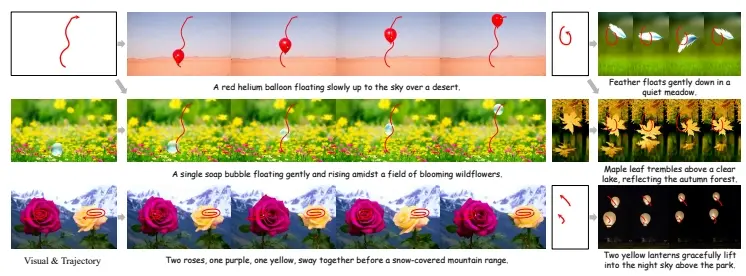
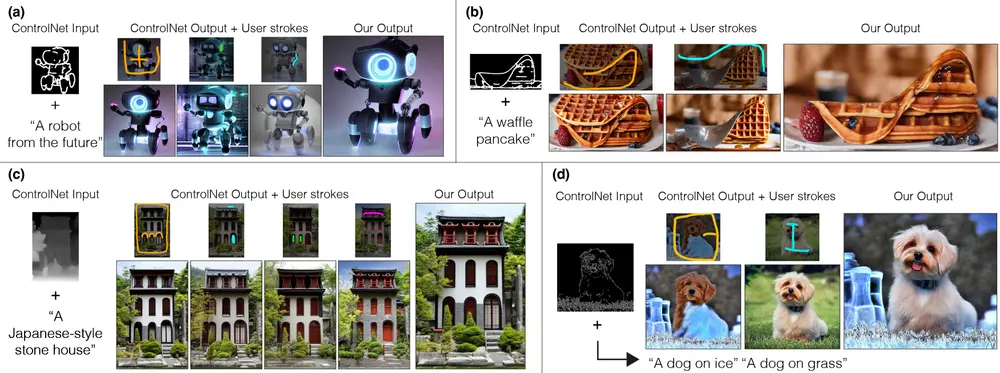
强大且高效的图像和视频生成控制方法ControlNeXt:同时支持图像和视频,并能整合多种形式的控制信息
香港中文大学和思谋科技的研究人员推出强大且高效的图像和视频生成控制方法Control...
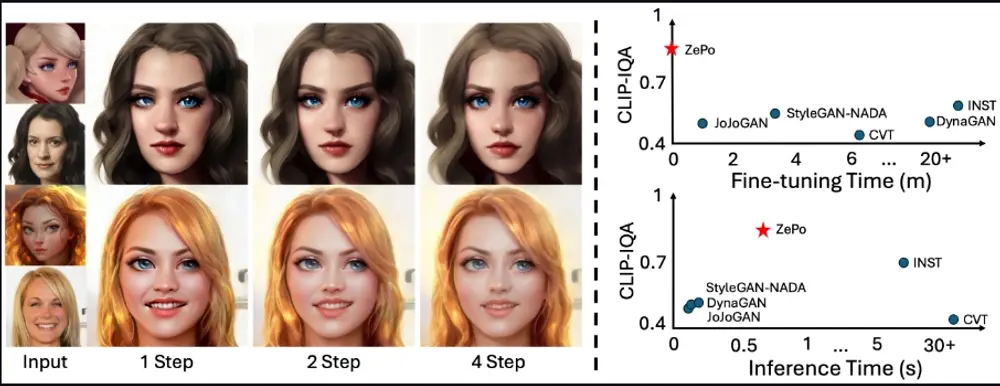
基于扩散模型的无需反转的人像风格化框架ZePo:在无需任何模型微调的情况下,快速生成具有特定艺术风格的肖像图像
上海科技大学信息科学技术学院和中国科学院自动化研究所的研究人员推出了一种基于...
创新框架Generative Photomontage:通过组合多个生成的图像来创建他们所需的图像
卡内基梅隆大学和赖希曼大学的研究人员推出创新框架Generative Photomontage,它使...
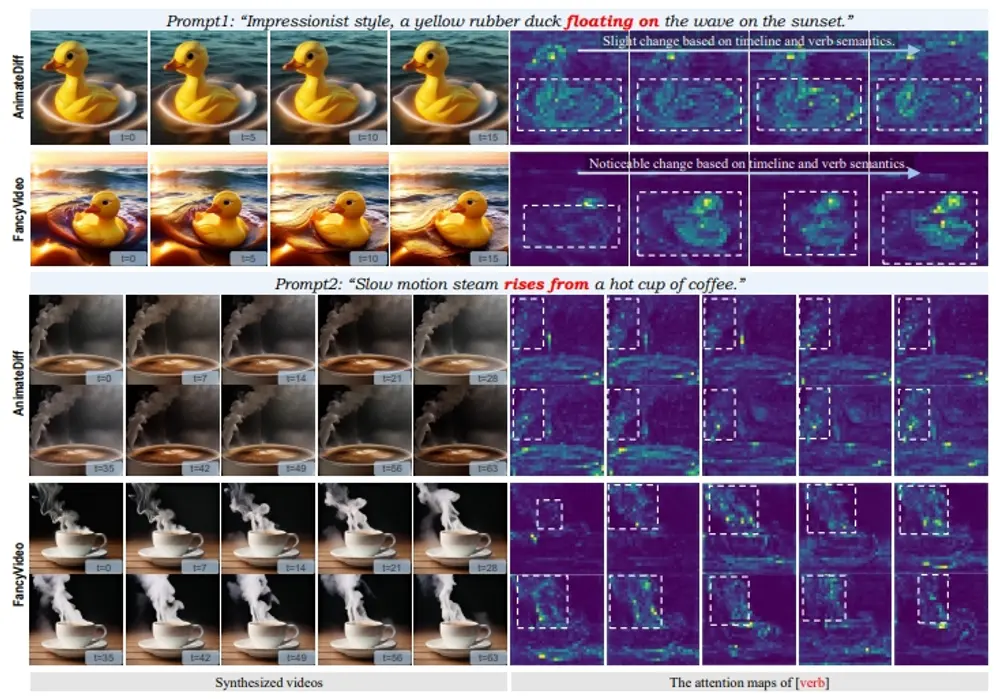
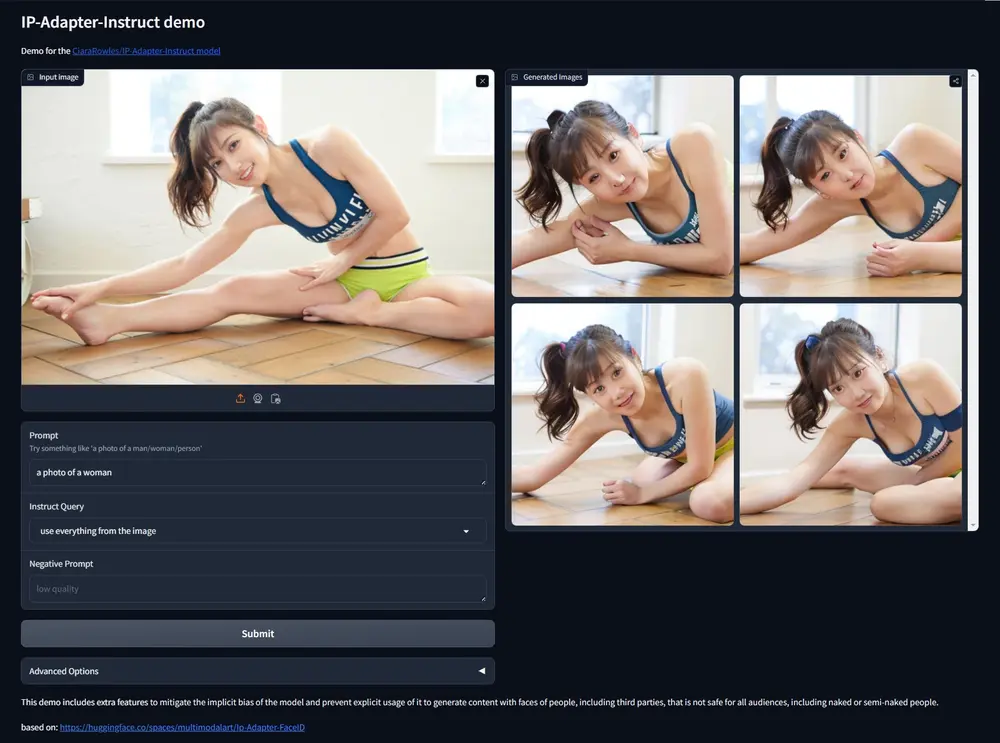
IPAdapter-Instruct:在处理基于图像的条件化时,能够更精确地理解用户的意图
Unity推出IPAdapter-Instruct,它是一种用于图像生成的新技术,特别是在处理基于图...

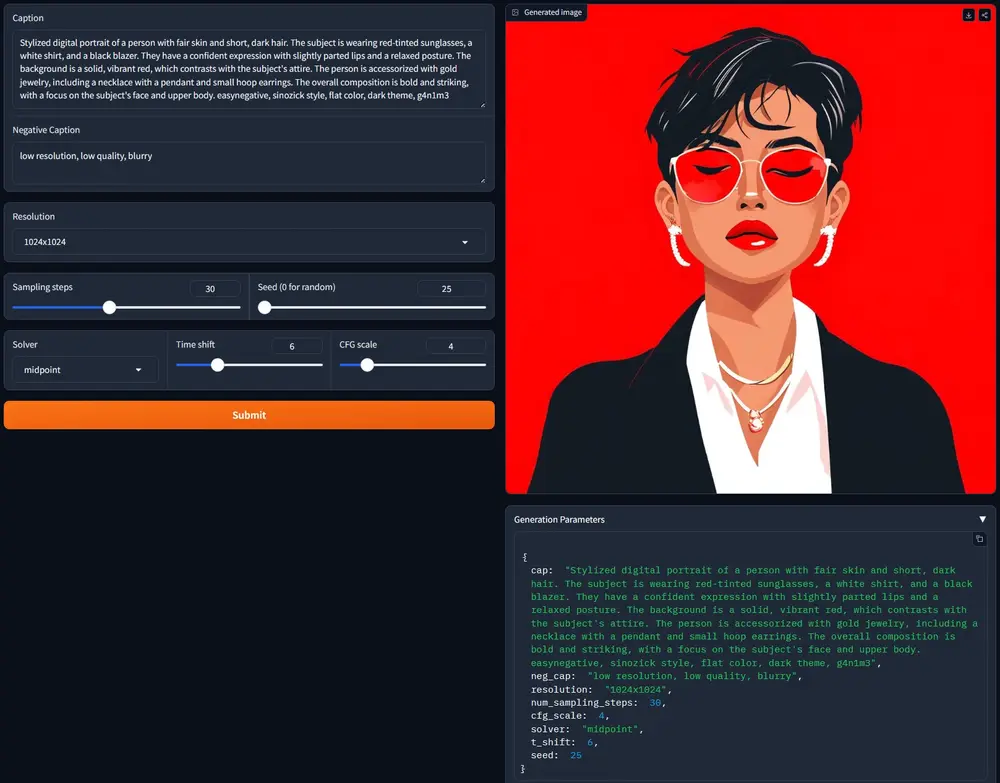
新型多模态自回归模型Lumina-mGPT:能够执行各种视觉和语言任务,尤其擅长根据文本描述生成逼真的图片
上海人工智能实验室和香港中文大学的研究人员推出新型多模态自回归模型Lumina-mGPT...
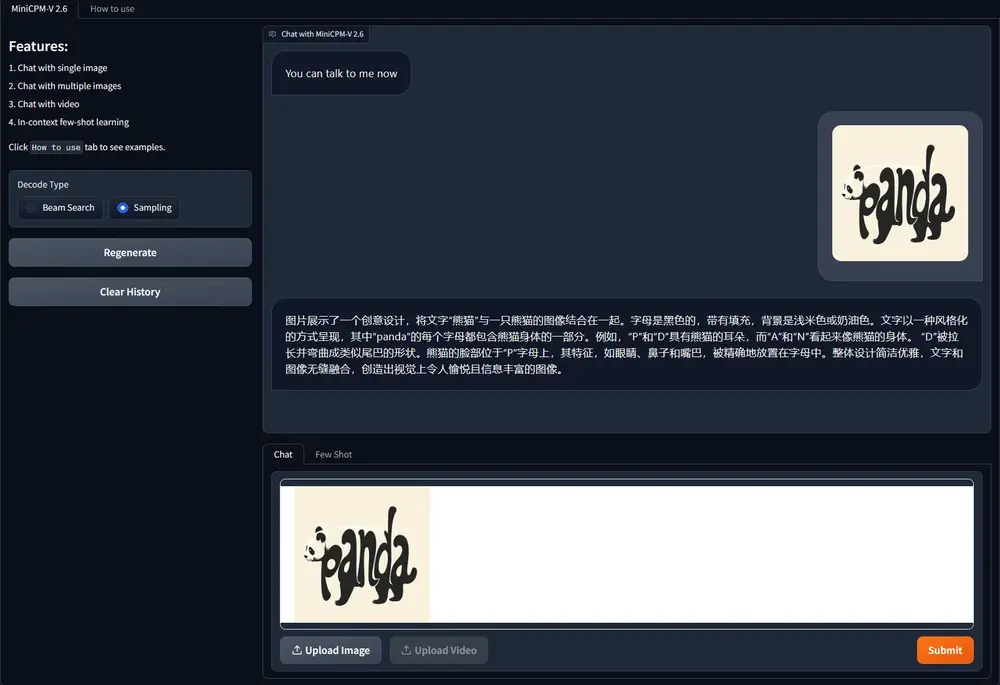
面壁智能推出开源多模态大语言模型MiniCPM-V 2.6:可以在手机上运行与GPT-4V水平相当的任务
面壁智能昨日开源了 MiniCPM-V 2.6 模型,官方表示将端侧 AI 多模态能力拉升至全面...
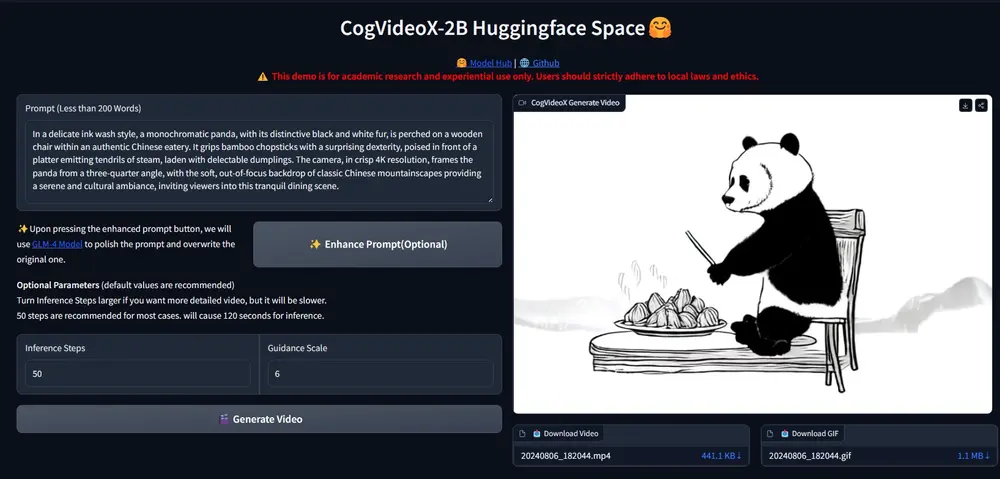
智谱AI推出视频生成模型CogVideoX:与“清影”同源,单张 4090 显卡可推理
智谱 AI推出与“清影”同源的视频生成模型 —CogVideoX,CogVideoX模型包含多个不同尺...