
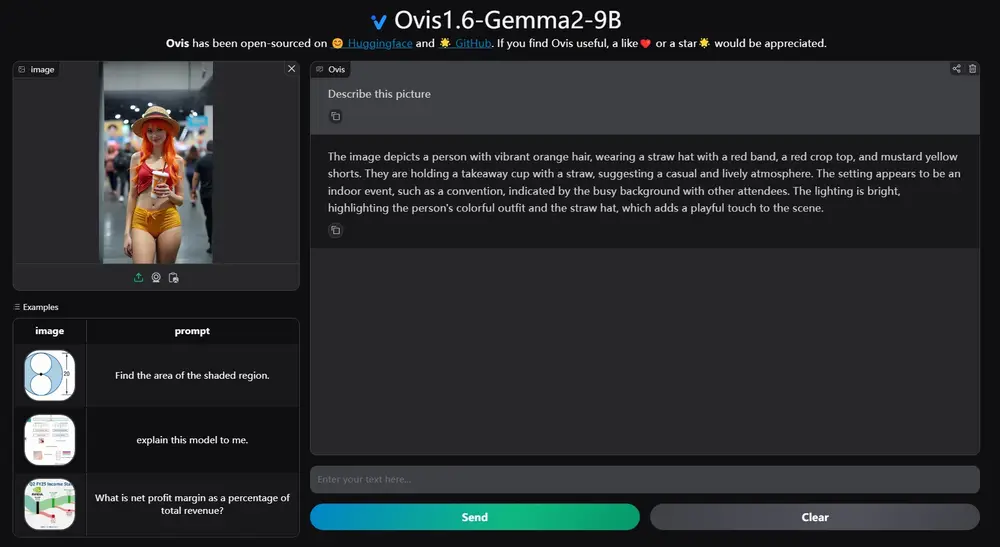
阿里国际推出多模态大语言模型 Ovis1.6-Gemma2-9B:能够同时处理和理解文本和视觉信息
Ovis1.6-Gemma2-9B是阿里国际推出的一款多模态大语言模型,Ovis是一种新颖的多模...

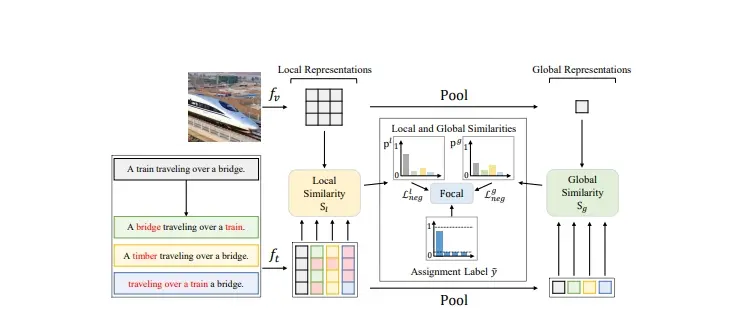
FSC-CLIP:提升预训练视觉和语言模型(VLMs)在理解图像和文字组合任务上的能力,同时保持在多模态任务上的性能
韩国科学技术院、世宗大学和汉阳大学的研究人员推出FSC-CLIP,提升预训练视觉和语...

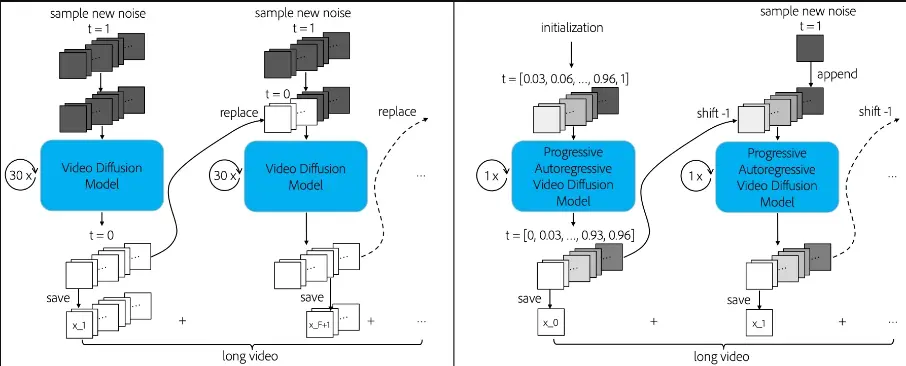

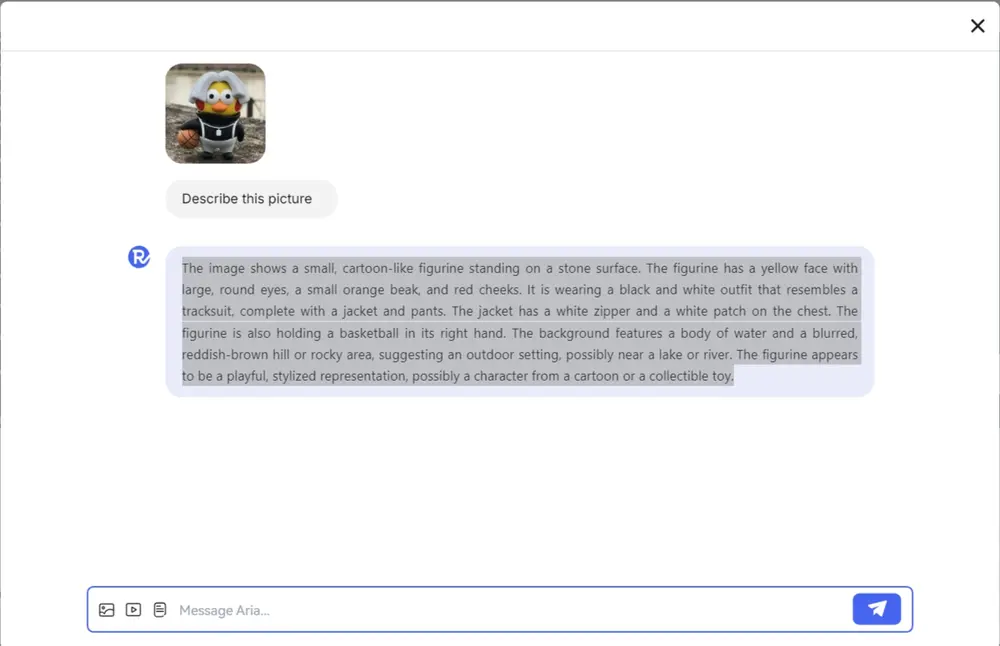
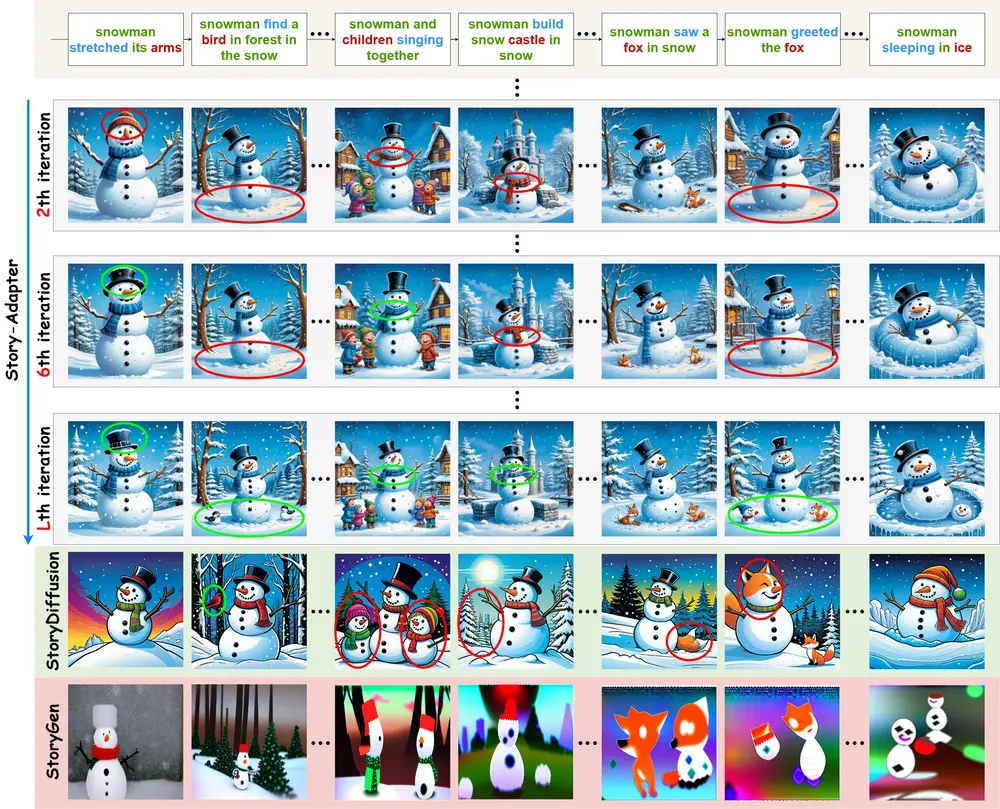
用于长篇故事视觉化的迭代框架Story-Adapter:根据长篇故事的文字描述生成一系列既连贯又具有丰富细节的图像
加州大学圣克鲁斯分校、杭州电子科技大学和新加坡理工学院的研究人员推出一个用于...



视频插值方法ViBiDSampler:专门用于在两个关键帧之间生成平滑且逼真的中间帧,从而创建流畅的视频过渡效果
韩国科学技术研究院推出视频插值方法ViBiDSampler,这种方法专门用于在两个关键帧...