI开发平台中...早报# Chirp 3# Vertex AI# 语音模型1年前02940
拟人化实时交互系统SpeechGPT 2.0-preview:支持多种音色,200毫秒延迟复旦大学自然语言处理实验室近期推出了SpeechGPT 2.0-preview,这是他们为实现情景智能而开发的第一个拟人化实时交互系统。基于百万小时级别的语音数据训练而成,这款端到端的语音大模型不仅能...多模态模型# SpeechGPT 2.0-preview# 语音模型1年前03290