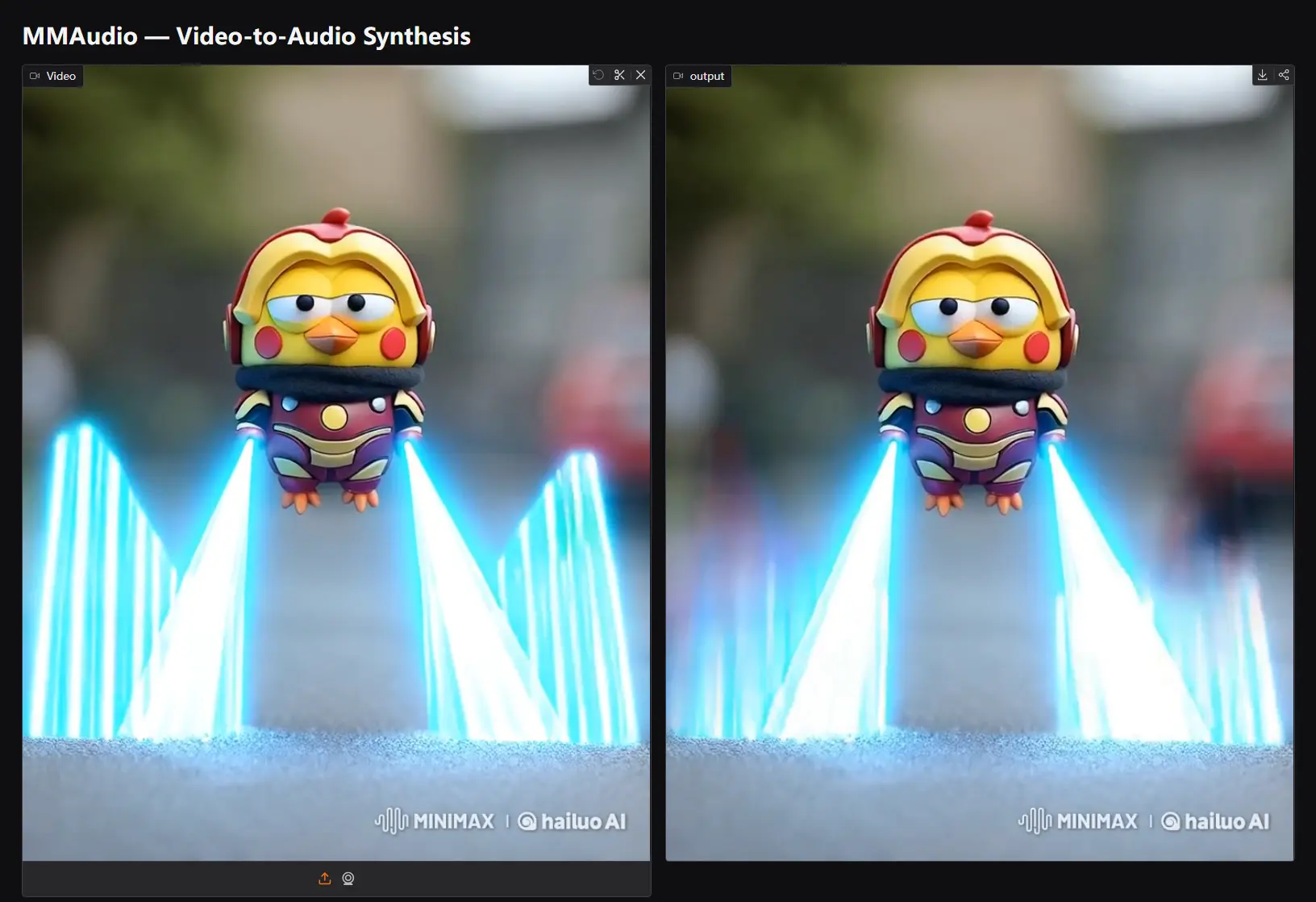
MMAudio:基于多模态联合训练的同步音频生成系统近年来,多模态生成模型在图像、视频和文本等领域取得了显著进展,但将视觉和文本信息与音频生成结合的任务仍然具有挑战性。传统的音频生成方法通常依赖于单一模态(如仅基于文本或仅基于视频),难以实现高质量的音...语音模型# MMAudio# 音频生成1年前03110
阿里巴巴语音实验室发布开源语音处理框架 ClearerVoice-Studio:支持语音增强、分离和目标说话人提取在当今的音频环境中,清晰沟通面临诸多挑战。背景噪音、重叠对话以及音频和视频信号的混合等因素常常破坏了沟通的清晰度和理解力。这些问题不仅影响个人通话,还波及专业会议和内容制作等场景。尽管音频技术有所进步...语音模型# ClearerVoice-Studio# 阿里巴巴1年前03290
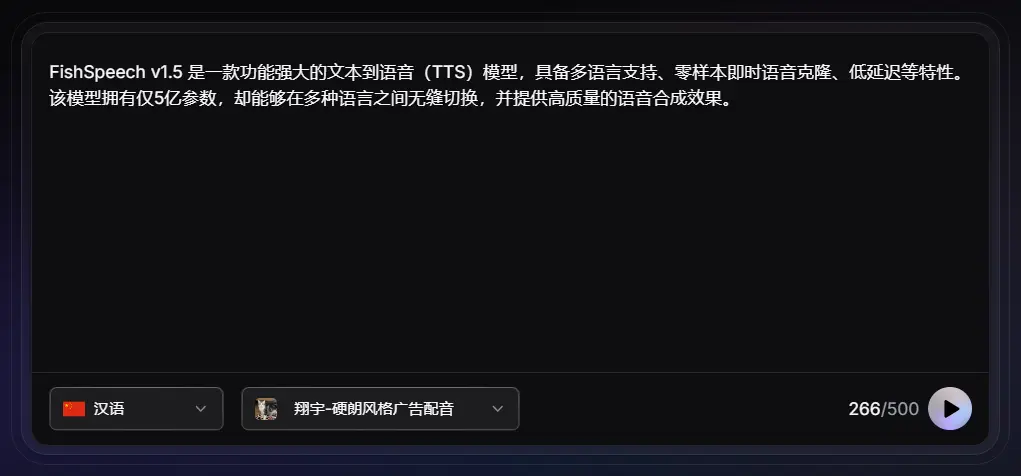
TTS模型FishSpeech推出v1.5 版本:具备多语言支持、零样本即时语音克隆、低延迟等特性FishSpeech v1.5 是一款功能强大的文本到语音(TTS)模型,具备多语言支持、零样本即时语音克隆、低延迟等特性。该模型拥有仅5亿参数,却能够在多种语言之间无缝切换,并提供高质量的语音合成效...语音模型# FishSpeech v1.5# TTS模型1年前04950
aiOla发布了集成命名实体识别(NER)和自动语音识别(ASR)的新型模型WhisperNER语音识别技术在过去几年取得了显著进展,AI的进步大大提高了其可访问性和准确性。然而,该技术仍面临一些挑战,特别是在理解和转录人名、地点和特定术语等口语实体方面。这些挑战不仅在于准确地将语音转换为文本...语音模型# aiOla# WhisperNER# 自动语音识别1年前03490
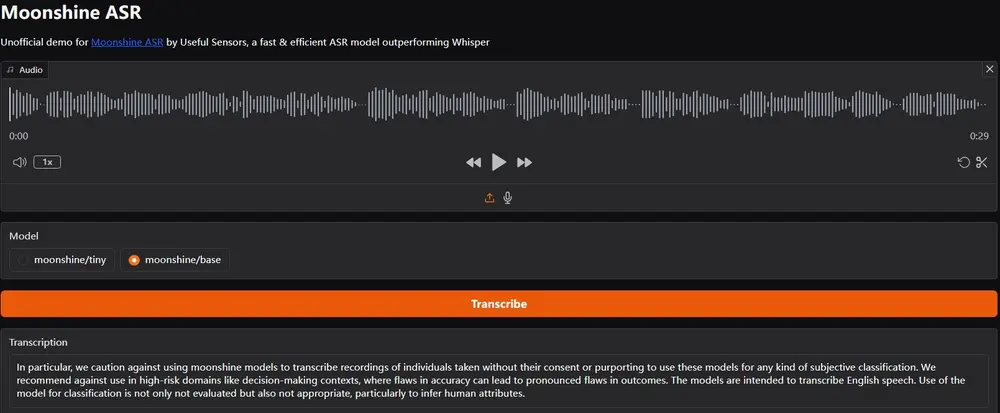
Useful开源自动语音识别 (ASR) 模型Moonshine:专门针对实时转录和语音命令处理进行了优化Useful开源了一款名为 Moonshine 的全新语音转文本模型。这款模型不仅在速度和效率上超越了目前最领先的 OpenAI 的 Whisper 模型,而且在准确率方面也达到了同等水平甚至更优。M...语音模型# Moonshine# 语音识别模型1年前07350
Rev推出开源自动语音识别模型Reverb和话者分离模型Rev 最近宣布开源其尖端的 Reverb 自动语音识别 (ASR) 和话者分离模型。经过 200,000 小时高质量人工转录的英语语音训练,Reverb 在长篇语音识别领域中表现出色,超越了所有现有...语音模型# Reverb# 话者分离模型# 语音识别模型1年前08090
OpenAI 推出更快的语音转录模型Whisper large-v3-turbo,不牺牲质量、速度提升8 倍在10月1日的DevDay活动中,OpenAI宣布了一项重大更新:推出了Whisper large-v3-turbo语音转录模型。这款新模型在保持质量几乎不变的前提下,处理速度比之前的large-v3...语音模型# OpenAI# Whisper large-v3-turbo# 语音转录模型1年前06880