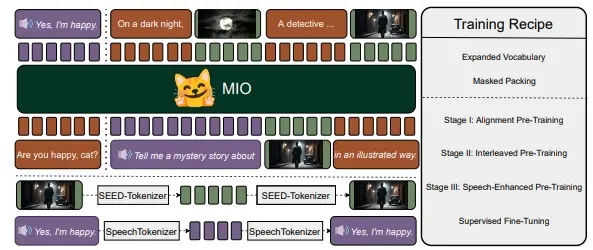
基于多模态token的新型基础模型MIO:能够以端到端、自回归的方式理解和生成语音、文本、图像和视频北京航空航天大学、01.AI、香港理工大学、AIWaves、阿尔伯塔大学、滑铁卢大学、曼彻斯特大学、中国科学院自动化研究所、北京大学和香港科技大学的研究人员推出一个基于多模态token的新型基础模型M...新技术# MIO# 多模态2年前06330
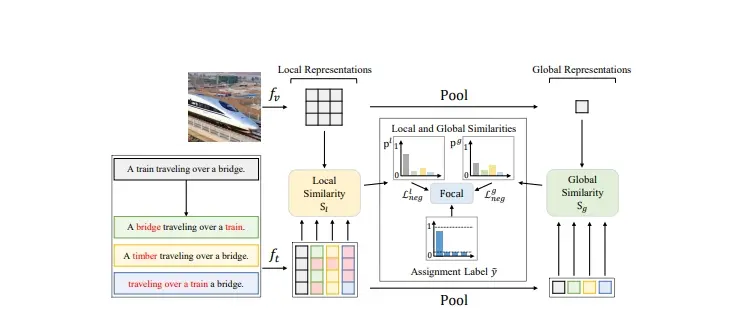
FSC-CLIP:提升预训练视觉和语言模型(VLMs)在理解图像和文字组合任务上的能力,同时保持在多模态任务上的性能韩国科学技术院、世宗大学和汉阳大学的研究人员推出FSC-CLIP,提升预训练视觉和语言模型(VLMs)在理解图像和文字组合任务上的能力,同时保持在多模态任务上的性能。简单来说,就是让计算机能够更好地理...新技术# FSC-CLIP# 多模态1年前05260
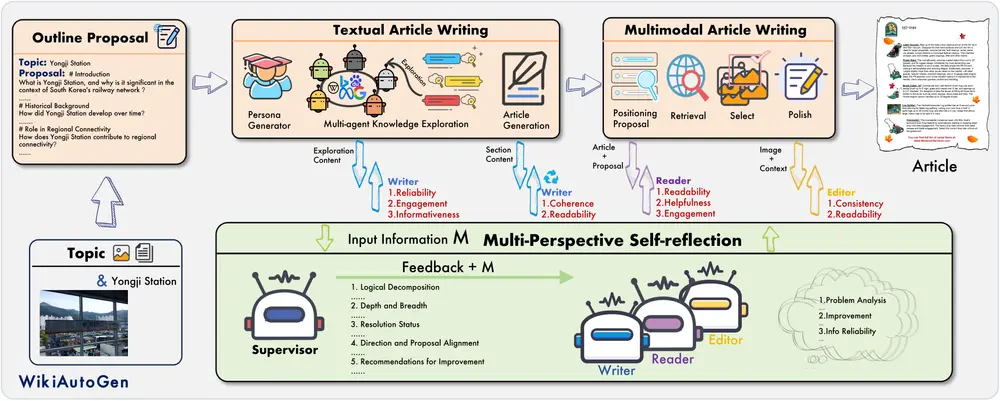
WikiAutoGen:用于自动化生成多模态维基百科风格文章的系统阿卜杜拉国王科技大学、兰州大学、悉尼大学的研究人员推出WikiAutoGen,这是一个用于自动化生成多模态维基百科风格文章的系统。它通过整合文本和图像信息,生成高质量、多模态的维基百科风格文章,同时引...新技术# WikiAutoGen# 多模态# 维基百科1年前05130
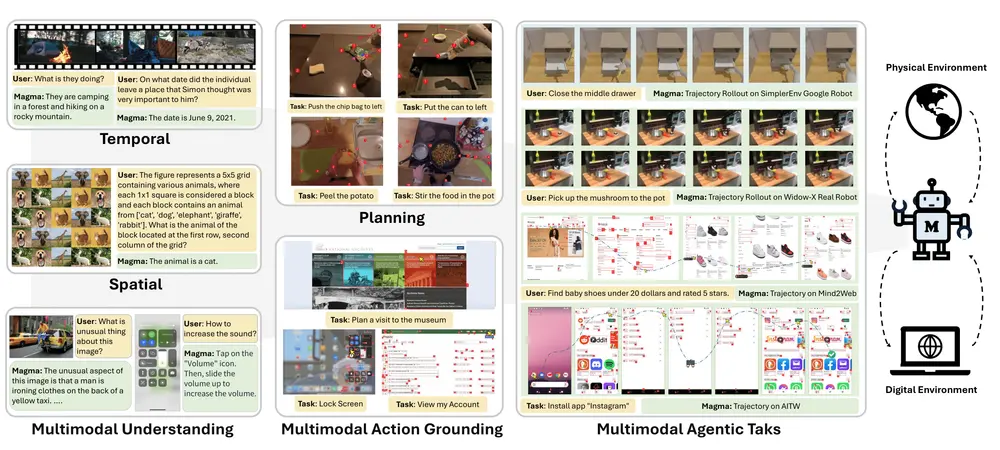
微软研究院推出的多模态 AI 代理基础模型MagmaMagma 是由微软研究院推出的一款面向多模态AI代理的基础模型,为一系列智能任务提供强大的支持。它不仅具备视觉-语言(VL)模型的理解能力(即语言智能),还拥有在视觉空间世界中规划和执行动作的能力...多模态模型# Magma# 多模态# 微软研究院1年前03440
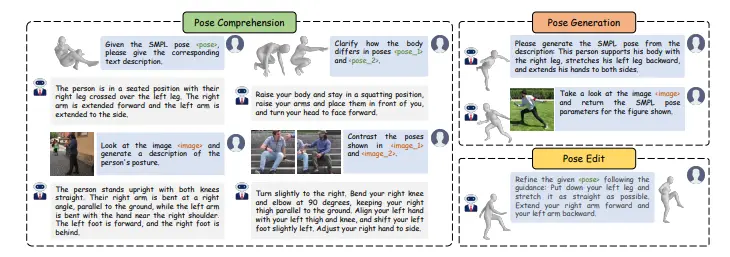
统一多模态框架UniPose:用于理解、生成和编辑人体姿态中国科学院计算技术研究所和中国科学院大学的研究人员推出统一多模态框架UniPose,它用于理解、生成和编辑人体姿态。UniPose利用大语言模型(LLMs)来处理包括图像、文本和3D SMPL姿态在内...新技术# UniPose# 人体姿态# 多模态1年前03320
谷歌Gemini 2.0 Flash重磅升级:原生多模态生成,图像编辑进入对话时代谷歌在昨天除了发布了开源模型Gemma 3,还正式开放了Gemini 2.0 Flash的原生图像生成编辑功能,这款实验性模型凭借单模型多模态生成能力,正在重塑AI创作逻辑。相比传统需要「语言模型+扩...多模态模型# Gemini 2.0 Flash# gemini-2.0-flash-exp# Gemma 31年前02810
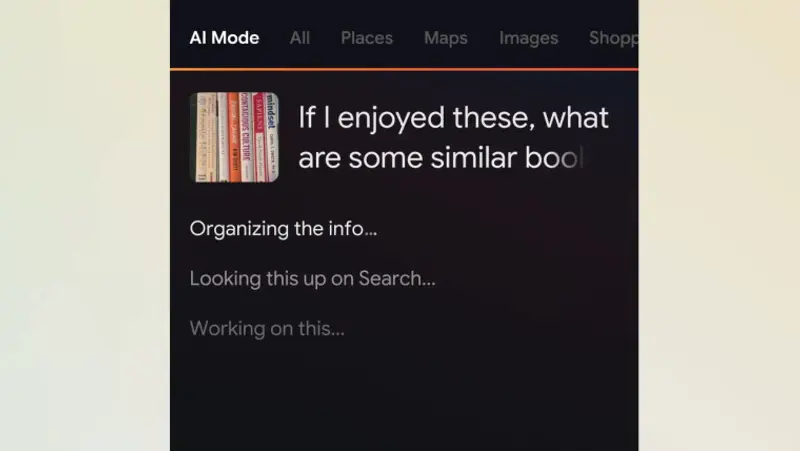
让搜索更智能!Google Search AI Mode获得多模态搜索支持谷歌一直以来都在不断探索和改进搜索功能,以提供更智能、更便捷的用户体验。最近,谷歌为其 Google Search AI Mode 功能增加了多模态搜索支持,使该功能能够处理更多数据类型,进一步提升了...早报# Google Search AI Mode# 多模态12个月前02350
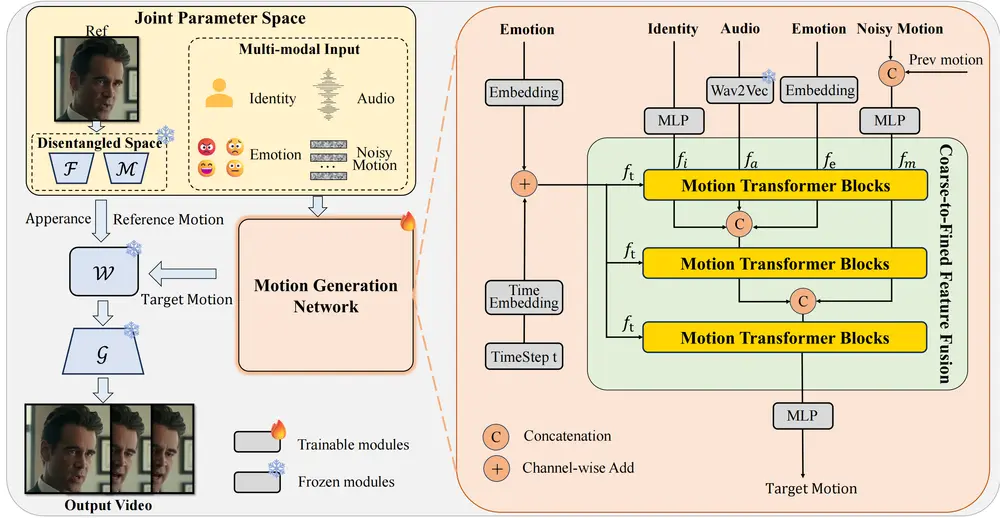
多模态扩散架构MoDA:用于生成具有任意身份和语音音频的“会说话的头像”阿里达摩院、浙江大学、湖畔实验室的研究人员推出多模态扩散架构MoDA,用于生成具有任意身份和语音音频的“会说话的头像”(talking head)。 项目主页:https://lixinyyang.g...视频模型# MoDA# 多模态8个月前01190